Downloaded 29 times




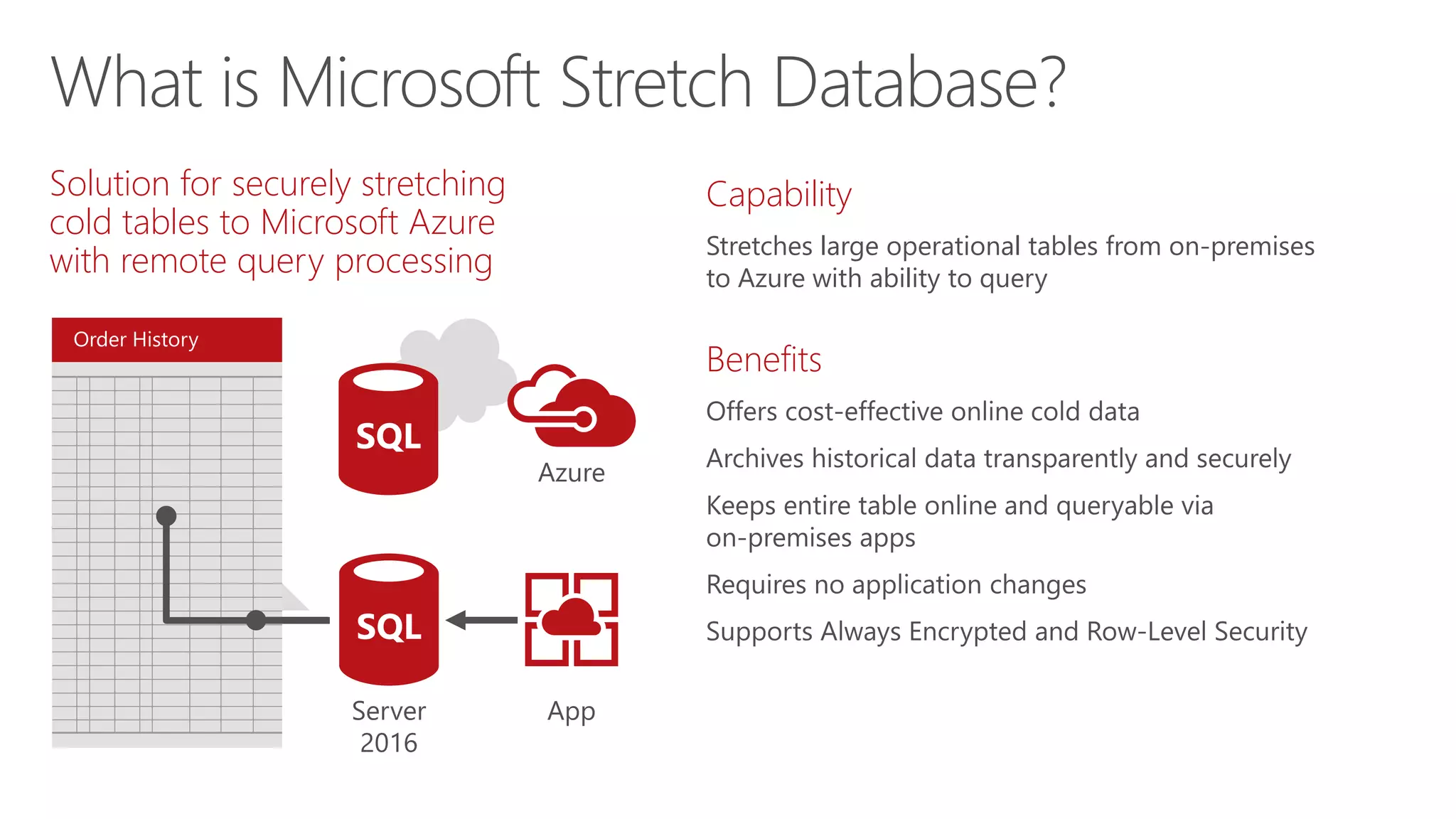






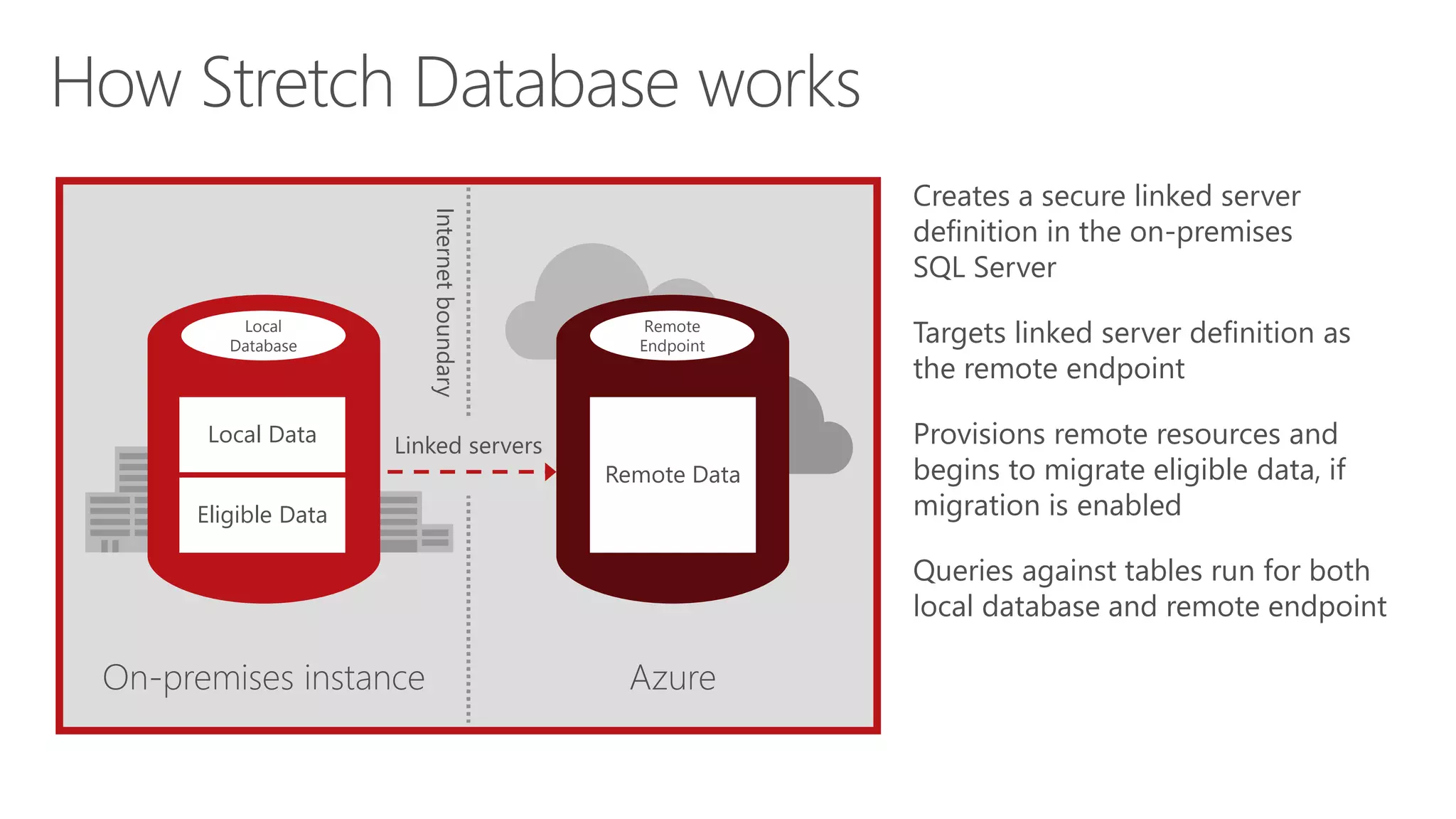

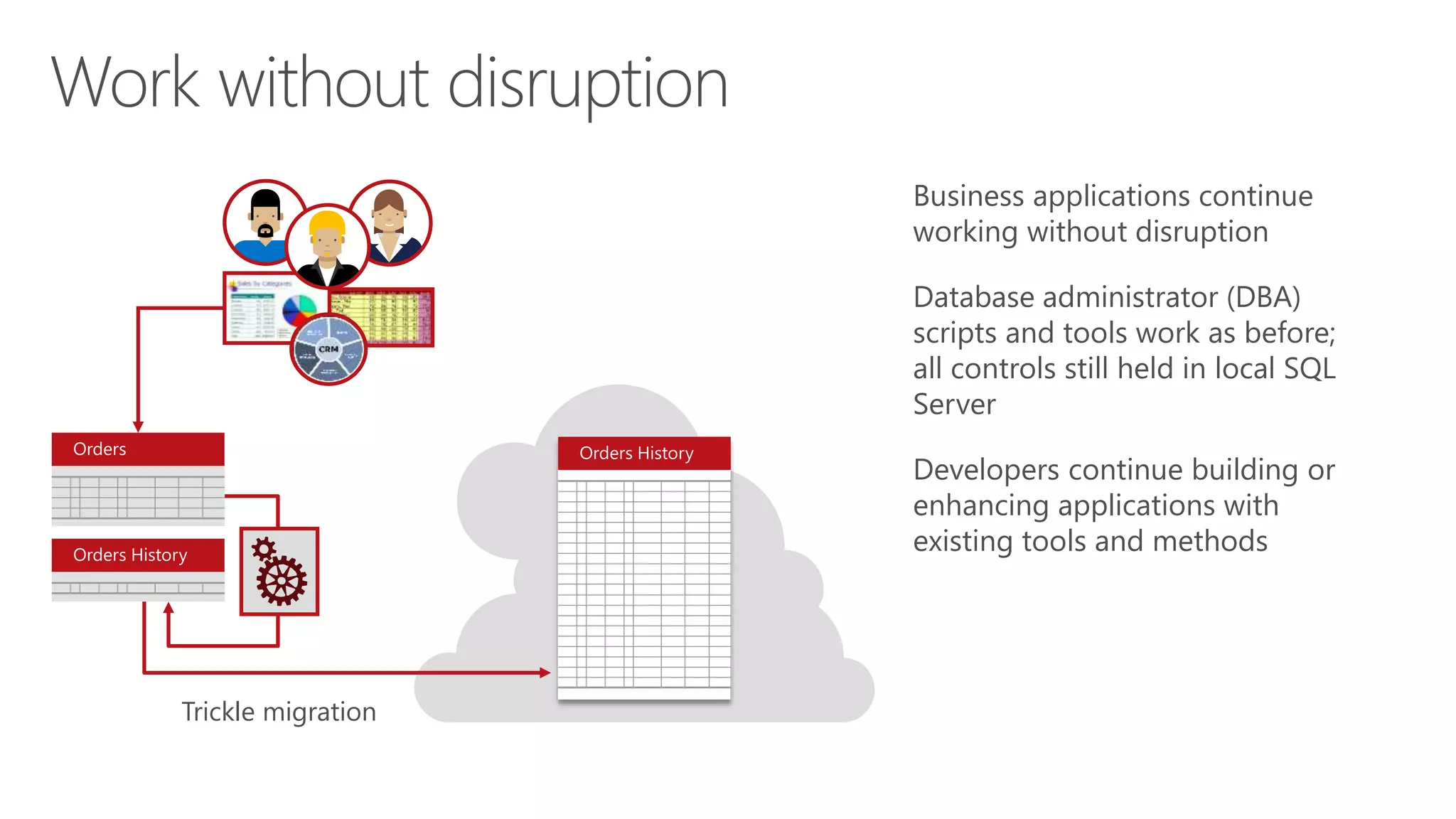

