GraphAdapter: Tuning Vision-
LanguageModels With Dual
Knowledge Graph
Tien-Bach-Thanh Do
Network Science Lab
Dept. of Artificial Intelligence
The Catholic University of Korea
E-mail: osfa19730@catholic.ac.kr
2025/02/24
Xin Li et al.
NeurIPS 2023
2.
2
Introduction
● VLMs likeCLIP and ALIGN have shown promising representation capability for downstream vision tasks
● VLMs offer superior zero-shot generalization and impressive transferability for downstream tasks
● Efficient Transfer Learning (ETL) transfers task-relevant knowledge from VLMs to downstream tasks by tuning a
few parameters
● Two popular ETL approaches are prompt tuning and adapter-style tuning
3.
3
Problem Statement
● Adapter-styleETL methods have limitations:
○ Modeling task-specific knowledge with a single modality only
○ Overlooking the exploitation of structure knowledge in downstream tasks
● A small number of samples in a low-data regime are hard to guide the model to sufficiently excavate the structure
knowledge in downstream tasks, leading to bias and causing sub-optimal transferability and generalization
capability
● It is vital to model the multi-modality structure knowledge of downstream tasks for the tuning of VLMs in the low-
data regime
4.
4
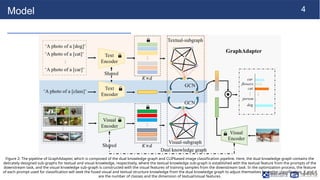
Model
Figure 2: Thepipeline of GraphAdapter, which is composed of the dual knowledge graph and CLIPbased image classification pipeline. Here, the dual knowledge graph contains the
delicately designed sub-graphs for textual and visual knowledge, respectively, where the textual knowledge sub-graph is established with the textual feature from the prompts of the
downstream task, and the visual knowledge sub-graph is constructed with the visual features of training samples from the downstream task. In the optimization process, the feature
of each prompt used for classification will seek the fused visual and textual structure knowledge from the dual knowledge graph to adjust themselves for better classification. K and d
are the number of classes and the dimension of textual/visual features.
5.
5
Preliminaries
Contrastive Language-Image Pre-training(CLIP)
● CLIP designed to learn continuous visual representation based on 0.4 million text-image pairs
● Learn visual representation with the supervision of textual embedding by contrastive loss
● Textual encoder and visual encoder warp prompts and images into textual embedding zt and visual
embedding zv
● Classification using CLIP:
○ K prompts like “a photo of a [class]” are inputted to the textual feature extractor to obtain textual
embeddings as labels of K classes
○ Class of each image is achieved with:
class cosine similarity learned temperature
6.
6
Model
Overview
● GraphAdapter modelstask-specific knowledge with fused textual and visual structure knowledge
● GraphAdapter addresses two crucial challenges:
○ Modeling the structure knowledge for downstream tasks
○ Learning task-specific knowledge by introducing two-modality structure knowledge
● It exploits graph learning to model structure knowledge for downstream tasks when tuning VLMs
7.
7
Model
Dual Knowledge Graph
●The dual knowledge graph consists of a textual sub-graph and a visual sub-graph
● Textual Knowledge Sub-Graph : Nodes represent semantics/classes in textual
space , and edges measure inter-class relationships based on feature distance
edge between ith and jth nodes
● Visual Knowledge Sub-Graph : Nodes are constructed with mean features of training
samples, and edges model relationships between classes
● The dual knowledge graph contains two-modality structure knowledge from downstream tasks, which
enables the feature adapter with sufficient and reliable perception for downstream tasks
8.
8
Model
Adapting with theDual Knowledge Graph
● Introduce the dual knowledge graph for textual/visual adapters, and let each adapter be aware of the
structure knowledge in the same modality and cross-modality
● Graph learning is introduced to the textual adapter, where each feature of the prompt warps the textual
and visual structure knowledge through the GCN, and then fuse two warped knowledge to modulate the
original feature for classification in a residual way
● Expand textual knowledge sub-graph and visual knowledge sub-graph by concatenating node
textual/visual knowledge sub-graph with textual features zt, then compute their edges
● gtt and gvt are utilized to excavate the knowledge for adapting the texture feature from each node in
textual and visual knowledge sub-graphs:
9.
9
Model
GraphAdapter Framework
● Theframework includes construction of the dual knowledge graph and adapter-style CLIP-based
classification
● The dual knowledge graph is established only once for the whole training process, and the textual
encoder is also only run once to obtain the textual embedding of each prompt
● In the optimization process, given one textual feature, the relation between it and the nodes of the dual
knowledge graph will be computed as the condition to warp the knowledge from the dual knowledge
graph to adjust the textual embedding in the residual form
11
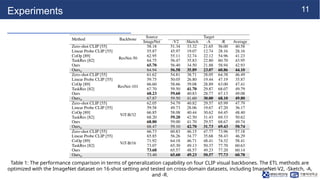
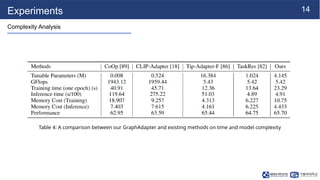
Experiments
Table 1: Theperformance comparison in terms of generalization capability on four CLIP visual backbones. The ETL methods are
optimized with the ImageNet dataset on 16-shot setting and tested on cross-domain datasets, including ImageNet-V2, -Sketch, -A,
and -R.
12.
12
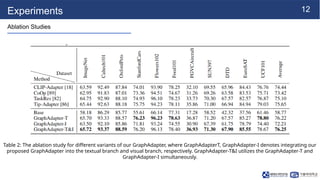
Experiments
Ablation Studies
Table 2:The ablation study for different variants of our GraphAdapter, where GraphAdapterT, GraphAdapter-I denotes integrating our
proposed GraphAdapter into the textual branch and visual branch, respectively. GraphAdapter-T&I utilizes the GraphAdapter-T and
GraphAdapter-I simultaneously.



