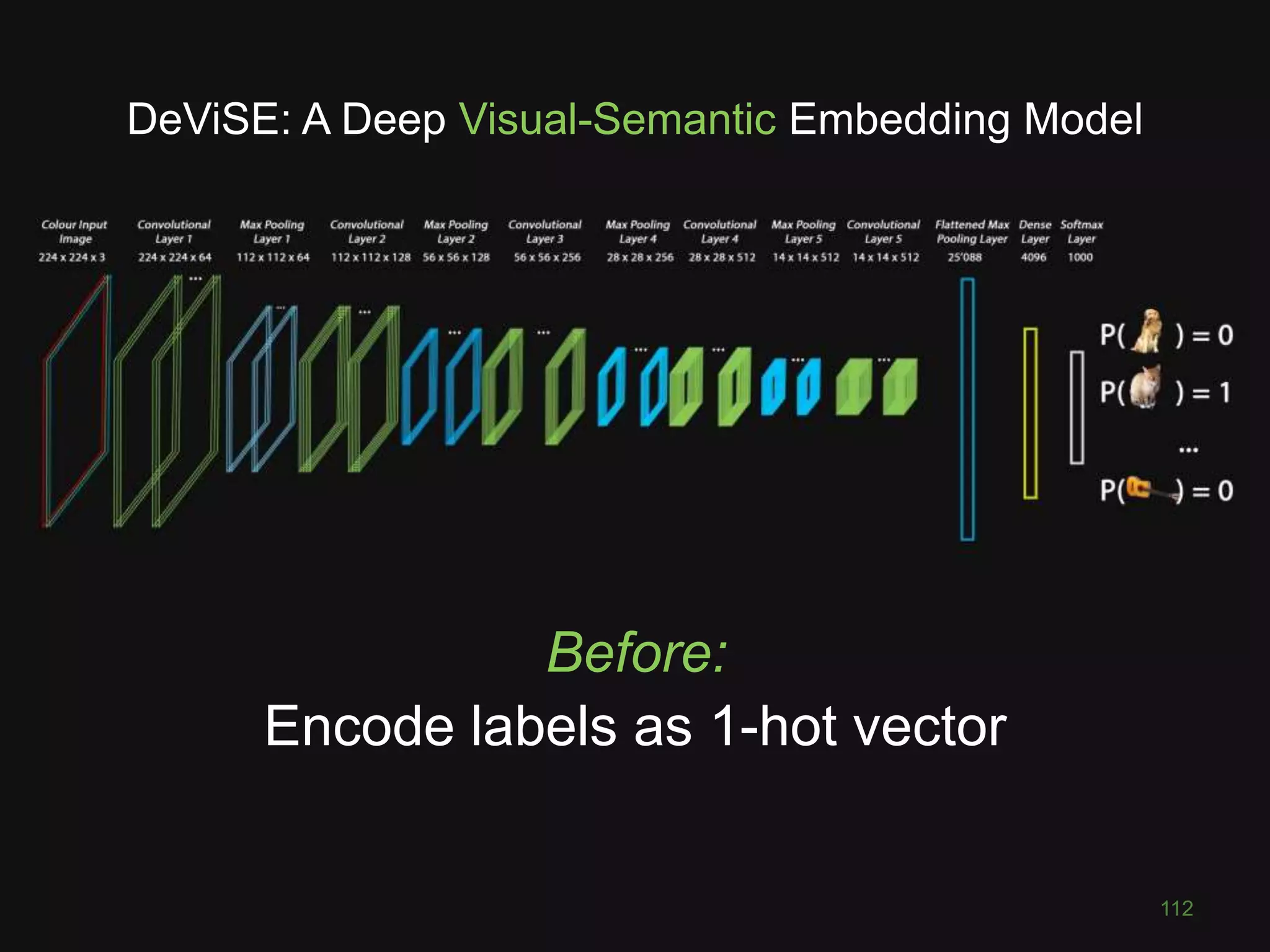
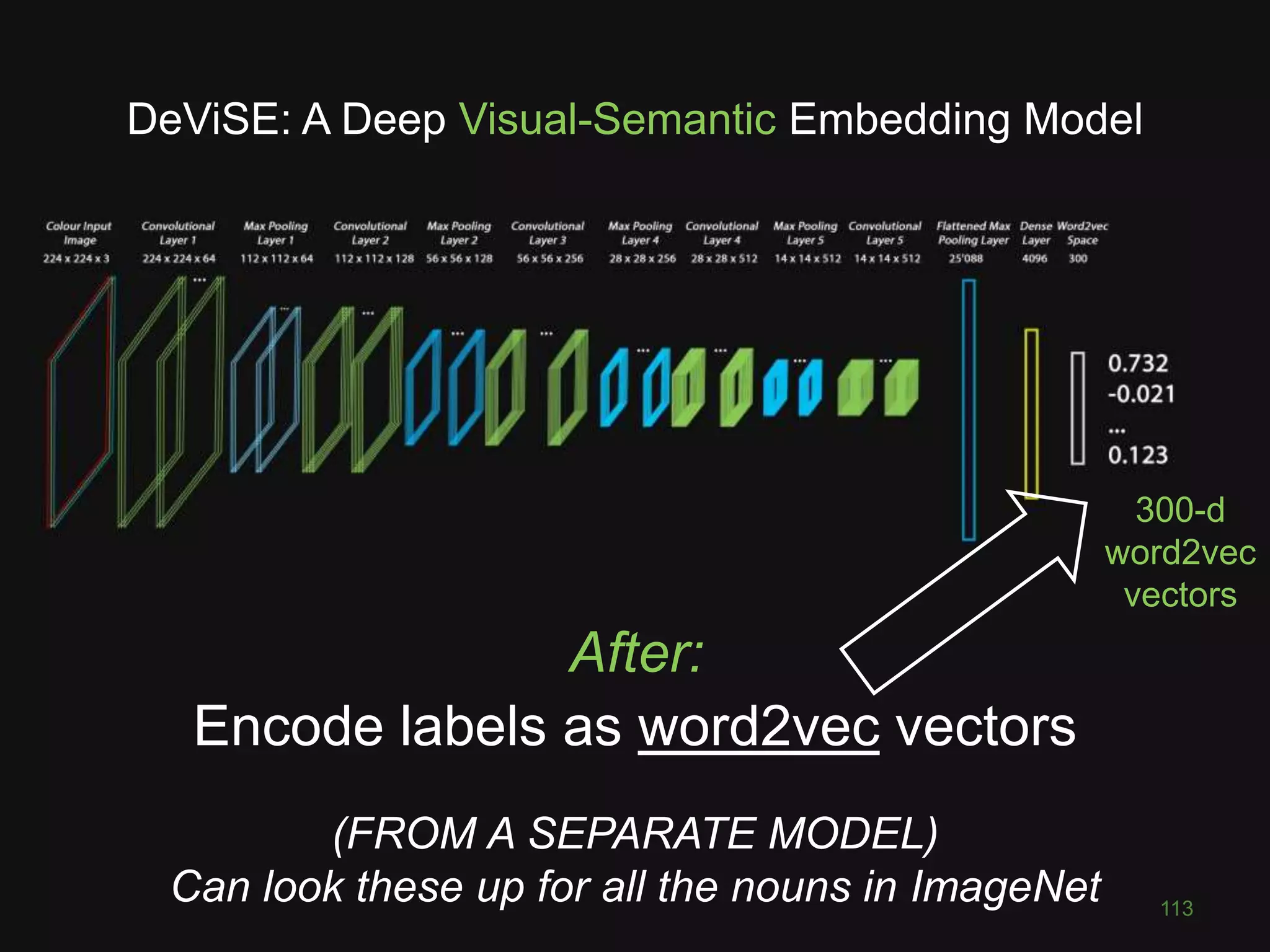
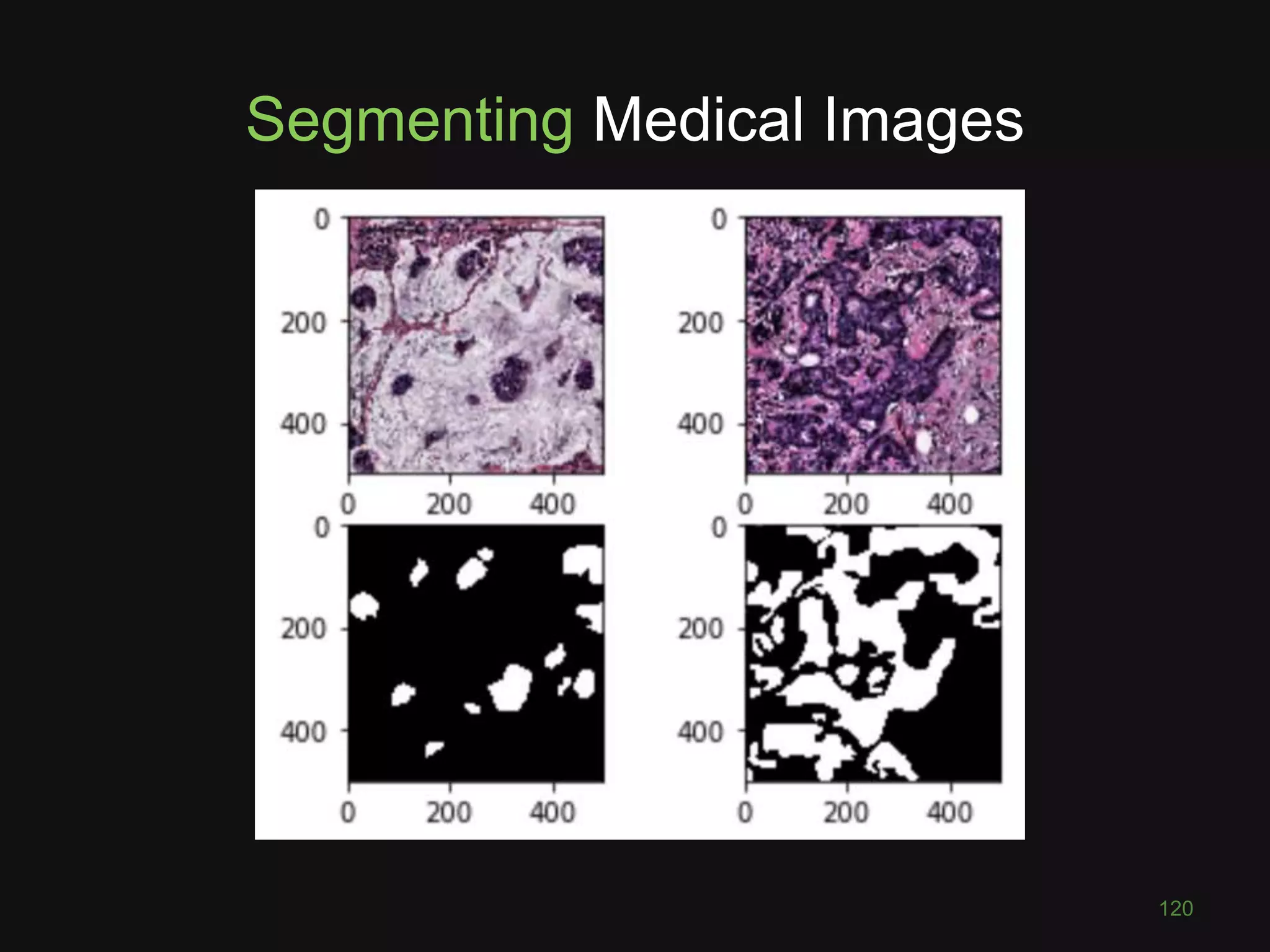
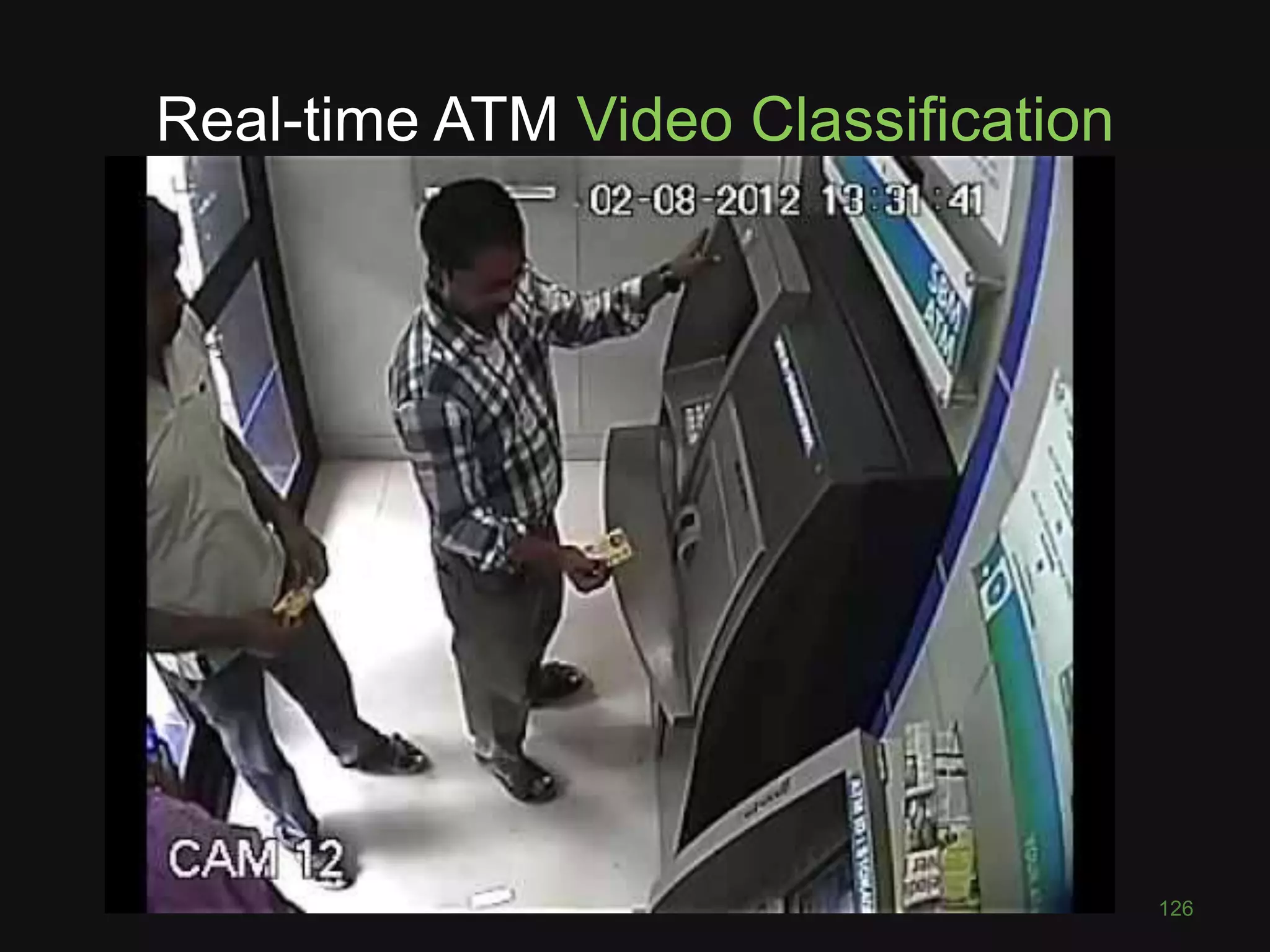
This document discusses deep learning for computer vision tasks. It begins with an overview of image