본 문서는 ArminBalalaie, Abbas
Heydarnoori, Pooyan Jamshidi의
“Microservices Migration
Patterns”(2015)를 요약 정리한 것입니다.
3.
차례
Cloud Migration& Pattern Meta-model
Migration and Re-architecture Patterns
Selecting and Composing Migration Patterns
Adding New Patterns to the Repository
Cloud Migration
5
• Microservices를이용한 Cloud Native Application으로의 이행은 복잡하고 어려운
문제
• 시행착오와 자원의 낭비를 줄이려면 방법론 필요
• 요구사항, 현 상태, 구성원들의 역량 등을 고려하면 단일한 방법론을 정립하는
것은 어려움 Situational Method Engineering (SME) 접근법
1) Meta-model에 따라 재사용 가능한 프로세스 패턴이나 method chunk(=이행 패턴)를
패턴저장소에 저장
2) 이전의 SME 경험을 활용하고 이행 패턴을 정의함으로써 microservices로의 이행 경험과
최신의 유사한 microservices 이행 패턴을 일반화
3) 그것들을 패턴 템플릿으로 변환하여 각 부분들이 메타 모델의 요소들과 일대일 대응
• 방법론 관리자들은 이 패턴 저장소에서 선택 지침에 따라 필요한 패턴을
선택하여 그 선택된 패턴을 사용하여 맞춤형 방법론 완성
6.
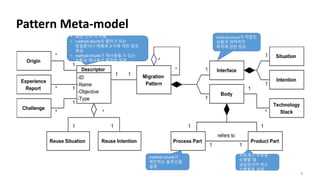
Pattern Meta-model
6
method chunk가적합한
상황과 개략적인
목적에 관한 정보
method chunk가
제안하는 솔루션을
설명
프로세스 부분을
수행할 때
생성되어야 하는
산출물을 설명
• 패턴 선택 시 사용
• method chunk의 출처가 되는
방법론이나 체험보고서에 대한 참조
제공.
• method chunk가 재사용될 수 있는
상황과 재사용의 목적을 설명
7.
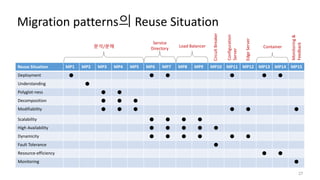
이행 패턴 선택요인(factor)
7
Factor Description
Architectural
Factors
Scalability 서비스를 수평 확장(scale-out)함으로써 어플리케이션의 확장성 증가
High Availability 서비스를 복제함으로써 어플리케이션의 가용성 증가
Fault Tolerance 어플리케이션 장애 발생의 기회를 줄이고 장애를 효과적으로 처리할 수 있는 방법을 제공
Modifiability 최소한의 부작용과 최종사용자에게 영향을 미치지 않고 어플리케이션의 변경을 가능하게 함
Polyglot-ness 어플리케이션이 다른 프로그래밍 언어와 데이터 저장소를 가질 수 이게 함
Decomposition 어플리케이션을 일련의 서비스로 나누는 재구조화(Re-architecting)
Understanding 어플리케이션의 현재 상태 인지
Visioning 이행 후 어플리케이션의 최종 상태 결정
Operational
Factors
Dynamicity 최종사용자에게 영향을 주지 않고도 어플리케이션을 실행 중에 변경할 수 있음
Resource-efficiency 어플리케이션 배포에 필요한 자원 양의 감소
Deployment 어플리케이션 배포 절차를 촉진하고 배포시 예외사항 제거
Monitoring 실행시에도 어플리케이션을 효과적으로 모니터링할 수 있음
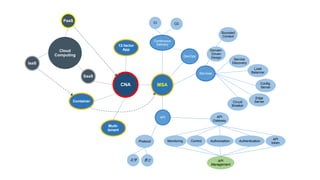
Microservices의 필수 구성요소
10
ServiceDiscovery
Load Balancer
Circuit Breaker
Edge Server
• 개별 서비스는 load 분산을 위해 여러 instance 사용
• 배포된 서비스, 서비스 자체의 정확한 주소와 port 번호의 추적 관리는 매우 복잡한 작업
• Service Discovery는 각 서비스의 가용한 instance를 찾아서 사용할 수 있도록 함
• 서비스를 여러 instance에 분산하는 역할
• Service Discovery로부터 어떤 instance가 가용한지를 확인
• Cloud Native Application의 핵심 중 하나가 fault toleration
• 개별 서비스의 장애가 전체 시스템의 장애가 도지 못하도록 하여 피해가 가장 낮은
수준에서 멈추도록 완화하는 역할
• API Gateway 서버를 설치하고 API를 통해 외부로 정보/기능을 공유하도록 하는 서버
• 외부에서 내부로 들어오는 모든 트래픽을 routing해 주는 서버
• Client는 시스템 서비스의 내부 구조의 변화에 영향을 받지 않음
• 소스 코드와 설정 정보(Configuration)의 분리 설정 정보가 바뀌어도 코드 전체를 다시
배포할 필요 없음
• Configuration serve에 설정 정보 저장 서비스들이 불러올 수 있도록 함(fetch)
Configuration Server
11.
[MP1] Enable ContinuousIntegration
11
Technology Stack
Gitlab, Artifactory, Nexus, Jenkins, GoCD, Travis, Bamboo,
Teamcity
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
• Microservices로 이행하기 위한 소프트웨어 시스템이 있고 그것을
개발/운영하는 팀이 존재
• microservices를 도입 후 수많은 서비스를 어떻게 항상 대기상태
유지?
