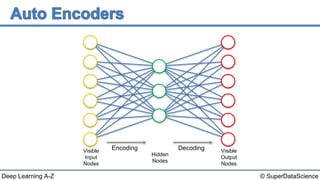
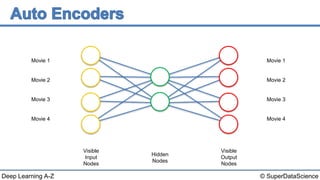
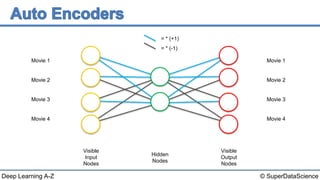
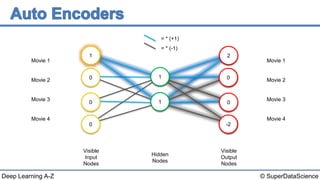
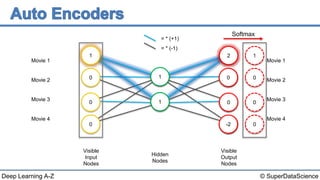
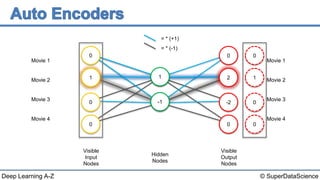
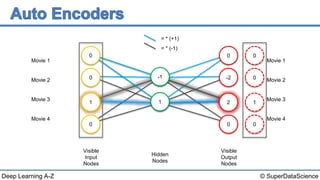
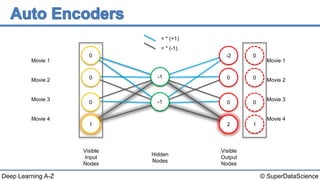
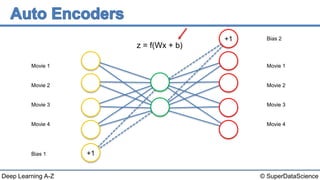
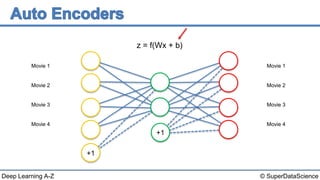
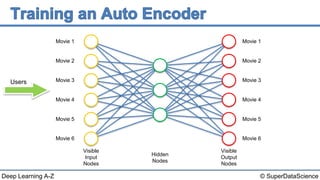
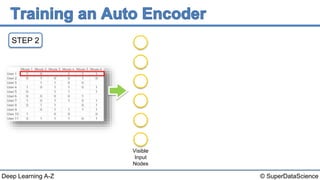
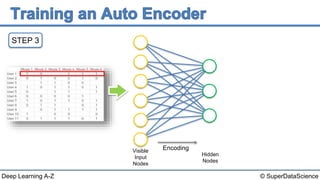
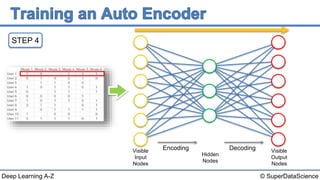
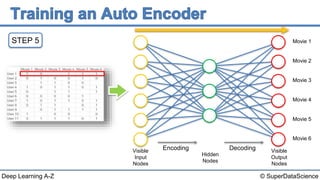
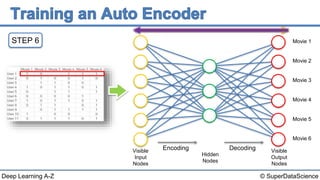
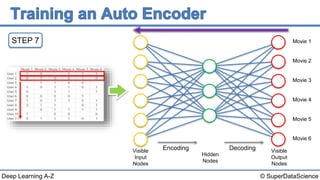
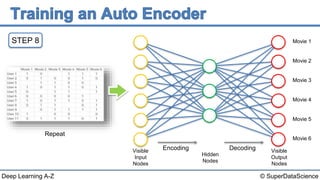
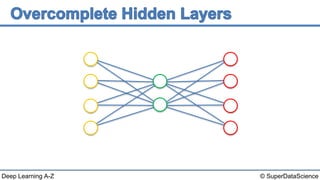
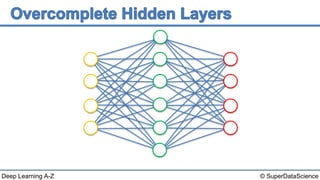
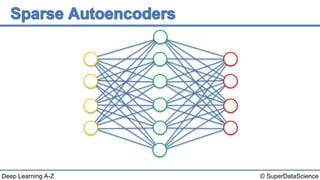
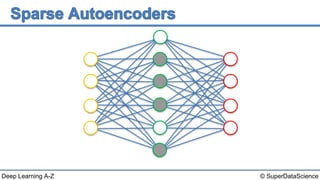
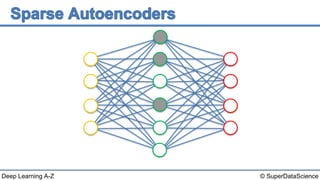
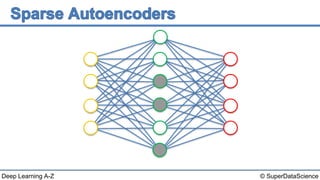
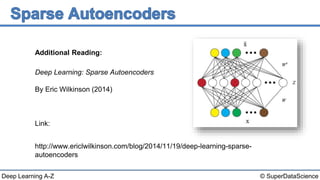
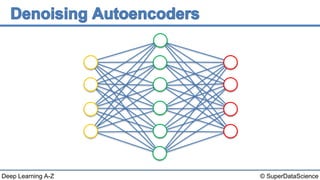
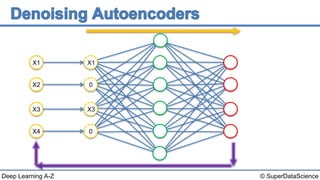
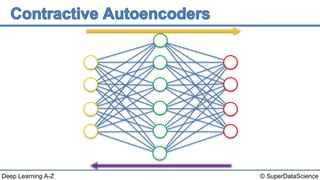
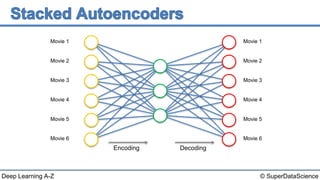
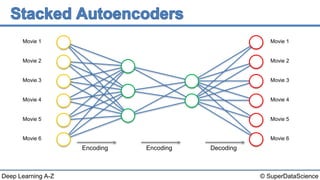
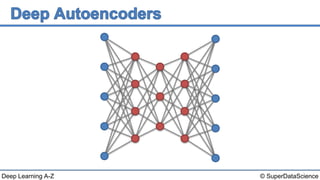
The document discusses autoencoders, an unsupervised machine learning technique. It provides an overview of different types of autoencoders including sparse, denoising, contractive, stacked and deep autoencoders. Autoencoders learn an efficient compressed representation of input data in an unsupervised manner by training the network to ignore noise or corruptions in the input data. They are commonly used for dimensionality reduction, feature learning and compression.