classification using convolutional neural networks and how they have achieved superhuman performance on ImageNet. It then covers the key layers and concepts in CNNs, including convolutions, max pooling, and transferring learning to new problems. Finally, it discusses more advanced computer vision tasks that CNNs have been applied to, such as semantic segmentation, style transfer, visual question answering, and combining images with other data sources.






















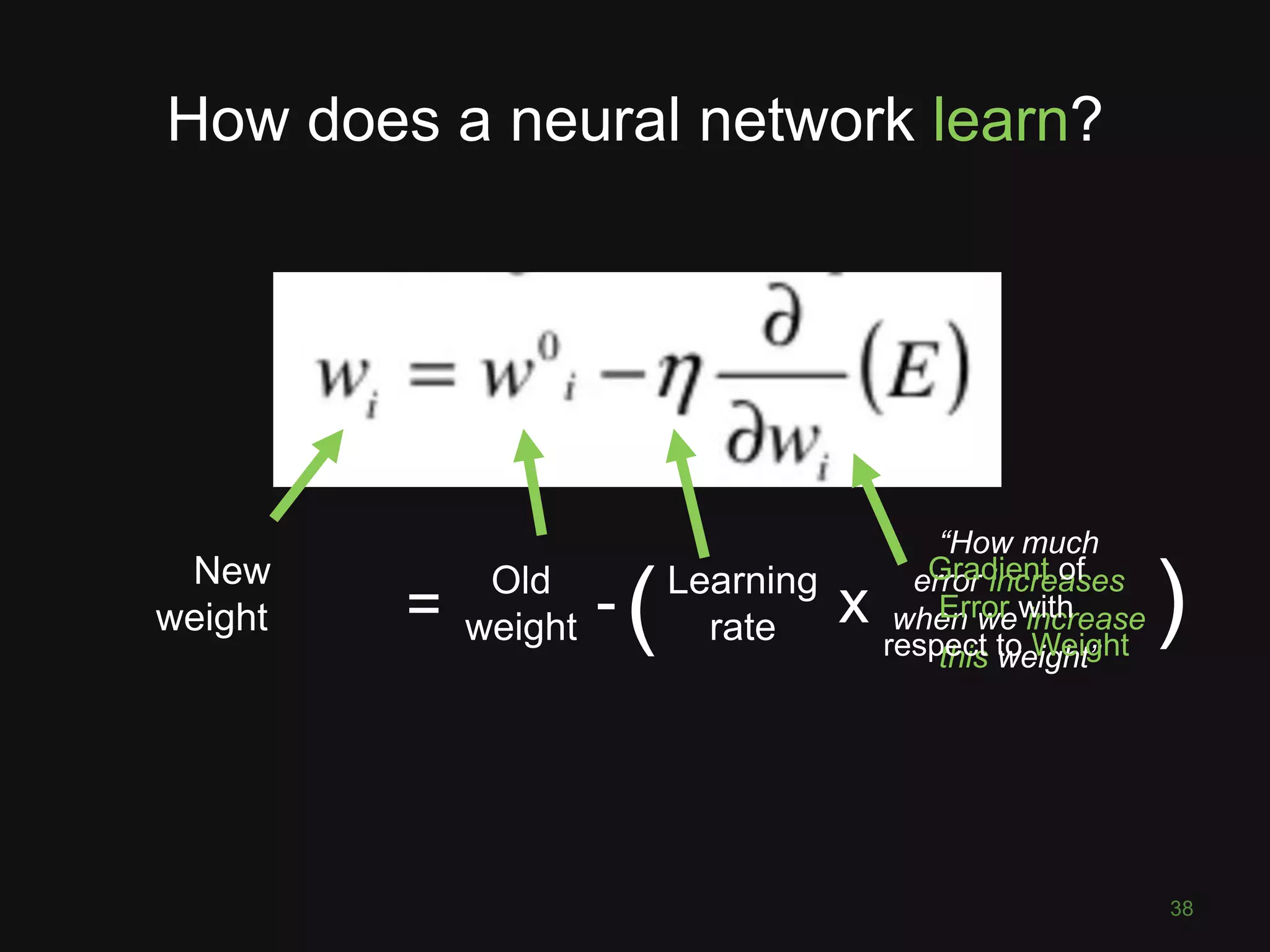
![What is a neuron?