• Continuous Delivery를 도입할 수 있도록 시스템을 준비하는 방법?
• code repository, artifact repository, Continuous Integration server
도입
• 서비스는 분리된 저장소에 : 개별 이력과 빌드 라이프 사이클 관리
• 서비스의 code repository가 변경될 때마다 서비스별 Continuous
Integration job이 자동 실행 : repository 에서 새로운 코드를
가져오고, 테스트하고, 결과물을 만들어 artifact repository 등록
• 오류 발생시 오류를 전달받은 관련팀(서비스)은 오류가 해결될
때까지 모든 작업 정지
• 새로운 변경사항은 시스템의 안정성을 깨뜨릴 수 있으므로 반드시
미리 정의된 모든 테스트를 수행
Reuse Intention Build the Continuous Integration pipeline
Reuse Situation Deployment
12.
[참고] Continuous Integration이란?
12
CI(ContinuousIntegration : 지속적인 통합)
• 지속적으로 소프트웨어 품질 관리를 적용하는 프로세스를 실행하는 것.
• 모든 가발을 완료한 뒤에 퀄리티 컨트롤을 적용하는 고전적인 방법을 대체하는 방법으로서 소프트웨어의
질적 향상과 소프트웨어를 배포하는데 걸리는 시간을 줄이는데 초점
• 초기에 그리고 자주 통합해서 통합 시 발생하는 여러가지 문제점을 조기에 발견하고, 피드백 사이클을 짧게
하여 소프트웨어 개발의 품질과 생산성을 향상시기는 것.
13.
[MP2] Recover theCurrent Architecture
13
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
• 현재 운영하는 소프트웨어 시스템을 microservices로 이행 결정
• 이행 계획을 세우기 위해 아키텍처 파악, 분석
• 시스템의 청사진(big picture)은 무엇인가?
• 이행계획에 필요한 high-level 정보는 충분한가?
• Component and Service Architecture
- 아키텍처를 시각화 하여 설명 이해도 향상
- 각 구성요소의 내부 도메인 상세 내역 이해
• Technology Architecture:
- 현재 Technology stack에 대한 이해 : 아키텍처/비아키텍처 기능
- 언어, DB, 미들웨어, 라이브러리 등 모두 나열
• Deployment Architecture and Procedure
- 아키텍처 이해 과정에 개발팀과 운영팀 참가 공통된 이해
- 문서화는 이행 후에
Reuse Intention Create Migration Plan initial state
Reuse Situation Understanding
14.
[MP3] Decompose theMonolith
14
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
N/A
단점 (Challenge)
• 복잡한 도메인을 갖고 있는 통짜구조(monolithic) 소프트웨어
시스템 : 시스템 복잡, 영역별 별도의 비기능 요건, 변경시 전체
재배포
Reuse Intention Re-architect a System to a set of services using Domain-driven Design
Reuse Situation Polyglot-ness, Decomposition, Modifiability
• 시스템을 더 작은 단위로 분해하는 방법은 무엇인가?
• 이 단위들은 어느 정도로 커야 하는가?
• 잘못된 시스템 분해 이행 과정 중 미해결 우려 성능저하 문제
• Domain-Driven Design (DDD) 기법 사용하여 서비스로 분해
- 시스템의 초기 분해에 사용
- DDD를 하위 도메인에 적용하여 더 작은 도메인 단위로 분해
• 각 도메인은 개별 배포 단위인 Bounded Context (BC) 구성 : 1:1
대응
• BC의 크기는 시스템 요구사항에 유동적으로 구성
• 처음에는 2~3개의 서비스로 시작 시스템이 커지고 팀의
이해도가 높아진 다음에 서비스들을 추가
15.
[MP4] Decompose theMonolith Based on Data Ownership
15
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
N/A
단점 (Challenge)
• 복잡한 도메인을 갖고 있는 통짜구조(monolithic) 소프트웨어
시스템 : 시스템 복잡, 영역별 별도의 비기능 요건, 변경시 전체
재배포
Reuse Intention Re-architect a System to a set of services using Data Ownership
Reuse Situation Polyglot-ness, Decomposition, Modifiability
• 시스템을 더 작은 단위로 분해하는 방법은 무엇인가?
• 이 단위들은 어느 정도로 커야 하는가?
• 도메인이 매우 커서 여러 개의 하위 도메인을 갖는 경우에는
혼란스럽고 시간을 많이 잡아먹어서 적절한 분해를 할 수 없음
• 데이터의 소유권 여부에 따라서 시스템을 분해
• 하나의 단위로 결합 가능하고 단일 소유자인 데이터 개체의 집합을
그것이 지원하는 비즈니스 로직과 묶어 패키지화 함
• 다른 서비스는 자신의 소유가 아닌 개체의 복사본만 소유 적절한
동기화 필요
• 시스템에 있는 개체(entity)의 크기와 수에 의해 결정 : 도메인이
복잡하지 않으면 4~5개 정도
개별 개체는 그 서비스를
담당하는 소유자에
의해서만 수정되거나 생성
16.
