Download as PDF, PPTX











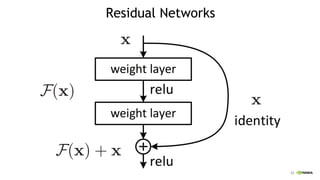

![25
Capsules & routing with EM, Hinton et al
https://arxiv.org/pdf/1710.09829.pdf [NIPS2017]
SegCaps: capsules for object segmentation https://arxiv.org/pdf/1804.04241.pdf University of Central Florida](https://image.slidesharecdn.com/nvinfiniteconf-180705133710/85/NVIDIA-Infinite-Conference-London-25-320.jpg)
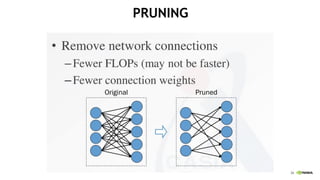
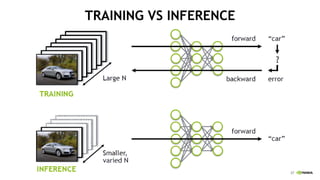
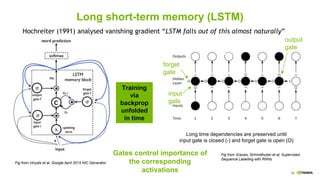


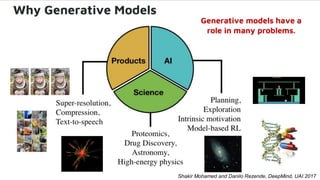
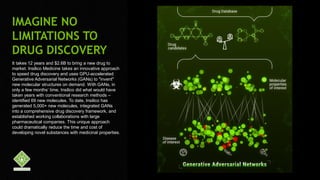







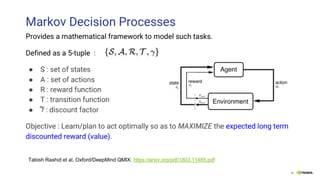

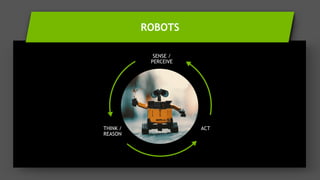









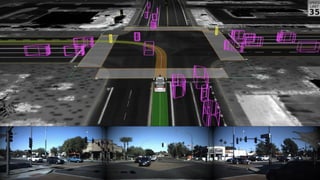











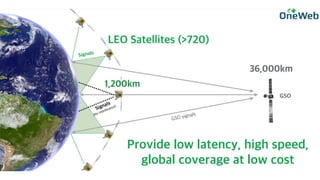



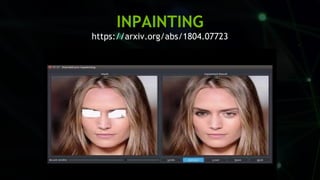

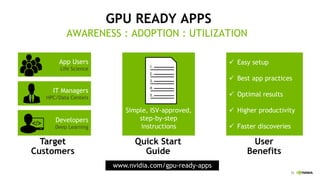

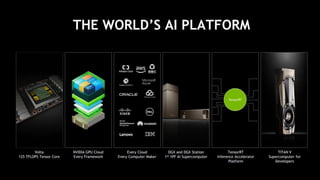



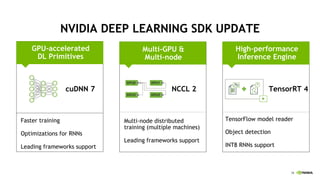

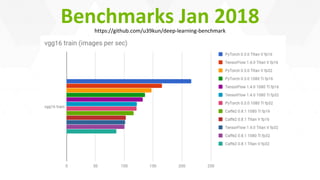


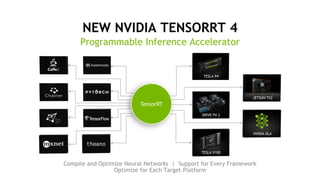



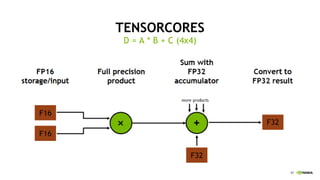





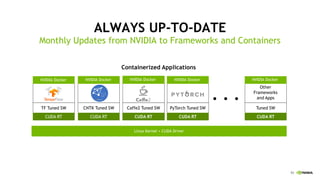









This document provides an overview of Alison B Lowndes' work in artificial intelligence and how AI is being applied across various industries. It discusses using sensors and AI for applications in automotive, communications, consumer goods, financial services, education, manufacturing, media, online services, healthcare, oil and gas, retail, transportation, and utilities. It also briefly outlines Alison's role at a frontier development lab focusing on using AI to help "spaceship earth."




















































