25
• 3 inputs [x1,x2,x3]
• 3 weights [w1,w2,w3]
• 1 bias term b
• Element-wise multiply and sum: inputs & weights
• Add bias term
• Apply activation function f
• Output of neuron is just a number (like the in](https://image.slidesharecdn.com/pyconde17-171025091553/75/Deep-Learning-for-Computer-Vision-PyconDE-2017-24-2048.jpg)
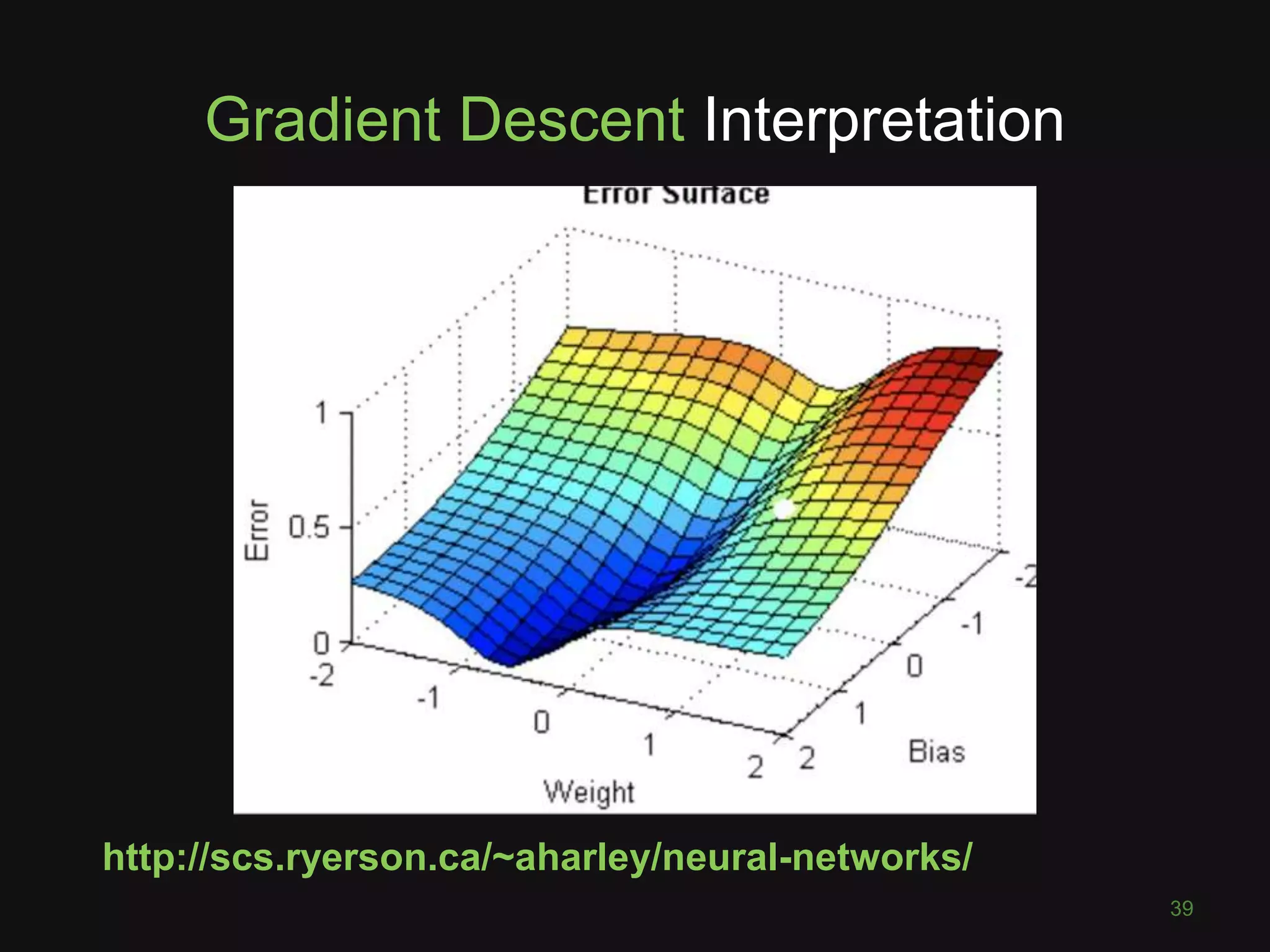
![What is an Activation Function?
26
Sigmoid Tanh ReLU
Nonlinearities … “squashing functions” … transform neuron’s
output
NB: sigmoid output in [0,1]](https://image.slidesharecdn.com/pyconde17-171025091553/75/Deep-Learning-for-Computer-Vision-PyconDE-2017-25-2048.jpg)


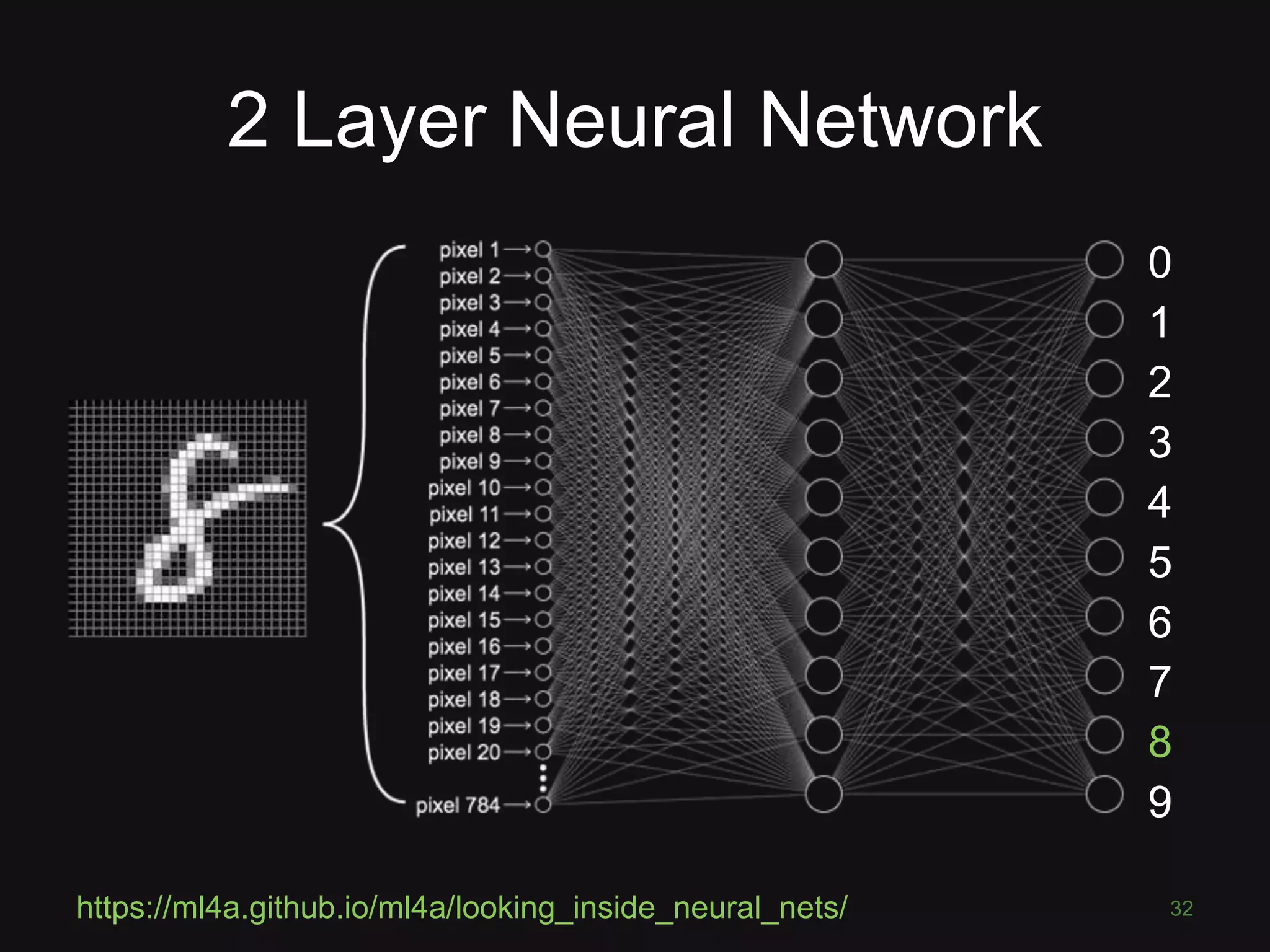