[MP5] Change CodeDependency to Service Call
16
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
N/A
단점 (Challenge)
• 소프트웨어 시스템은 microservices 아키텍처 스타일을 사용할 수
있도록 일련의 작은 서비스들로 분해되어 있으나 시스템의 어떤
구성 요소는 여전히 다른 서비스나 구성요소에 의존해서 실행
Reuse Intention Transform code-level dependency to service-level dependency
Reuse Situation Decomposition, Modifiability
• 코드 수준의 의존성을 서비스 수준의 의존성으로 바꾸는 적절한
시기?
• 적절하지 않은 때는 언제인가?
• 라이브러리의 종속성을 제거하고 메서드 호출 대신 서비스 호출을
사용하는 것은 때로는 성능 문제 야기
• 가능한 서비스 코드는 별도로 유지 : 서비스간 코드 종속성 배재
• 내부 개체나 인터페이스 스키마를 공유는 금지
• 거의 변경되지 않는 공통 라이브러리로 공유되는 코드(예 : 문자열
조작 라이브러리)는 공유하는 것이 합리적
• 공유하기 어려운 기능은 서비스로 만들어 공유
17.
[MP6] Introduce ServiceDiscovery
17
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Eureka, Consul, Apache Zookeeper, etc
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• 각 서비스는 운영 환경에 하나 이상의 인스턴스가 배포
• 서비스의 인스턴스의 수는 동적으로 변경 & 다른 시스템에도 배포
가능
Reuse Intention Introduce Dynamic Location of services’ instances using Service Discovery
Reuse Situation Scalability, High Availability, Dynamicity, Deployment
• 어떻게 서비스가 각기 동적으로 자리를 잡을 수 있을까?
• Edge Server나 Load Balancer는 어떻게 서비스의 인스턴스 목록을
알 수 있을까?
• SD는 서비스간 통신의 구심점이므로 여기가 잘못되면 Single-
point-of-failure
• 서비스 인스턴스의 주소를 저장하는 Service Discovery를 설정
• 개별 서비스 스스로 Registry에 등록 : 인스턴스로부터 주기적인
신호가 없거나 종료될 때 자동으로 해당 인스턴스가 registry에서
제거
• Edge Server, Load Balancer, 타 서비스는 Service Discovery를
통해 가용한 서비스 인스턴스의 목록을 받아서 필요한 서비스를
탐색
Service Discovery는 시스템의 핵심
구성요소이자 가용성이 매우 중요
복제 전략 필요
18.
[MP7] Introduce ServiceDiscovery Client
18
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Eureka는 서버 버전용 Java 클라이언트가 설치된 Service
Discovery
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Service Discovery 설정
• 서비스의 인스턴스의 수는 동적으로 변경 & 다른 시스템에도 배포
가능
Reuse Intention Facilitate Dynamic Location of services’ instances using Service Discovery Client
Reuse Situation Scalability, High Availability, Dynamicity, Deployment
• Service Discovery는 새로운 인스턴스가 배포되었다는 것을 어떻게
알 수 있을까?
• 인스턴스가 종료되었다는 것은 어떻게 알 수 있을까?
• 사용중인 모든 프로그래밍 언어에 대해 클라이언트를 설치해야
하며 잘못 설치하면 서비스 코드가 복잡해짐
• 개별 서비스는 Service Discovery 주소를 알아야 하고 초기화되는
동안에 registry에 자체 등록
• 개별 인스턴스에서 registry로 주기적으로 신호(heartbeat)를
보내야만 사용가능한 인스턴스 목록에 계속 유지
• 종료 : 신호를 보내지 않거나 registry에 인스턴스 종료를 알림
서비스마다 클라이언트 설치
서비스를 자체 등록하고
Registry에 계속 신호 보냄
19.
[MP8] Introduce InternalLoad Balancer
19
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Ribbon은 Service Discovery인 Eureka와 잘 맞는 Java용
내부 load balancer
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Service Discovery 설정
• 수많은 서비스 인스턴스 & 개별 서비스는 다른 서비스의
클라이언트
Reuse Intention Introduce Load Balancing between instances of a service using Internal Load Balancer
Reuse Situation Scalability, High Availability, Dynamicity
• 클라이언트의 조건에 따라 인스턴스 간에 어떻게 서비스 부하의
균형을 맞출 수 있을까?
• 외부 load balancer 없이 서비스의 부하 균형을 맞추는 방법은?
• SD와 통합될 수 있는 프로그래밍 언어용 내부 load balancer 생성
• 부하 분산 메커니즘이 중앙집중화되지 못함
• 내부에 load balancer를 가진 서비스가 SD에서 가용한 인스턴스
목록 확인 & 호출
• 내부 load balancer가 내부 측정기준을 사용해서 가용한
인스턴스들 간의 부하 균형(예, 인스턴스의 반응시간)
• 외부 load balancer없이 클라이언트마다 개별 부하 분산 메커니즘
사용
Service Registry에서
A 서비스 중에서 활성화된
인스턴스 (active instance)를
가져와서 그 중에 하나 선택
20.
[MP9] Introduce ExternalLoad Balancer
20
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Amazon ELB, Nginx, HAProxy, Eureka
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Service Discovery 설정
• 수많은 서비스 인스턴스 & 개별 서비스는 다른 서비스의
클라이언트
Reuse Intention Introduce Load Balancing between instances of a service using External Load Balancer
Reuse Situation Scalability, High Availability, Dynamicity
• 서비스 코드를 최소한으로 변경하고도 인스턴스 간의 서비스
부하를 분산시키는 방법은?
• 어떻게 하면 중앙집중화된 부하 분산을 할 수 있을까?
