Downloaded 28 times

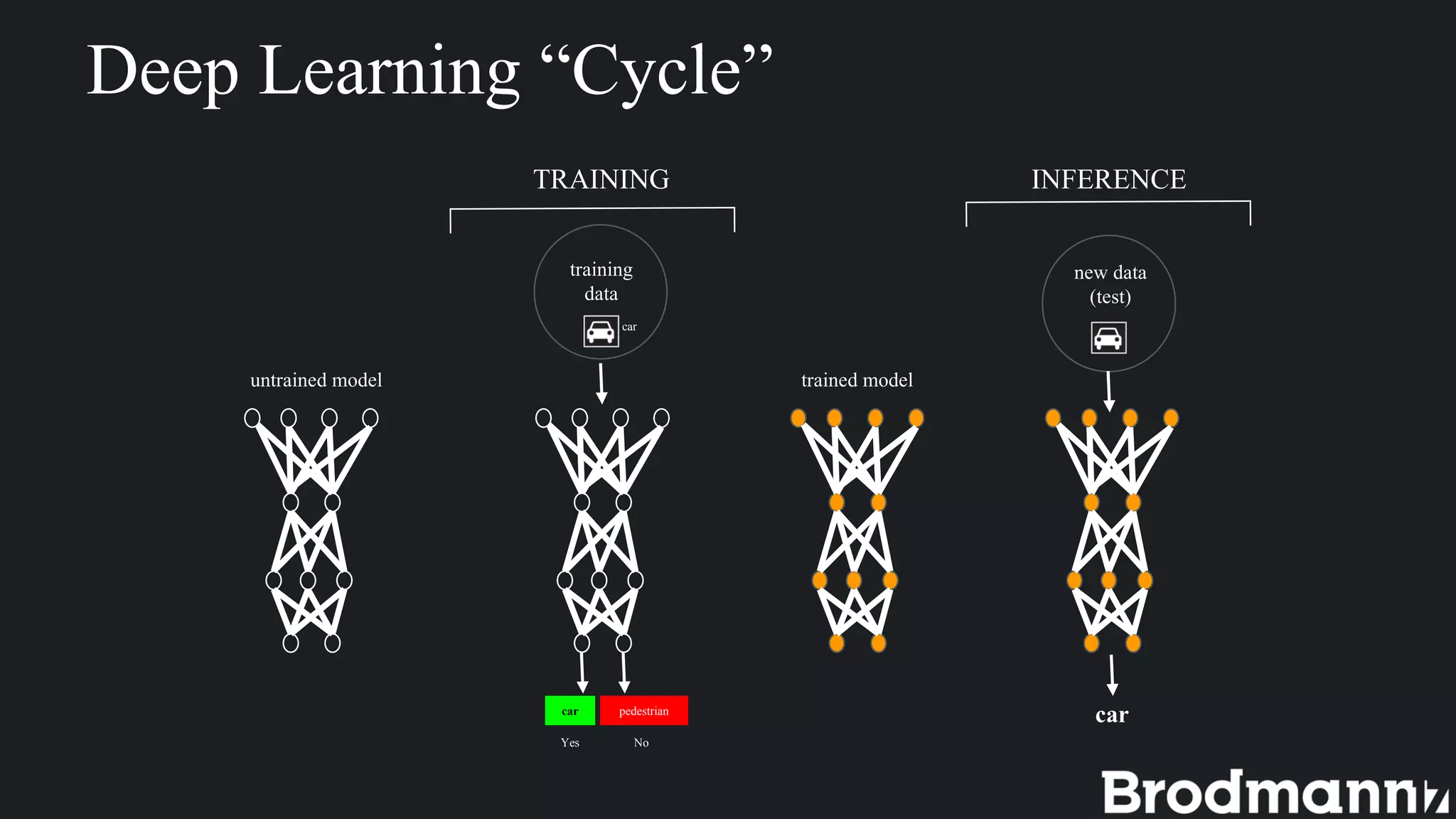


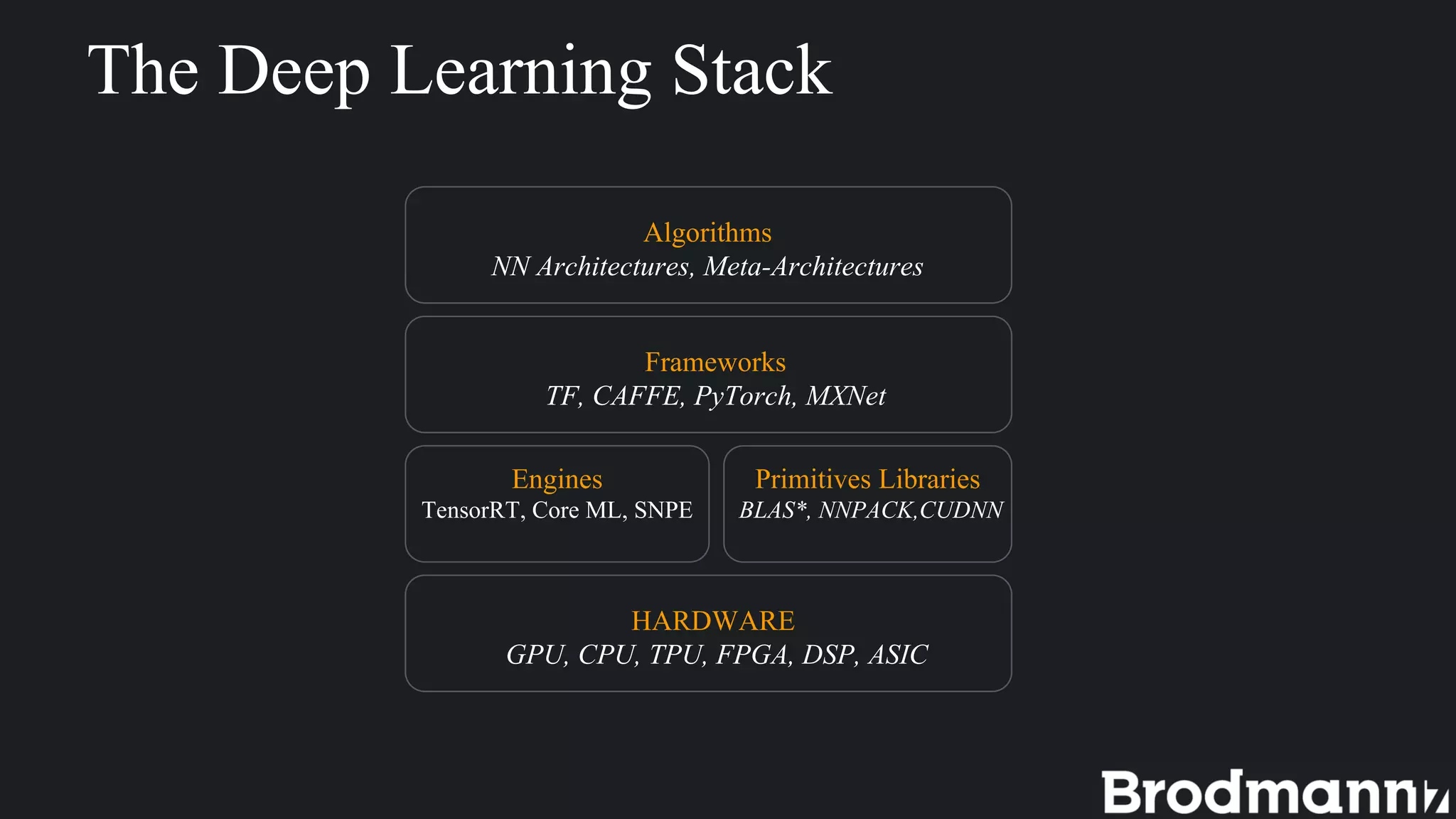





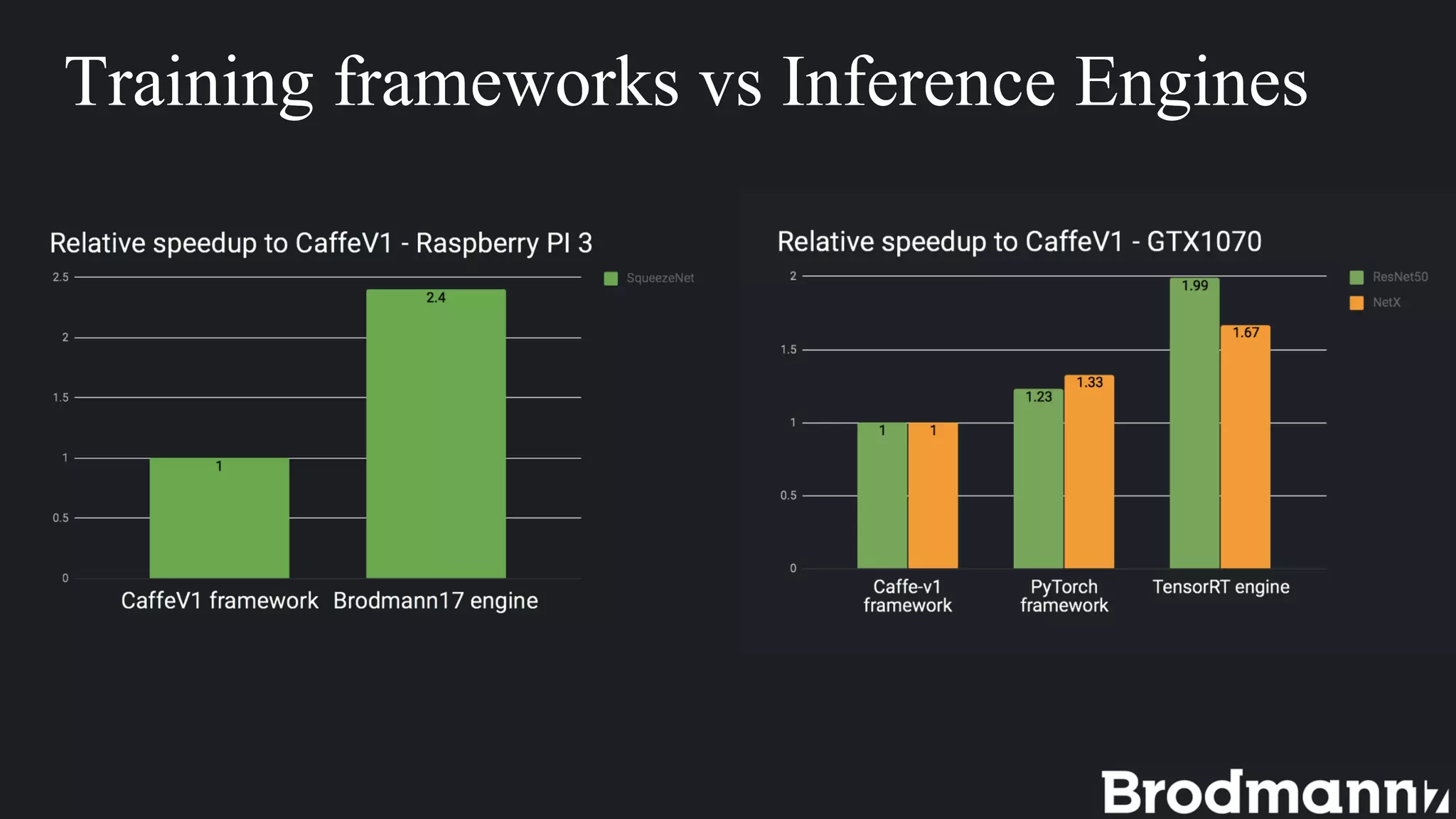

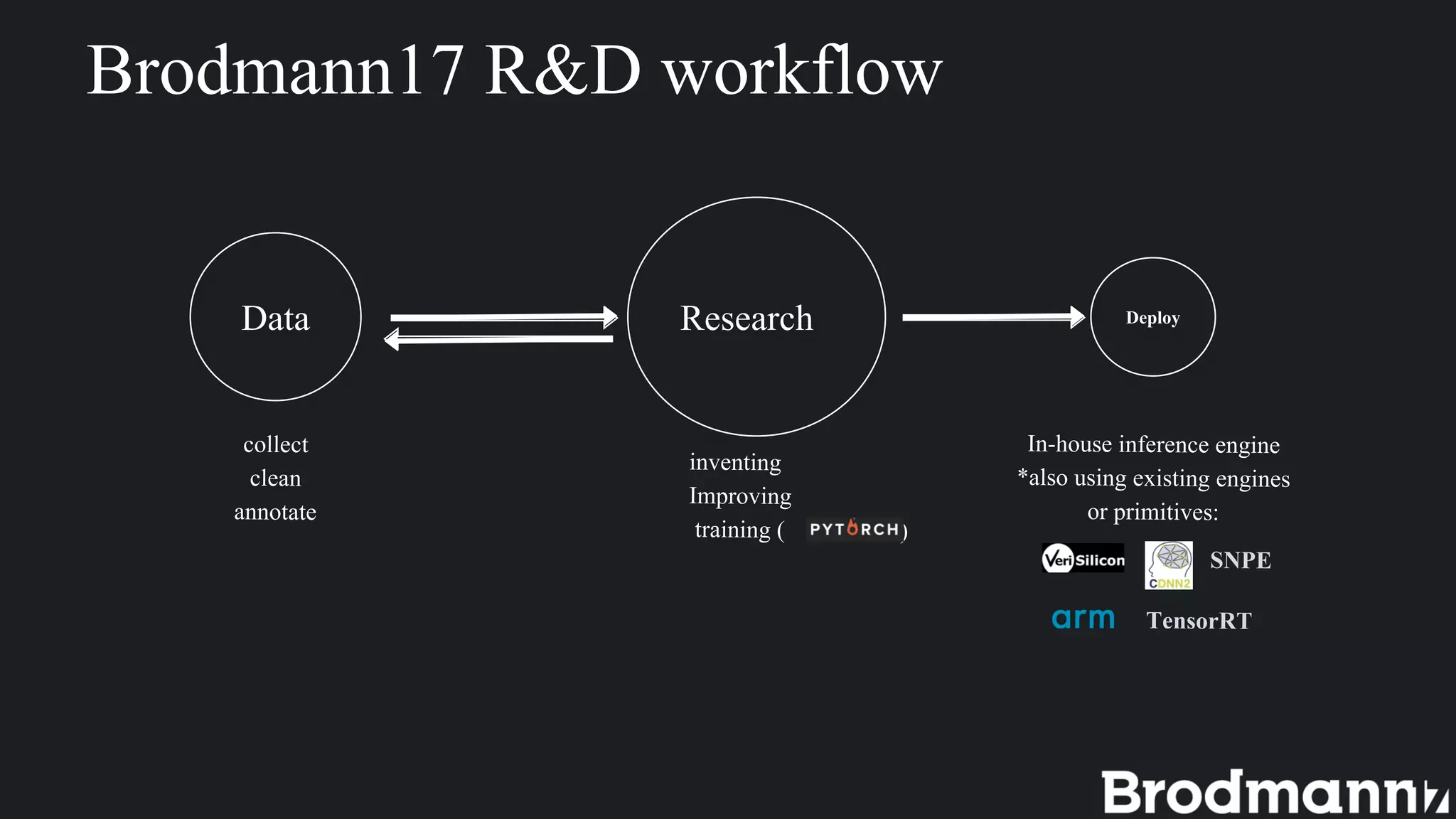



1. Deep learning inference on edge devices has challenges due to low hardware resources but can provide benefits like low latency and privacy. 2. To run neural networks on edge devices efficiently, accuracy must often be sacrificed by reducing input/model size, bit precision, or using less accurate algorithms. 3. Brodmann17 focuses on efficient algorithms to support more AI on any processor while maintaining accuracy for edge device applications with low-power processors. 4. Choosing an inference engine or building your own involves tradeoffs between flexibility, speed to production, and control over the environment. 5. Brodmann17 provides examples of edge applications in IoT, smart cities, and autonomous driving.










































