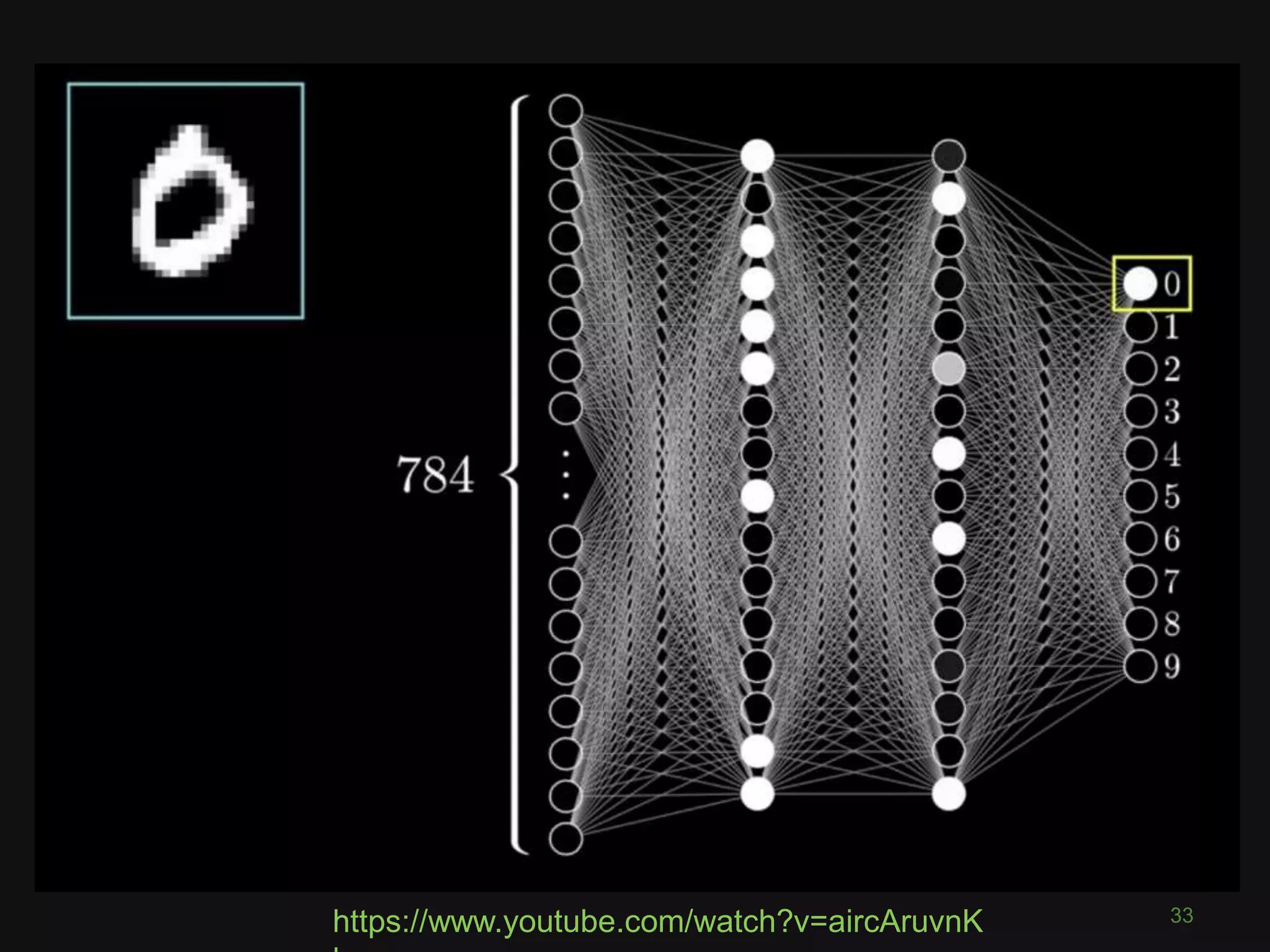
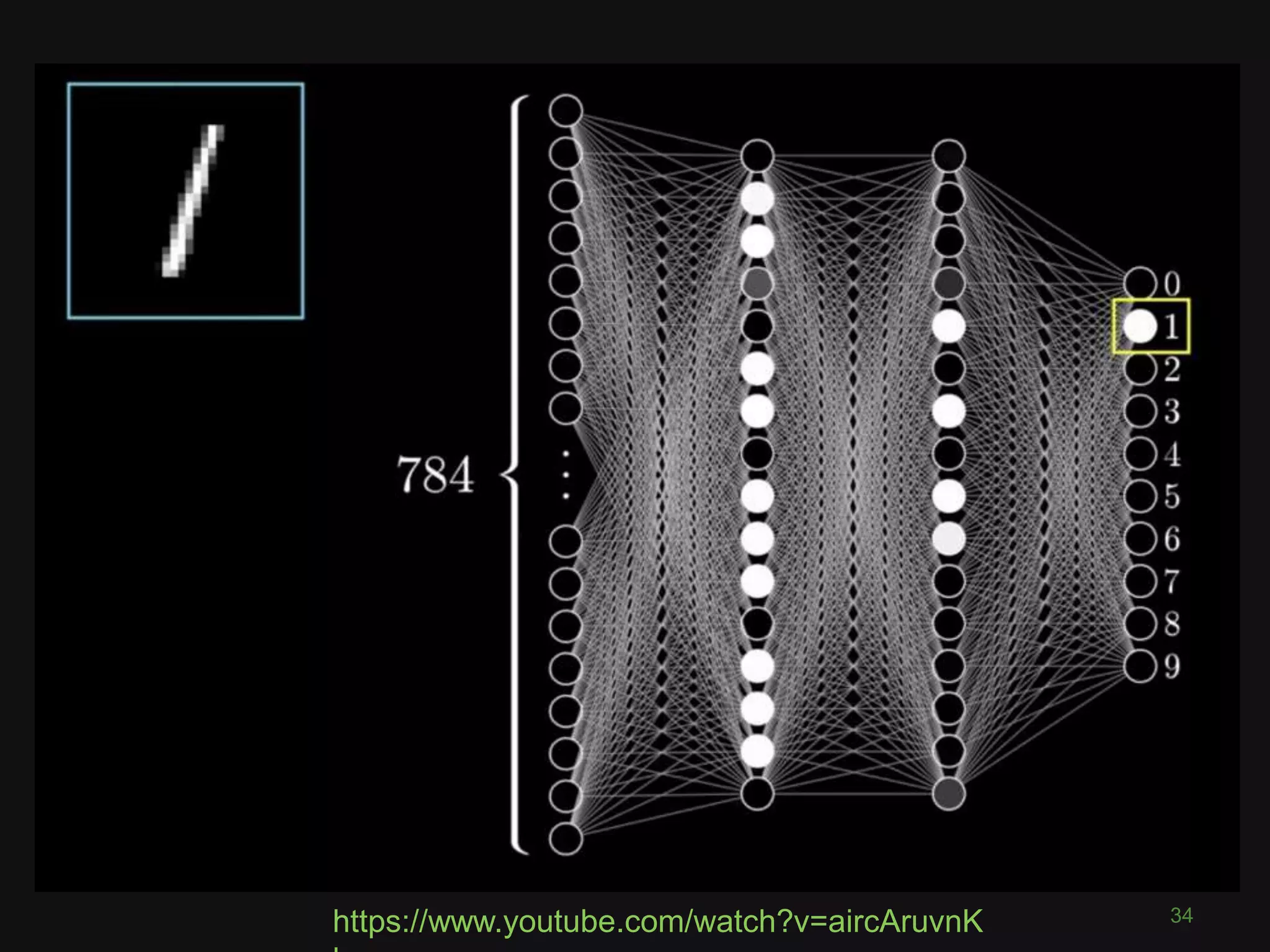
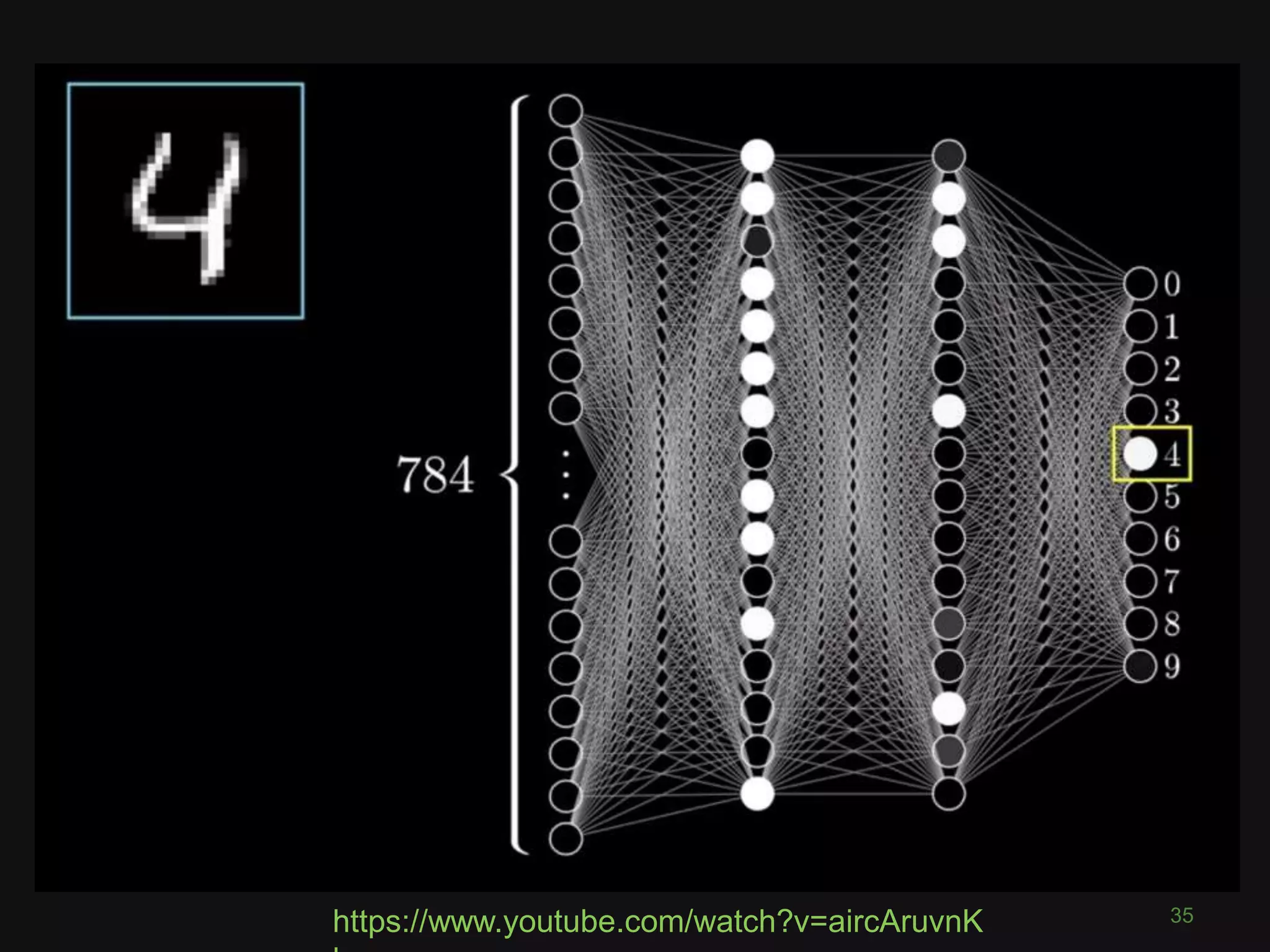





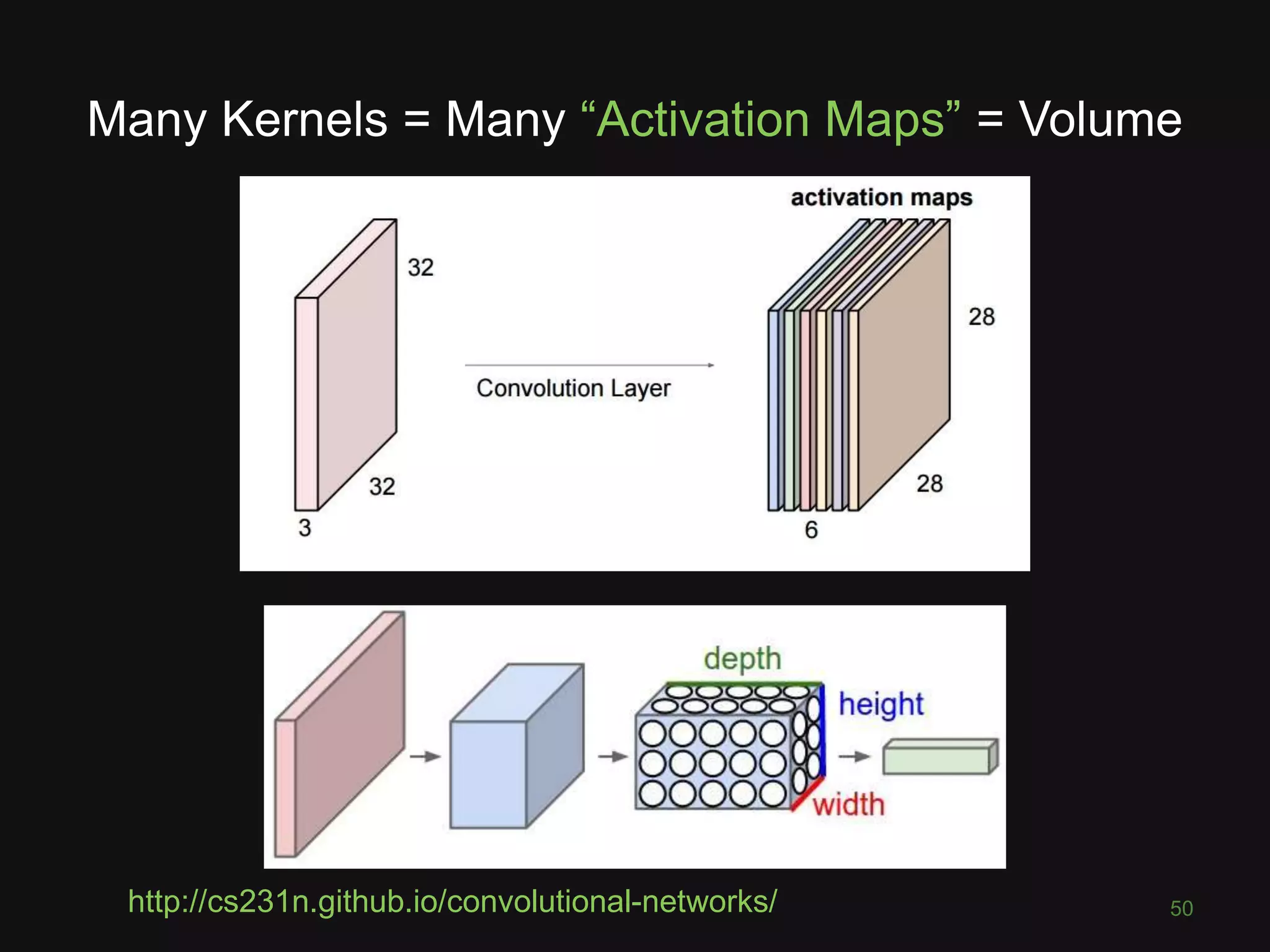
![What is a Convolutional Neural
Network?
43
“like a ordinary neural network but with
special types of layers that work well
on images”
(math works on numbers)
• Pixel = 3 colour channels (R, G, B)
