

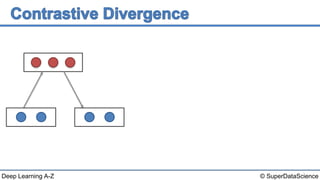
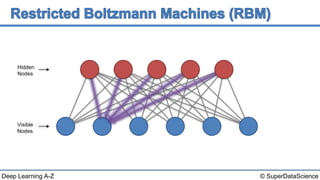
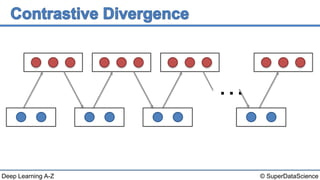
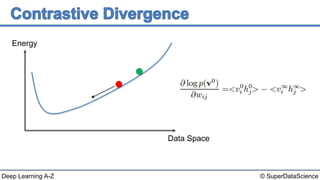
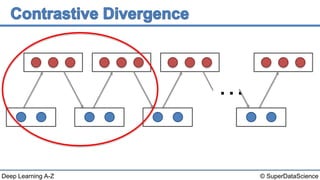
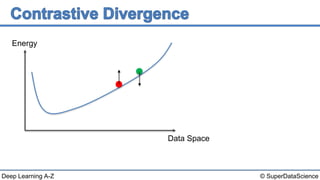
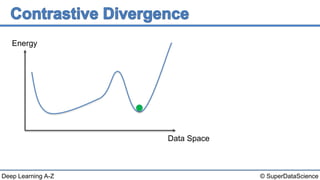
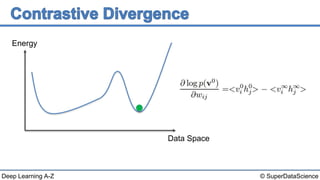
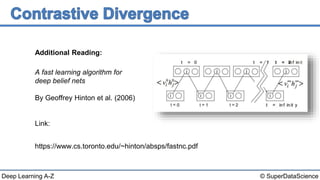

This document discusses a 2006 paper that introduced a fast learning algorithm for deep belief nets. It allowed these types of networks to be trained efficiently for the first time. The paper presented contrastive divergence, an approximation algorithm that makes it possible to train deep belief networks layer-by-layer in a greedy, unsupervised manner. Additional reading on contrastive divergence and notes are also referenced.















































