• 내부의 측정기준은 부하를 분산시키는 데 소용 없음
• load balancer를 proxy로 쓰려면 고가용성 부하 분산 클러스터
필요
• 중앙집중화된 알고리즘 사용 : Service Discovery에서 가용한
인스턴스의 목록을 가져와서 서비스의 인스턴스 간에 부하 분산
• Proxy 기능(비 추천) 또는 인스턴스 주소 지정자 기능 가능
• 부하 분산 주소 지정자(load balanced address locator) 역할을 하는
Service Discovery 설정
Service Registry에서
A 서비스 중에서 활성화된
인스턴스 (active instance)를
가져옴
21.
[MP10] Introduce CircuitBreaker
21
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Hystrix
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• 사용자 요청사항의 일부는 시스템 내부에서 서비스 간의 통신 필요
Reuse Intention Introduce Fault Tolerance in inter-service communication using Circuit Breaker
Reuse Situation Fault Tolerance, High Availability
• 사용할 수 없는 서비스를 호출했을 때 빨리 실패하게 하여 서비스
호출이 시간 제한(time-out)에 걸릴 때까지 기다리지 않도록 하려면?
• 사용할 수 없는 서비스를 호출할 때 서비스를 대신하여 반응을
내보내 시스템 탄력성을 더 강하게 만들 수 있는 방법은 무엇인가?
• Open Circuit 상태에서 적절한 응답을 인식하는 것은 다소
어려우며 업무 관계자들의 협조 필요
• 서비스 소비자가 서비스를 호출할 때 Circuit Breaker 사용
• Close Circuit state : 서비스가 사용가능한 상태
• Open Circuit state : 서비스 반응을 모니터링하여 반응실패 횟수가
미리 정의한 문턱값을 넘어섰을 때 대응 응답 코드나 예외 반환,
캐싱 데이터 반환 등
• Half-open Circuit state : 시간 제한 이후에는 서비스 가용 여부를
확인하기 위해 서비스에 재접속 Open과 Close 결정/변경
22.
[MP11] Introduce ConfigurationServer
22
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Spring Config Server, Archaius
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• 수많은 서비스 인스턴스
• 사용가능한 인스턴스 목록은 Service Discovery를 통해 제공
Reuse Intention Change a system’s configuration at runtime using Configuration Server
Reuse Situation Modifiability, Dynamicity, Deployment
• 실행중인 인스턴스 구성을 재배포하지 않고도 수정하는 방법은?
• 서비스 내에서 설정 정보 전파의 종착점(endpoint)과 사용 중인
모든 프로그래밍 언어에 대해 적응 전략을 구현
• 소스 코드와 소프트웨어 설정사항을 각각 저장할 두 개의 분리된
저장소가 별도로 마련
• 설정 저장소(configuration repository)에 변경 사항이 발생하면 이를
기준으로 실행되는 인스턴스에 전파되어야 하며 인스턴스는 그에
따라 스스로 적응
각 인스턴스는 구동시에 해당 설정
정보를 가져옴
나중에 변경된 설정정보는
실행중인 인스턴스에 push되며, 각
인스턴스는 스스로 알아서 적용
23.
[MP12] Introduce EdgeServer
23
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Zuul
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• 서비스의 초기화가 쉽기 때문에 새로운 서비스를 쉽게 도입
• 기존의 서비스도 새로운 요구사항에 맞게 재구성(re-architect) 쉬움
Reuse Intention Enable Dynamic Re-routing of external requests to internal services using Edge Server
Reuse Situation Modifiability, Dynamicity
• 최종사용자에게 서비스 내부 구조나 변화내용을 안보이게 하는
방법?
• 서비스 사용량과 전반적인 상태를 모니터링할 수 있는 방법은?
• 모든 트래픽이 통과하므로 single-point-of-failure 위험 부하 분산
메커니즘을 이용해 복제 필요
• 시스템의 출입문 역할을 하는 간접적인 층, Edge Server 도입
• 미리 정의된 설정사항에 따라서 동적인 트래픽 배분 역할
• 서비스 인스턴스의 주소는 하드 코딩하거나 Service Discovery에서
• 최종사용자는 이 층과만 인터페이스 : 내부 변경에 영향받지 않음
• 모든 트래픽이 통과하므로 전반적인 모니터링하기에 최적
24.
[MP13] Containerize theServices
24
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Docker
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Continuous Integration pipeline이 구축되어 작동 중
• 개발환경과 운영환경의 차이 때문에 같은 코드, 다른 결과
Reuse Intention Have the same behavior in development and production environment using Containerization
Reuse Situation Resource-efficiency, Deployment
• 개발/운영환경에서 같은 코드가 같은 결과를 가져오게 하는 방법은?
• 설정관리 도구의 복잡성과 수작업 배포의 어려움을 없앨 방법은?
• 컴퓨팅 자원의 과소비 : 가상화로 인해 서비스 격리에 많은 자원
소요
• 배포할 때 컨테이너라는 층을 하나 더 얹음 복잡도 증가
• 격리된 VM에서 서비스를 개별 배포, 설정 관리 도구로 필요 환경
제공
• 컨테이너 이미지 활용 설정관리 도구 불필요
• Continuous Integration pipeline에 컨테이너 이미지 구성(build)단계
추가 개별 이미지 저장소에 저장하여 운영/개발 환경에 실행
• 각 서비스는 서비스 컨테이너를 실행하기 위한 스크립트 소유
• 서비스 실행을 위한 환경변수 목록 관리 누구나 변수의 변화
감지
25.