• Pixel intensity ∈[0,255]
• Image has width w and height h
• Therefore image is w x h x 3 numbers](https://image.slidesharecdn.com/pyconde17-171025091553/75/Deep-Learning-for-Computer-Vision-PyconDE-2017-42-2048.jpg)









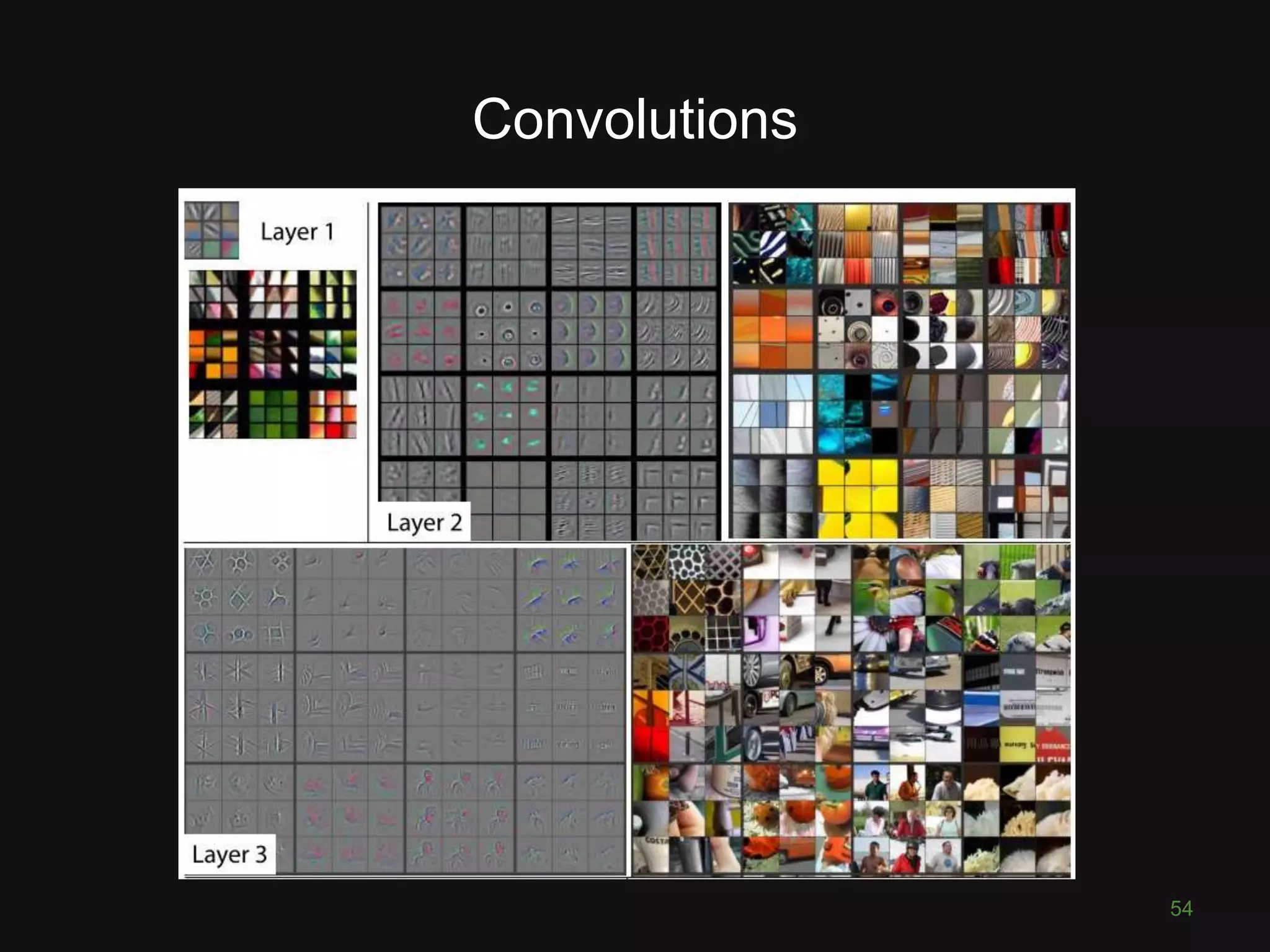










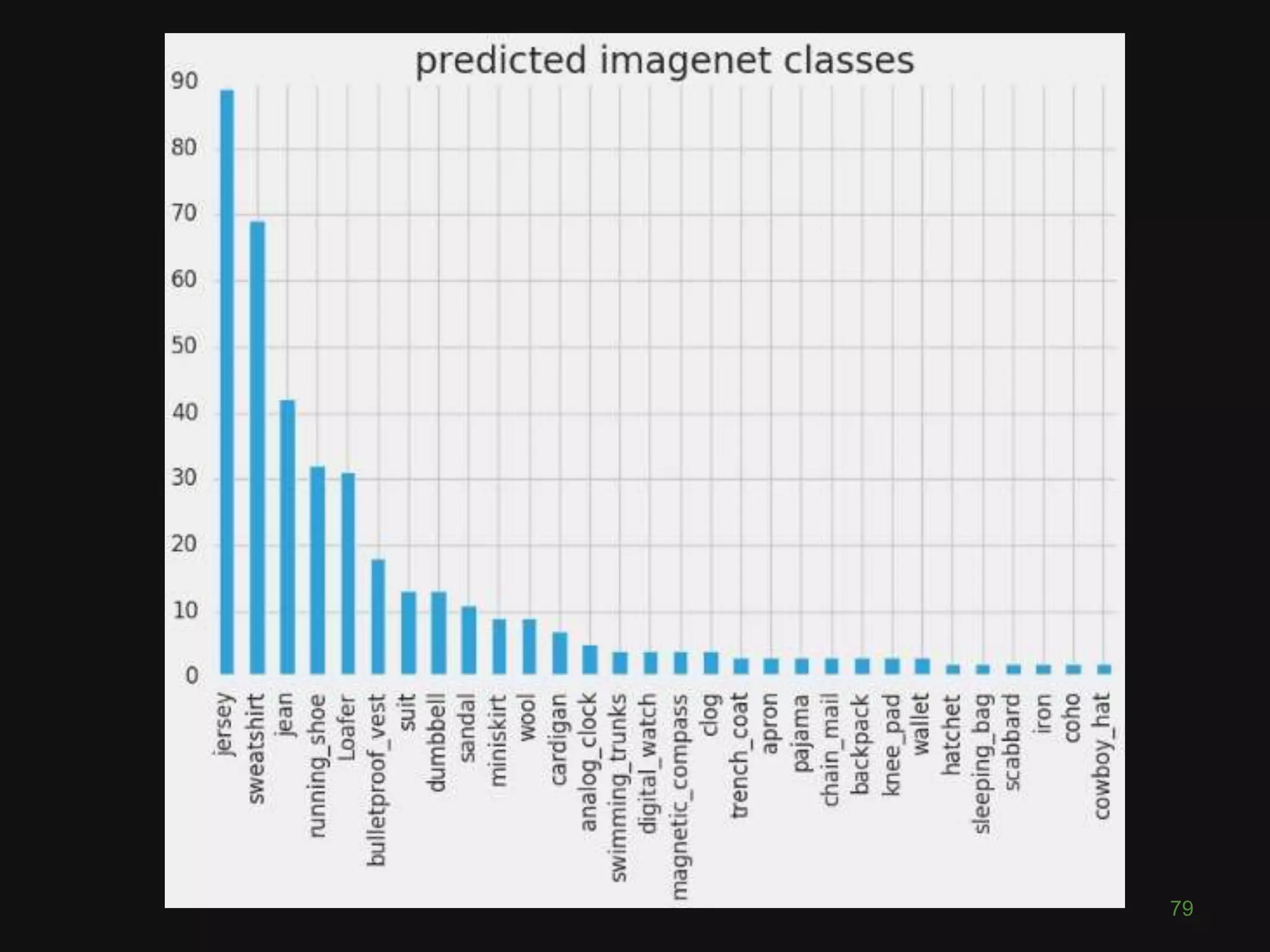
![Softmax
Convert scores ∈ ℝ to probabilities ∈ [0,1]
Final output prediction = highest probability class
67](https://image.slidesharecdn.com/pyconde17-171025091553/75/Deep-Learning-for-Computer-Vision-PyconDE-2017-65-2048.jpg)




















































































![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
