Downloaded 21 times














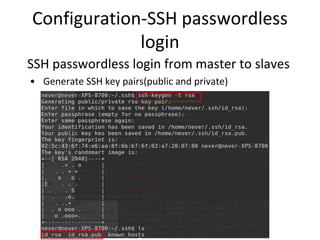





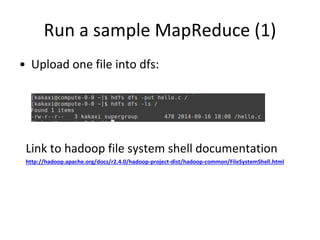



This document provides instructions for installing Hadoop on a cluster. It outlines prerequisites like having multiple Linux machines with Java installed and SSH configured. The steps include downloading and unpacking Hadoop, configuring environment variables and configuration files, formatting the namenode, starting HDFS and Yarn processes, and running a sample MapReduce job to test the installation.

































































