Downloaded 31 times




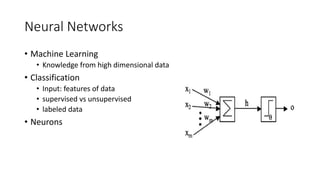

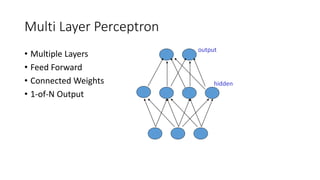
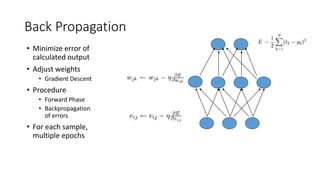

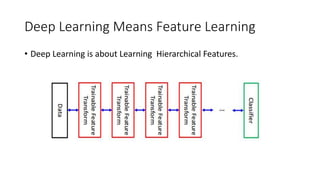
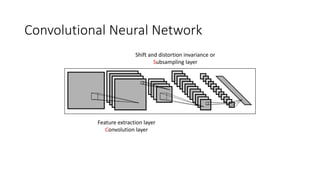
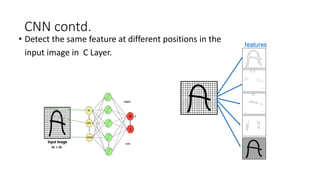






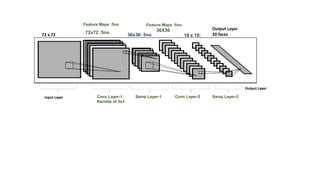

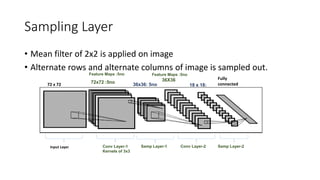
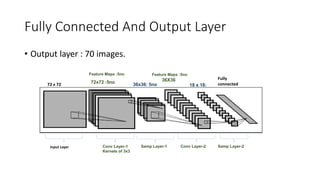



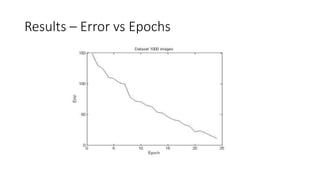
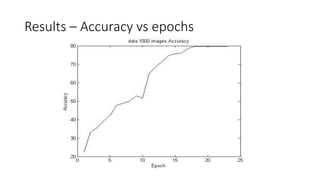




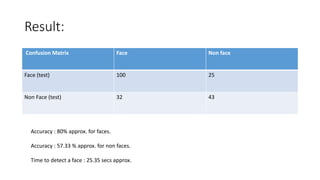



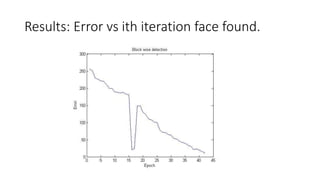
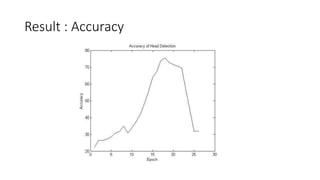


This document discusses deep learning and convolutional neural networks. It provides an example of using a CNN for face detection and recognition. The CNN architecture includes convolution and subsampling layers to extract features from images. Backpropagation is used to minimize error and adjust weights. The example detects faces in images with 80% accuracy for faces and 57% for non-faces. Iterative search with a CNN is also used for object recognition in full images.




































![[Revised] Intro to CNN](https://cdn.slidesharecdn.com/ss_thumbnails/googletechsprinttalkcnnintro-200730141604-thumbnail.jpg?width=640&height=640&fit=bounds)





























