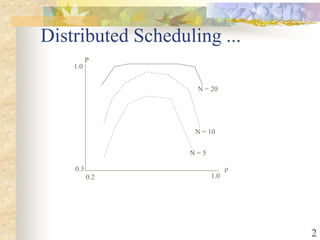
The document discusses distributed scheduling in systems with mixed workloads, highlighting the importance of task migration for load balancing and sharing. It outlines various algorithms for load distribution, including static, dynamic, and adaptive approaches, and compares their effectiveness based on system load conditions. The text also addresses the complexities of task transfers, state management, and the impact of polling mechanisms on system stability.