[MP14] Deploy intoa Cluster and Orchestrate Containers
25
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Mesos+Marathon, Kubernetes
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Continuous Integration pipeline이 구축 컨테이너 이미지 사용
• 서비스 숫자가 많아서 배포와 재배포가 복잡하고 관리 어려움
Reuse Intention Deploy service instances’ container images in a cluster using cluster management tools
Reuse Situation Resource-efficiency, Deployment
• 서비스 인스턴스를 클러스터에 배포하는 방법은?
• 최소의 노력으로 모든 서비스의 배포와 재배포를 조율하는 방법은?
• 컴퓨팅 노드의 클러스터를 관리할 수 있는 시스템 도입
- 필요에 따라 특정 인스턴스나 다른 노드에 컨테이너 이미지 배포
- 인스턴스의 장애 처리, 재시작
- 서비스를 자동 확장(auto-scaling)할 수 있는 수단 제공
- Service Discovery 같은 일부 서비스는 IP 주소 대신 이름으로
식별되어야 하므로 내부 (서비스)이름 확인 전략을 사용
• 배포 절차를 효과적으로 조율하기 위해서 서비스의 배포
아키텍처를 명시적으로 정의할 수 있는 수단을 제공
• 자동 확장, 서비스 장애관리 등은 클러스터 관리 도구가 수행
26.
[MP15] Monitor theSystem and Provide Feedback
26
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Collectd + Logstash + ElasticSearch + Kibana
• MSA 스타일로 소프트웨어 시스템 구축
• 운영계의 개별 서비스가 여러 개의 인스턴스를 갖는 컨테이너
클러스터에서 실행
Reuse Intention Monitor the running services’ instances and Provide feeback to the development team
Reuse Situation Monitoring, Modifiability
• Infrastructure는 어떻게 모니터링 할 것인가?
• 개발팀에 피드백하여 시스템을 재구성(re-architect)하는 방법은?
• 개별 서비스는 해당 서비스 관리팀의 운영(Ops) 파트가 직접 관리
• CPU와 RAM 사용량과 같은 모니터링 정보를 수집하여 모니터링
서버에 전달
• 모니터링 서버 : 정보들을 구문 분석하고 구조화된 정보 형태로
집계
• 인덱싱 서버 : 집계된 정보 저장 효율적으로 쿼리
• 모니터링 정보는 통해 서비스 개발(Dev) 파트가 성능 병목현상이나
기타 이상 현상을 제거하기 위해 아키텍처를 리팩토링하는 데 활용
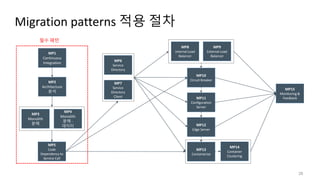
이행 패턴의 선택과작성
• 이행 패턴의 초기 버전을 통해 현재 진행중인 이행 프로젝트를 위한 이행 계획
수립
1) 이행의 동인과 요구사항을 식별
2) 식별된 요구사항을 이행 패턴 표1에서 설명한 선택 요인(factor)와 맞춤
3) 관련 선택 요인을 기반으로 초기 버전이 제공하는 핵심 개념, Reuse Intention, 문제점 등을 고려하여
가장 적합한 패턴을 선택함으로써 일련의 이행 패턴을 도출
4) 각각의 패턴을 사용하는 맥락(Context)을 확인
5) 일련의 패턴들을 선택하여 이행 계획을 구성
• 다형성(polyglot-ness)에 대한 필요에 따라서 분해 패턴을 찾고, 그 다음에
프로젝트 도메인의 복잡성에 따라서 가장 적합한 패턴을 선택
• 저장소에서 적합한 이행 패턴을 선택한 다음에는, 요구사항과 프로젝트 상황,
제약사항(예, 시간, 인적/물적 예산 등)에 따라서 선택된 패턴으로 이행 패턴
작성
30
새 패턴 추가하기
•Microservices는 아직 미성숙 단계이므로 이행 패턴의 완성도도 미흡한 상태
• 대신, microservices로 이행하는 새로운 경험을 통해 일반화된 새로운 이행
패턴을 추가함으로써 패턴 저장소를 확장
• 패턴을 정의할 때 메타 모델, 몇몇 선택 요인, 그리고 패턴의 내용(granularity)를
결정하는 요인들을 제공 메타 모델에 부합되도록 하고 패턴 저장소 강화
• 새로운 선택 요인이 필요하면 현재의 선택요인에 추가
32
[첨부] Continuous Integrationserver
1. Cl Server
• 빌드 프로세스를 관리하는 서버
• Jenkins, Hudson, CruiseControl.NET. TeamCity
2. SCM(Source Code Management)
• 소스코드 형상관리 시스템 : 소스코드의 개정과 백업 절차를
자동화하여 오류 수정 과정을 도와줄 수 있는 시스템
• 프로젝트 내에서 각자가 수정한 부분을 팀원 전체가 자동으로 동기화
• Subversion, Git, Mercurial
3. Build Tool
• 검파일. 테스트. 정적분석 등을 실시해 동작 가능한 소프트웨어를
생성
• Ant Maven. MSBuild. Make
4. Test Tool
• 테스트 코드에 따라 자동으로 테스트를 수행하는 도구. 빌드 툴의
스크립트에서 실행
• Unit. CppTest. MSTest, Selenium(사용자테스트 자동화 가능)
5. Test Coverage tool
• 테스트 코드가 대상 소스 코드에 다하 어느정도 커버하는지 분석하는
도구
• Emma, Cobertura, TestCocoon
6. Inspection Tool
• 프로그램을 실행하지 않고. 소스코드 자제로 품질을 판단할 수 있는
정적분석 도구
• 코딩 표준 준수, 코드 메트릭 측정. 중복코드. 코드 인스펙션 등 검사
• CheckStyle, FindBugs, Cppcheck, Valgrind
34
<출처> http://happystory.tistory.com/89
CI 서버란?