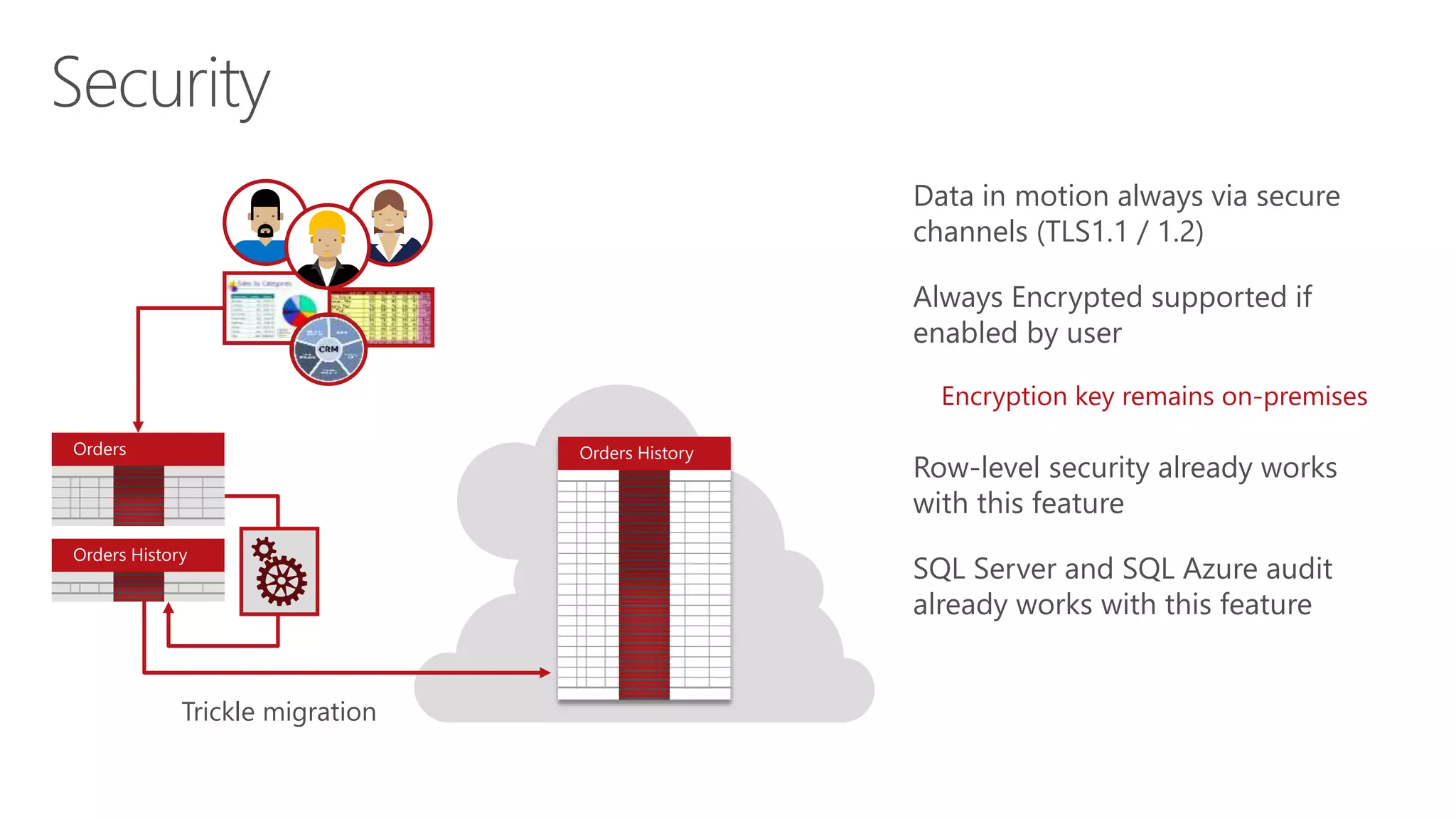
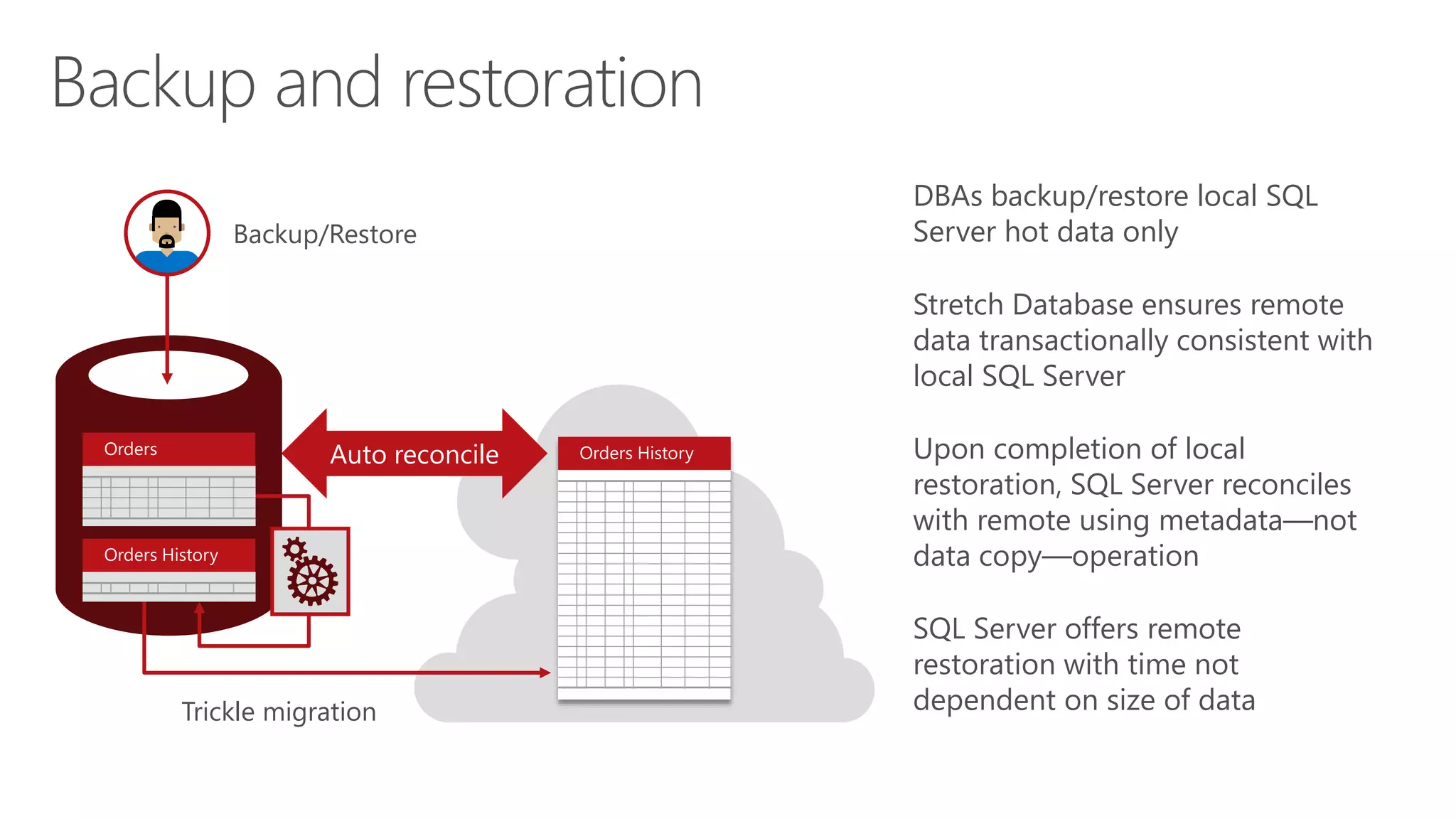

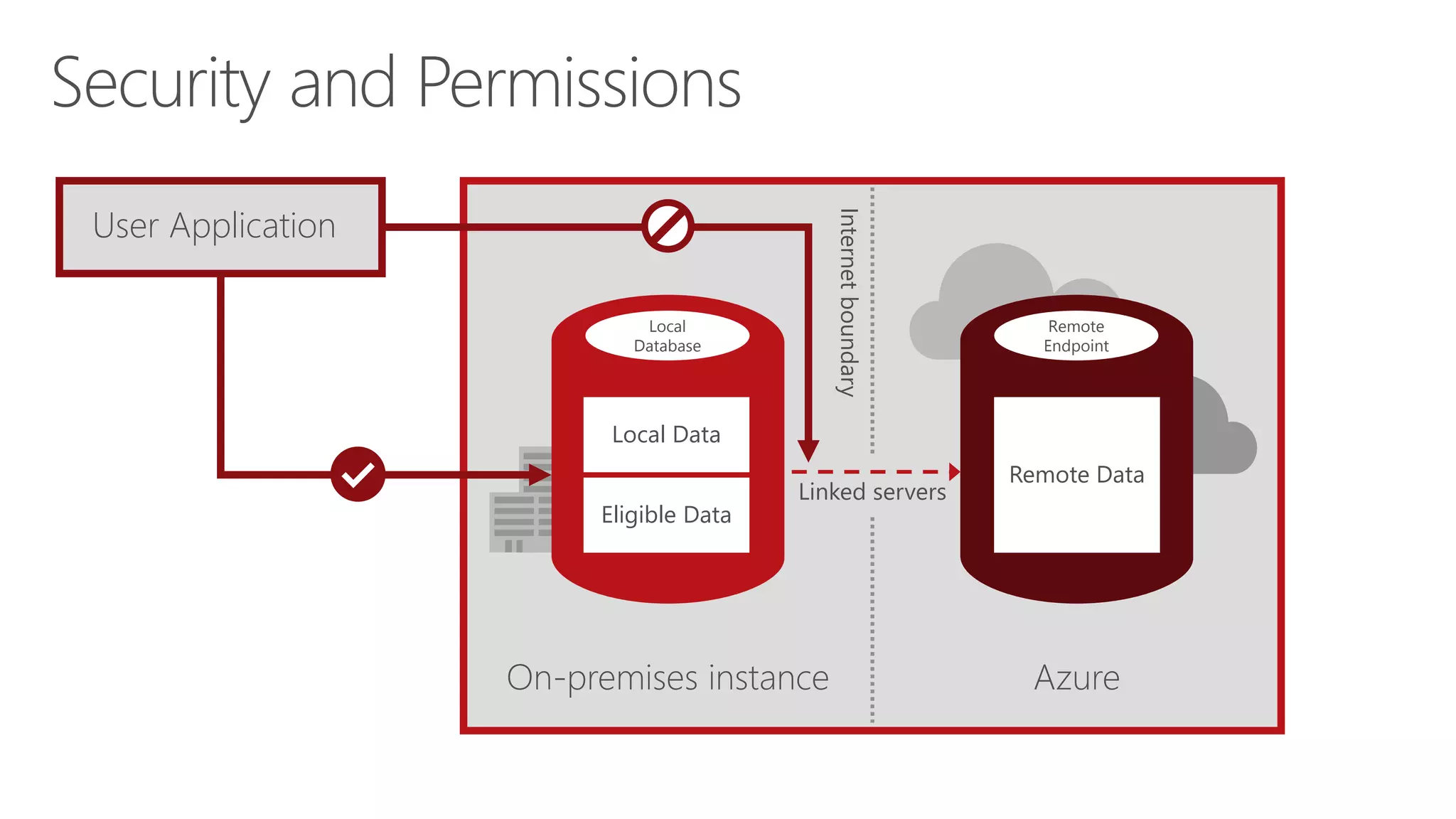


Eladio Rincón discusses Microsoft SQL Server 2016's Stretch Database capability. Stretch Database allows organizations to migrate cold, historical data from on-premises SQL Server databases to Microsoft Azure for cost savings while still allowing the data to be queried locally and on Azure. The key benefits are reducing storage costs for large datasets, providing indefinite data retention within a consolidated datacenter in Azure, and ensuring business service level agreements are met. Stretch Database uses secure connections and provides backup, restore, and auditing functionality across the on-premises and Azure environments.





































































































