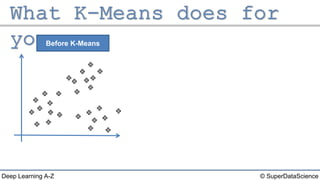
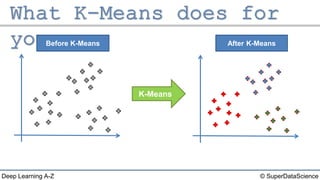
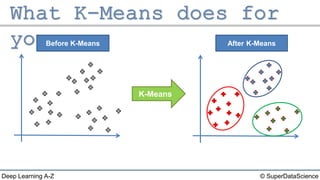
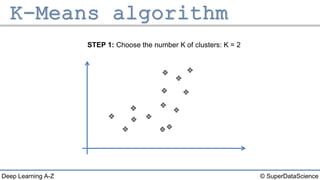
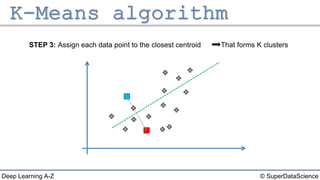
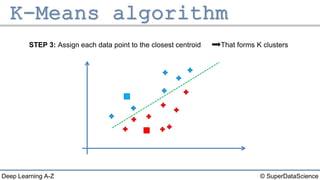
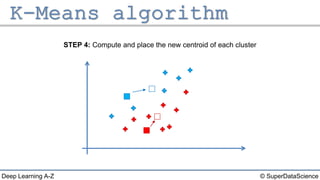
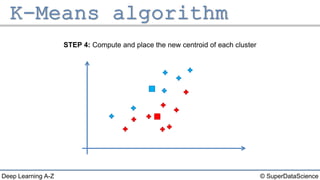
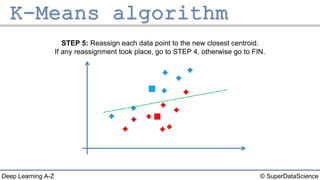
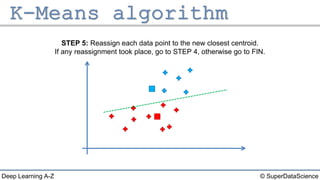
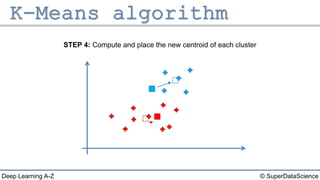
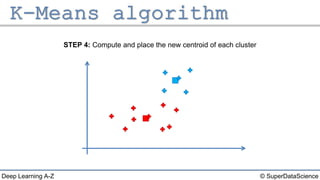
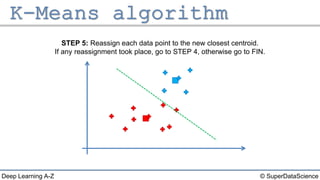
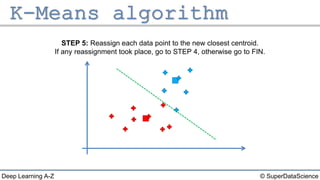
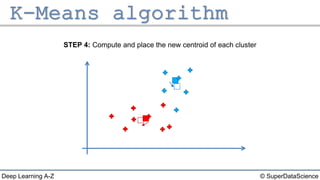
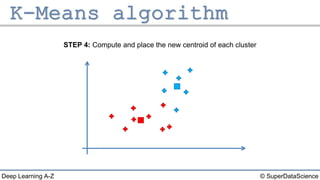
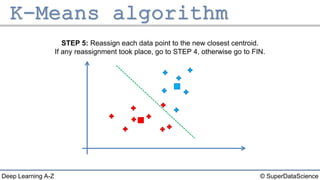
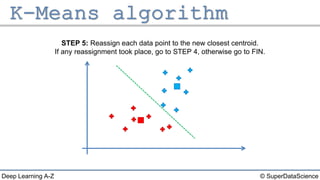
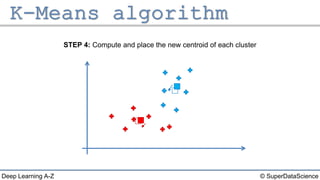
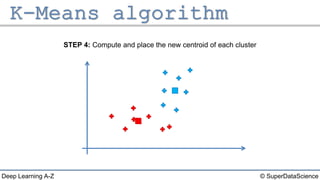
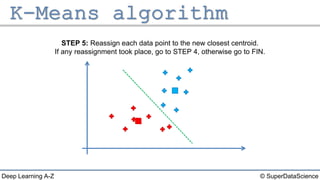
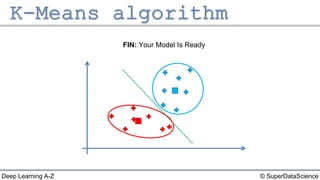
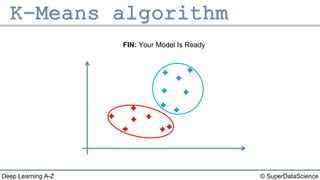
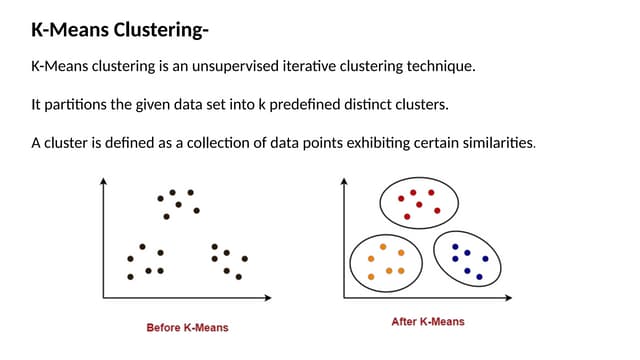
The document describes the K-Means clustering algorithm. It involves choosing the number of clusters K, selecting initial centroid points, assigning data points to the closest centroid, recomputing the centroids, and reassigning points in an iterative process until centroids are stable. The algorithm partitions a dataset into K number of groups based on feature similarity between data points so that the resulting internal homogeneity is high.