형상관리 서버에 Commit된 소스코드를 주기적으로 폴링하여
컴파일, 단위테스트, 코드 인스펙션 등의 과정을 수행하며 신규
또는 수정된 소스코드가 결함이 있는지 여부를 지속적으로 검증
검증 결과는 이메일, RSS 등을 통해 개발자들에게 전달
CI 시스템 구축을 위한 핵심 구성요소
Editor's Notes
#6 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#7 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#8 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#10 DevOps => “피자 두 판 팀“
민첩하면서도 독립적인, 서로 신뢰하고 오너십을 가진 소규모의 서비스 팀
예) 아마존 AWS는 Appllo를 사용하여 1년간 약 5천만 번의 개발/테스트/배포 수행(=초당 1회)
#12 Gitlab : Gitlab은 Git의 원격 저장소(또는 설치형) 기능과 이슈 트래커 기능 등을 제공하는 소프트웨어. 설치형 Github라는 컨셉으로 시작된 프로젝트이기 때문에 Github와 비슷
Artifactory : 보안, 클러스터, 고가용성 Docker registry를 제공하는 기업용 라이브러리 공유저장소관리 솔루션. 개발계부터 운영계까지 모든 결과물 추적 관리 솔루션
Nexus : repository 관리 솔루션
Jenkins : CI (Continuous Integration)를 위한 소스 배포 관리 솔루션. 구성원들이 각각 작업한 내용(소스코드)을 정기적으로 통합.
GoCD : Open source continuous delivery server to model and visualize complex workflows with ease
Travis : GitHub과 연동해 지속적 통합(Continuous Integration)을 호스팅해주는 서비스. GitHub 저장소에 새로운 커밋이 push되었을 때 CI 서버가 뒤에서 자동으로 새로운 커밋을 가져와서 빌드 테스트를 수행하고, 그 결과를 리포팅 해주는 서비스
Bamboo : 빌드, 테스트, 릴리즈를 워크플로우로 묶어서 자동화한 솔루션. JIRA Software, Bitbucket, Fisheye 및 HipChat과의 최적의 통합
Teamcity : 빌드자동화 솔루션
#13 Gitlab : Gitlab은 Git의 원격 저장소(또는 설치형) 기능과 이슈 트래커 기능 등을 제공하는 소프트웨어. 설치형 Github라는 컨셉으로 시작된 프로젝트이기 때문에 Github와 비슷
Artifactory : 보안, 클러스터, 고가용성 Docker registry를 제공하는 기업용 라이브러리 공유저장소관리 솔루션. 개발계부터 운영계까지 모든 결과물 추적 관리 솔루션
Nexus : repository 관리 솔루션
Jenkins : CI (Continuous Integration)를 위한 소스 배포 관리 솔루션. 구성원들이 각각 작업한 내용(소스코드)을 정기적으로 통합.
GoCD : Open source continuous delivery server to model and visualize complex workflows with ease
Travis : GitHub과 연동해 지속적 통합(Continuous Integration)을 호스팅해주는 서비스. GitHub 저장소에 새로운 커밋이 push되었을 때 CI 서버가 뒤에서 자동으로 새로운 커밋을 가져와서 빌드 테스트를 수행하고, 그 결과를 리포팅 해주는 서비스
Bamboo : 빌드, 테스트, 릴리즈를 워크플로우로 묶어서 자동화한 솔루션. JIRA Software, Bitbucket, Fisheye 및 HipChat과의 최적의 통합
Teamcity : 빌드자동화 솔루션
#14 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#15 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#16 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#17 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#18 Eureka : Eureka is a REST (Representational State Transfer) based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers.
Consul : a distributed, highly available, datacenter-aware, service discovery and configuration system.
Apache Zookeeper : a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services
#19 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#20 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#21 Amazon ELB : Elastic Load Balancing
Nginx : 웹서버 소프트웨어로 웹서버, 리버스 프록시 및 메일 프록시 기능. 쓰레드 기반이 아닌 이벤트 기반
HAProxy : L4/L7 의 기능을 제공하는 소프트웨어 로드 밸런서
Eureka
#22 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#23 Netflex Archaius : a configuration management library with a focus on Dynamic Properties sourced from multiple configuration stores.
includes a set of java configuration management APIs used at Netflix.
#24 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#25 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#26 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#27 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#29 Describe differences between monolithic and microservices architecture in terms of number of services and scalability mechanisms
#31 Describe SSaaS as a Mobile Backend as a Service through which mobile development time will be reduced and briefly mention its features
#33 Describe SSaaS as a Mobile Backend as a Service through which mobile development time will be reduced and briefly mention its features








![[MP1] Enable Continuous Integration
11
Technology Stack
Gitlab, Artifactory, Nexus, Jenkins, GoCD, Travis, Bamboo,
Teamcity
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
• Microservices로 이행하기 위한 소프트웨어 시스템이 있고 그것을
개발/운영하는 팀이 존재
• microservices를 도입 후 수많은 서비스를 어떻게 항상 대기상태
유지?
