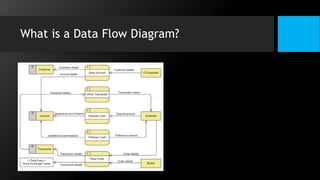
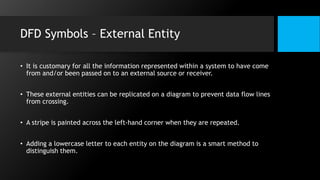
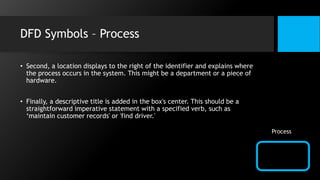
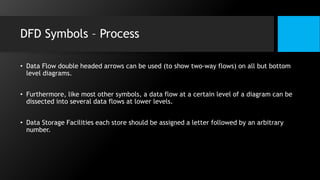
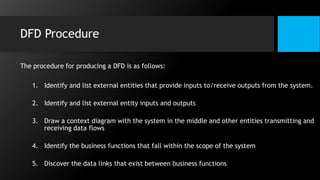
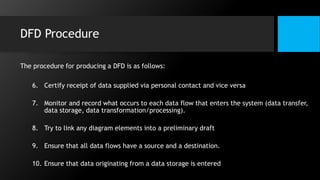
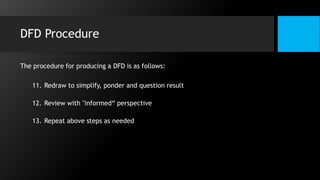
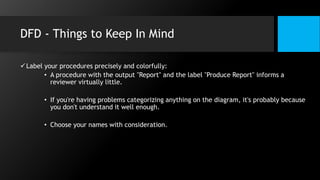
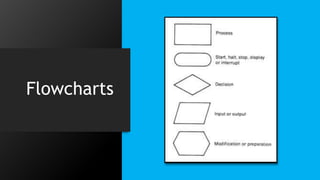
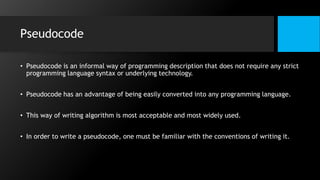
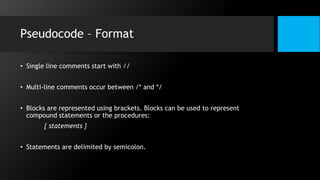
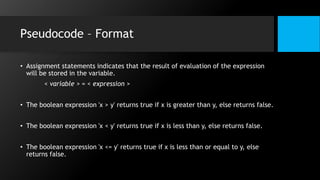
This document discusses data flow diagrams (DFDs) and algorithms for problem solving. It defines a DFD as a graphical depiction of how data moves through an information system using common symbols like processes, external entities, data flows, and data stores. The purpose of a DFD is to create a model of a system that is easy to understand. It then outlines the typical procedure for producing a DFD, including identifying system boundaries, functions, and data links. The document also discusses important considerations for DFDs like precisely labeling processes and focusing on logical data flows rather than physical implementation details. Finally, it provides a brief introduction to problem solving algorithms as step-by-step methods for achieving a desired result.
































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








