Downloaded 26 times





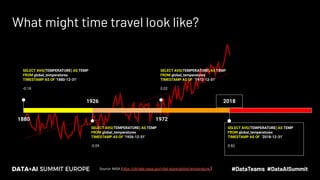
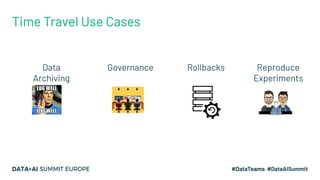

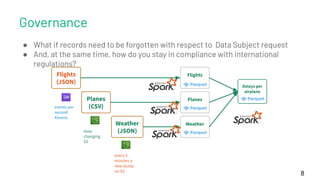
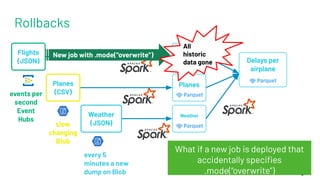




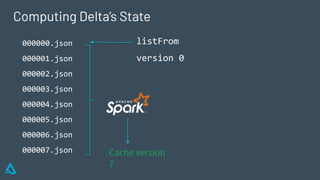

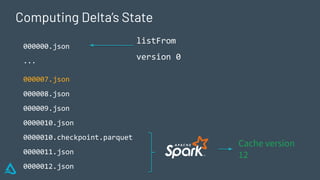
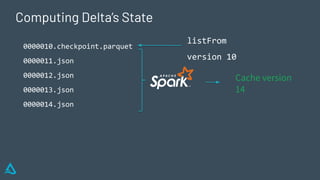
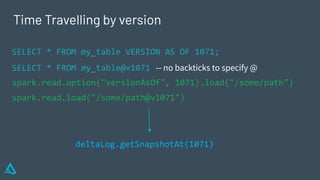
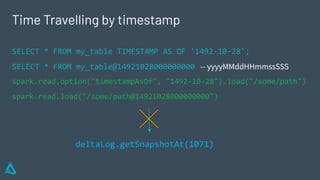





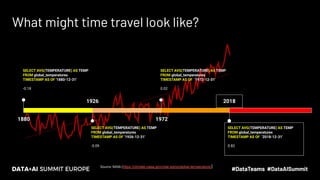
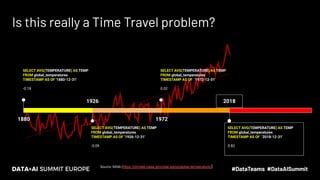
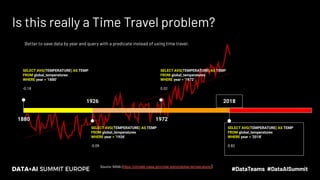



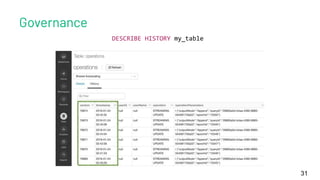



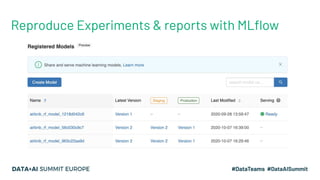





The document discusses the concept of time travel in data management, focusing on its use cases like data archiving, rollbacks, governance, and reproducing machine learning experiments. It elaborates on the Delta Lake technology that supports time travel and highlights practical examples such as querying historical data and managing changes to datasets over time. Additionally, it addresses challenges related to data storage, recency, and the trade-offs involved in historical data access with time travel mechanisms.


















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