• Continuous Delivery를 도입할 수 있도록 시스템을 준비하는 방법?
• code repository, artifact repository, Continuous Integration server
도입
• 서비스는 분리된 저장소에 : 개별 이력과 빌드 라이프 사이클 관리
• 서비스의 code repository가 변경될 때마다 서비스별 Continuous
Integration job이 자동 실행 : repository 에서 새로운 코드를
가져오고, 테스트하고, 결과물을 만들어 artifact repository 등록
• 오류 발생시 오류를 전달받은 관련팀(서비스)은 오류가 해결될
때까지 모든 작업 정지
• 새로운 변경사항은 시스템의 안정성을 깨뜨릴 수 있으므로 반드시
미리 정의된 모든 테스트를 수행
Reuse Intention Build the Continuous Integration pipeline
Reuse Situation Deployment](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-11-320.jpg)
![[참고] Continuous Integration이란?
12
CI(Continuous Integration : 지속적인 통합)
• 지속적으로 소프트웨어 품질 관리를 적용하는 프로세스를 실행하는 것.
• 모든 가발을 완료한 뒤에 퀄리티 컨트롤을 적용하는 고전적인 방법을 대체하는 방법으로서 소프트웨어의
질적 향상과 소프트웨어를 배포하는데 걸리는 시간을 줄이는데 초점
• 초기에 그리고 자주 통합해서 통합 시 발생하는 여러가지 문제점을 조기에 발견하고, 피드백 사이클을 짧게
하여 소프트웨어 개발의 품질과 생산성을 향상시기는 것.](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-12-320.jpg)
![[MP2] Recover the Current Architecture
13
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
• 현재 운영하는 소프트웨어 시스템을 microservices로 이행 결정
• 이행 계획을 세우기 위해 아키텍처 파악, 분석
• 시스템의 청사진(big picture)은 무엇인가?
• 이행계획에 필요한 high-level 정보는 충분한가?
• Component and Service Architecture
- 아키텍처를 시각화 하여 설명 이해도 향상
- 각 구성요소의 내부 도메인 상세 내역 이해
• Technology Architecture:
- 현재 Technology stack에 대한 이해 : 아키텍처/비아키텍처 기능
- 언어, DB, 미들웨어, 라이브러리 등 모두 나열
• Deployment Architecture and Procedure
- 아키텍처 이해 과정에 개발팀과 운영팀 참가 공통된 이해
- 문서화는 이행 후에
Reuse Intention Create Migration Plan initial state
Reuse Situation Understanding](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-13-320.jpg)
![[MP3] Decompose the Monolith
14
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
N/A
단점 (Challenge)
• 복잡한 도메인을 갖고 있는 통짜구조(monolithic) 소프트웨어
시스템 : 시스템 복잡, 영역별 별도의 비기능 요건, 변경시 전체
재배포
Reuse Intention Re-architect a System to a set of services using Domain-driven Design
Reuse Situation Polyglot-ness, Decomposition, Modifiability
• 시스템을 더 작은 단위로 분해하는 방법은 무엇인가?
• 이 단위들은 어느 정도로 커야 하는가?
• 잘못된 시스템 분해 이행 과정 중 미해결 우려 성능저하 문제
• Domain-Driven Design (DDD) 기법 사용하여 서비스로 분해
- 시스템의 초기 분해에 사용
- DDD를 하위 도메인에 적용하여 더 작은 도메인 단위로 분해
• 각 도메인은 개별 배포 단위인 Bounded Context (BC) 구성 : 1:1
대응
• BC의 크기는 시스템 요구사항에 유동적으로 구성
• 처음에는 2~3개의 서비스로 시작 시스템이 커지고 팀의
이해도가 높아진 다음에 서비스들을 추가](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-14-320.jpg)
![[MP4] Decompose the Monolith Based on Data Ownership
15
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
N/A
단점 (Challenge)
• 복잡한 도메인을 갖고 있는 통짜구조(monolithic) 소프트웨어
시스템 : 시스템 복잡, 영역별 별도의 비기능 요건, 변경시 전체
재배포
Reuse Intention Re-architect a System to a set of services using Data Ownership
Reuse Situation Polyglot-ness, Decomposition, Modifiability
• 시스템을 더 작은 단위로 분해하는 방법은 무엇인가?
• 이 단위들은 어느 정도로 커야 하는가?
• 도메인이 매우 커서 여러 개의 하위 도메인을 갖는 경우에는
혼란스럽고 시간을 많이 잡아먹어서 적절한 분해를 할 수 없음
• 데이터의 소유권 여부에 따라서 시스템을 분해
• 하나의 단위로 결합 가능하고 단일 소유자인 데이터 개체의 집합을
그것이 지원하는 비즈니스 로직과 묶어 패키지화 함
• 다른 서비스는 자신의 소유가 아닌 개체의 복사본만 소유 적절한
동기화 필요
• 시스템에 있는 개체(entity)의 크기와 수에 의해 결정 : 도메인이
복잡하지 않으면 4~5개 정도
개별 개체는 그 서비스를
담당하는 소유자에
의해서만 수정되거나 생성](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-15-320.jpg)
![[MP5] Change Code Dependency to Service Call
16
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
N/A
단점 (Challenge)
• 소프트웨어 시스템은 microservices 아키텍처 스타일을 사용할 수
있도록 일련의 작은 서비스들로 분해되어 있으나 시스템의 어떤
구성 요소는 여전히 다른 서비스나 구성요소에 의존해서 실행
Reuse Intention Transform code-level dependency to service-level dependency
Reuse Situation Decomposition, Modifiability
• 코드 수준의 의존성을 서비스 수준의 의존성으로 바꾸는 적절한
시기?