![5
Preliminaries
Contrastive Language-Image Pre-training (CLIP)
● CLIP designed to learn continuous visual representation based on 0.4 million text-image pairs
● Learn visual representation with the supervision of textual embedding by contrastive loss
● Textual encoder and visual encoder warp prompts and images into textual embedding zt and visual
embedding zv
● Classification using CLIP:
○ K prompts like “a photo of a [class]” are inputted to the textual feature extractor to obtain textual
embeddings as labels of K classes
○ Class of each image is achieved with:
class cosine similarity learned temperature](https://image.slidesharecdn.com/nslabseminar250224graphadapter-250224130027-8504e9dc/85/NS-Lab_Seminar_250224-GraphAdapter-pptx-5-320.jpg)






![[NS][Lab_Seminar_250407]AlignmentLearning.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250407alignmentlearning-250407124309-1acb59f1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_240619]A Simple Baseline for Weakly-Supervised Scene Graph G...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240619ws-sgg-240628124826-477bbe86-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_240729]VQA-GNN: Reasoning with Multimodal Knowledge via Grap...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240729vqa-gnn-240806103318-b8ebf4d7-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NS][Lab_Seminar_240617]A Survey on Graph Neural Networks and Graph Transform...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240617asurvey-240624082546-9e44d3fd-thumbnail.jpg?width=640&height=640&fit=bounds)









![250623_JW_labseminar[STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/250623jwlabseminarcontextpred-250627073644-0949d35d-thumbnail.jpg?width=640&height=640&fit=bounds)



![240304_Thanh_LabSeminar[Pure Transformers are Powerful Graph Learners].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240304thanhlabseminartokengt-240409105926-a93f6988-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NS][Lab_Seminar_241111]Patch-Wise Graph Contrastive Learning for Image Trans...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241111patch-wisegraphcontrastivelearningforimagetranslation-241118111607-5d2d1621-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_240624]Graph Neural Networks for End-to-End Information Extr...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240624stge-240624082503-16e200ab-thumbnail.jpg?width=640&height=640&fit=bounds)


![260119_SH_LabSeminar[ENGRAM]_최종2_최종3_4.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/260119shlabseminarengram234-260120052642-29f38c8f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NS][Lab_Seminar_260126]MIHC: Multi-View Interpretable Hypergraph Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar260126-260126110047-559006b2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NS][Lab_Seminar_260119][DHGFormer: Dynamic Hierarchical Graph Transformer fo...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar260119-260120052625-9b28e6ed-thumbnail.jpg?width=640&height=640&fit=bounds)











![260105_JH_LabSeminar[A Plant-Wide Industrial Process Control Problem].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/260105jhlabseminartep-260106063928-34e9f1f6-thumbnail.jpg?width=640&height=640&fit=bounds)




















