Downloaded 37 times







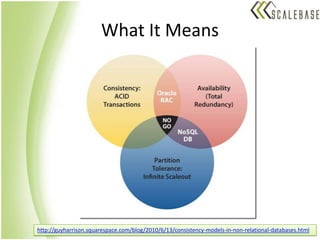





















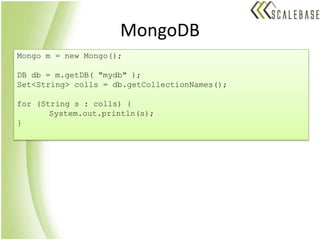





The document discusses data service level agreements (SLAs) in public cloud environments. It explains that achieving availability, consistency, and scalability is challenging due to Brewer's CAP theorem. It reviews strategies for relational and NoSQL databases to handle these tradeoffs, including dropping consistency or availability depending on needs. Code examples demonstrate typical operations for Cassandra, MongoDB, and Neo4J NoSQL databases. The conclusion recommends choosing solutions based on requirements and migrating to NoSQL as needed to address scaling issues.



![[SSA] 03.newsql database (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/03-140225072436-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































































