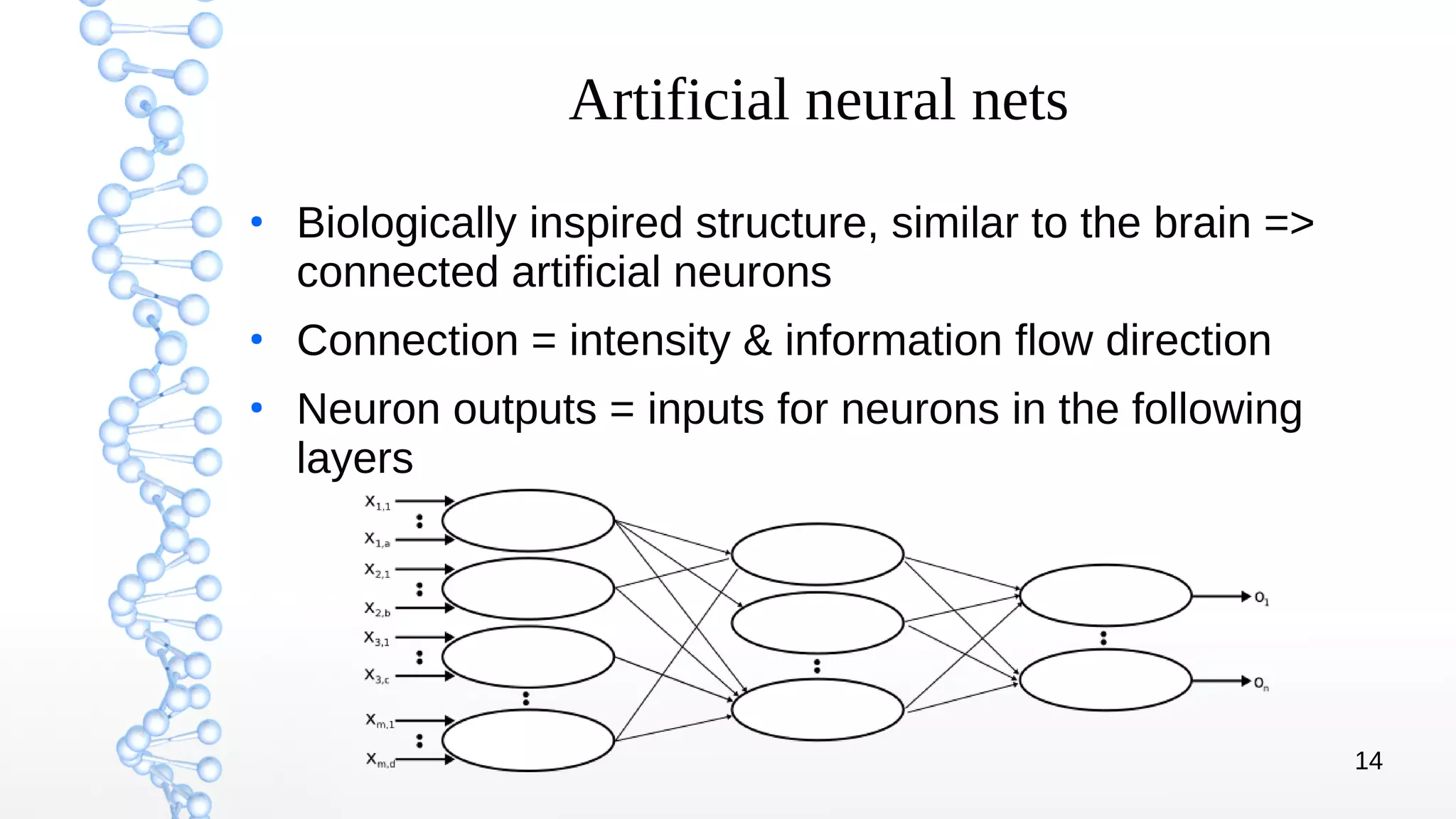
The document presents an introduction to deep learning, covering its theoretical concepts, frameworks, and applications in various fields such as robotics and computer vision. It details the evolution of deep learning techniques, the structure of artificial neural networks, and essential processes like backpropagation and gradient descent. The document also addresses artificial neuron types, learning processes, and the significance of convolutional neural networks for image processing.






![12
The linear perceptron
●
A simple learning model:
–
A mathematical function h(x, θ)
–
x = model input vector
–
θ = internal parameters vector
●
Example: an exam result guess model => above/below
average exam result – based on sleep hours and study
hours
h(x ,θ)=
{
−1,x
T
⋅
[θ 1
θ 2]+θ 0<0
1,xT
⋅
[θ 1
θ 2
]+θ 0≥0
x=[x1, x2]T
θ=[θ 1,θ 2,θ 0]T
x1
– sleep hours
x2
– study hours](https://image.slidesharecdn.com/endeeplearninguoradea-parti-16jan2018-180118134417/75/Deep-learning-University-of-Oradea-part-I-16-Jan-2018-12-2048.jpg)






![23
Gradient descent
●
Assume 2 weights: w1 and w2 => XY plane made of
[w1, w2] pairs
●
Z axis: error value at [w1, w2] coordinates =>
somewhere on the graph surface
●
Need to descend on the slope towards a minimum point
●
Steepest curve = perpendicular line to level ellipse =>
descend on the gradient of the error function
Δ wk=−ϵ
∂ E
∂wk
=...=∑
i
ϵ xk
(i)
(t
(i)
− y
(i)
)
ϵ = learning rate xk(i) = k-th input of i-th sample
i = i-th sample t(i),y(i) = desired outcome / actual output](https://image.slidesharecdn.com/endeeplearninguoradea-parti-16jan2018-180118134417/75/Deep-learning-University-of-Oradea-part-I-16-Jan-2018-23-2048.jpg)







































































