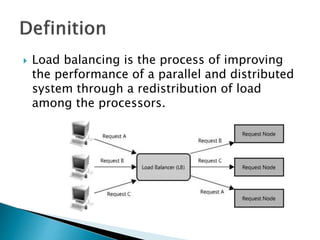
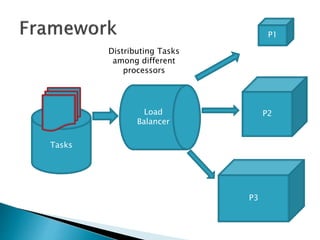
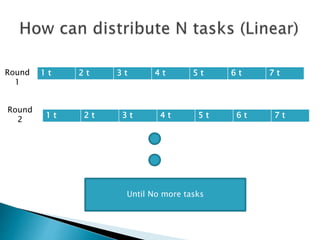
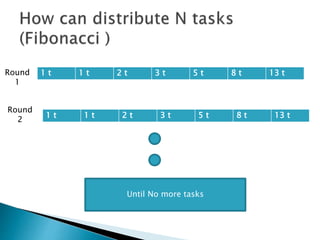
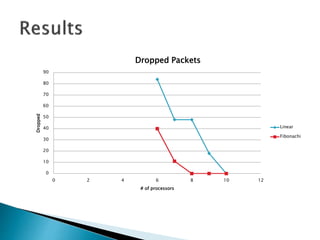
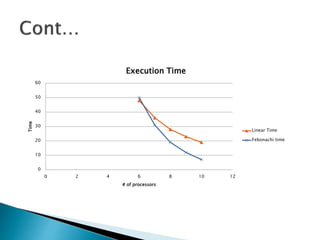
The document discusses load balancing techniques in distributed systems. It explains static and dynamic load balancing algorithms such as round robin, random, central manager, and threshold algorithms. Genetic algorithms and their application to load balancing problems are also covered. The performance of different load balancing strategies is evaluated based on metrics like execution time, dropped packets, and processor utilization. Specifically, the document finds that distributing load based on processor capabilities using a Fibonacci weighting scheme can maximize utilization of high-capability processors and minimize load on low-capability processors.