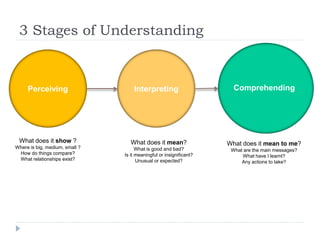
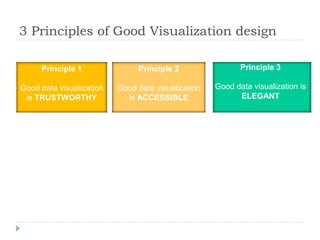
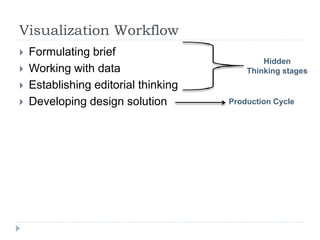
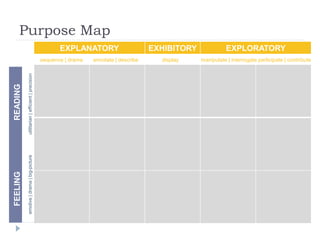
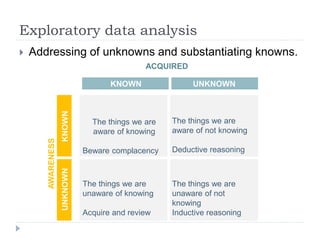
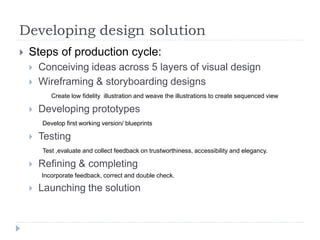
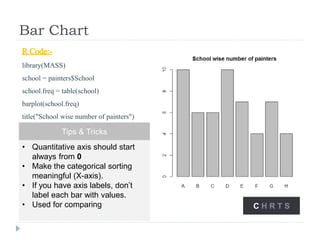
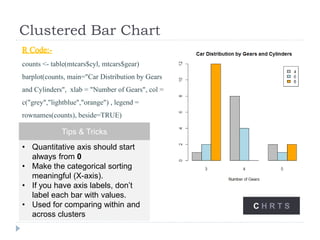
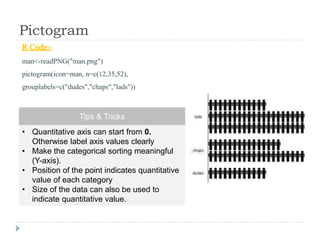
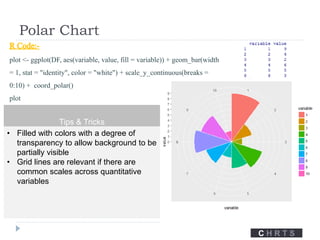
The document discusses data visualization tools and techniques, emphasizing the importance of trustworthy, accessible, and elegant designs. It outlines a visualization workflow that includes understanding data types, formulating briefs, establishing editorial thinking, and developing design solutions through various stages of production. Additionally, it provides coding examples in R for different chart types, tips for effective visualization, and covers principles necessary for creating impactful visual representations of data.