• 적절하지 않은 때는 언제인가?
• 라이브러리의 종속성을 제거하고 메서드 호출 대신 서비스 호출을
사용하는 것은 때로는 성능 문제 야기
• 가능한 서비스 코드는 별도로 유지 : 서비스간 코드 종속성 배재
• 내부 개체나 인터페이스 스키마를 공유는 금지
• 거의 변경되지 않는 공통 라이브러리로 공유되는 코드(예 : 문자열
조작 라이브러리)는 공유하는 것이 합리적
• 공유하기 어려운 기능은 서비스로 만들어 공유](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-16-320.jpg)
![[MP6] Introduce Service Discovery
17
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Eureka, Consul, Apache Zookeeper, etc
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• 각 서비스는 운영 환경에 하나 이상의 인스턴스가 배포
• 서비스의 인스턴스의 수는 동적으로 변경 & 다른 시스템에도 배포
가능
Reuse Intention Introduce Dynamic Location of services’ instances using Service Discovery
Reuse Situation Scalability, High Availability, Dynamicity, Deployment
• 어떻게 서비스가 각기 동적으로 자리를 잡을 수 있을까?
• Edge Server나 Load Balancer는 어떻게 서비스의 인스턴스 목록을
알 수 있을까?
• SD는 서비스간 통신의 구심점이므로 여기가 잘못되면 Single-
point-of-failure
• 서비스 인스턴스의 주소를 저장하는 Service Discovery를 설정
• 개별 서비스 스스로 Registry에 등록 : 인스턴스로부터 주기적인
신호가 없거나 종료될 때 자동으로 해당 인스턴스가 registry에서
제거
• Edge Server, Load Balancer, 타 서비스는 Service Discovery를
통해 가용한 서비스 인스턴스의 목록을 받아서 필요한 서비스를
탐색
Service Discovery는 시스템의 핵심
구성요소이자 가용성이 매우 중요
복제 전략 필요](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-17-320.jpg)
![[MP7] Introduce Service Discovery Client
18
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Eureka는 서버 버전용 Java 클라이언트가 설치된 Service
Discovery
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Service Discovery 설정
• 서비스의 인스턴스의 수는 동적으로 변경 & 다른 시스템에도 배포
가능
Reuse Intention Facilitate Dynamic Location of services’ instances using Service Discovery Client
Reuse Situation Scalability, High Availability, Dynamicity, Deployment
• Service Discovery는 새로운 인스턴스가 배포되었다는 것을 어떻게
알 수 있을까?
• 인스턴스가 종료되었다는 것은 어떻게 알 수 있을까?
• 사용중인 모든 프로그래밍 언어에 대해 클라이언트를 설치해야
하며 잘못 설치하면 서비스 코드가 복잡해짐
• 개별 서비스는 Service Discovery 주소를 알아야 하고 초기화되는
동안에 registry에 자체 등록
• 개별 인스턴스에서 registry로 주기적으로 신호(heartbeat)를
보내야만 사용가능한 인스턴스 목록에 계속 유지
• 종료 : 신호를 보내지 않거나 registry에 인스턴스 종료를 알림
서비스마다 클라이언트 설치
서비스를 자체 등록하고
Registry에 계속 신호 보냄](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-18-320.jpg)
![[MP8] Introduce Internal Load Balancer
19
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Ribbon은 Service Discovery인 Eureka와 잘 맞는 Java용
내부 load balancer
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Service Discovery 설정
• 수많은 서비스 인스턴스 & 개별 서비스는 다른 서비스의
클라이언트
Reuse Intention Introduce Load Balancing between instances of a service using Internal Load Balancer
Reuse Situation Scalability, High Availability, Dynamicity
• 클라이언트의 조건에 따라 인스턴스 간에 어떻게 서비스 부하의
균형을 맞출 수 있을까?
• 외부 load balancer 없이 서비스의 부하 균형을 맞추는 방법은?
• SD와 통합될 수 있는 프로그래밍 언어용 내부 load balancer 생성
• 부하 분산 메커니즘이 중앙집중화되지 못함
• 내부에 load balancer를 가진 서비스가 SD에서 가용한 인스턴스
목록 확인 & 호출
• 내부 load balancer가 내부 측정기준을 사용해서 가용한
인스턴스들 간의 부하 균형(예, 인스턴스의 반응시간)
• 외부 load balancer없이 클라이언트마다 개별 부하 분산 메커니즘
사용
Service Registry에서
A 서비스 중에서 활성화된
인스턴스 (active instance)를
가져와서 그 중에 하나 선택](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-19-320.jpg)
![[MP9] Introduce External Load Balancer
20
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Amazon ELB, Nginx, HAProxy, Eureka
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Service Discovery 설정
• 수많은 서비스 인스턴스 & 개별 서비스는 다른 서비스의
클라이언트
Reuse Intention Introduce Load Balancing between instances of a service using External Load Balancer
Reuse Situation Scalability, High Availability, Dynamicity
• 서비스 코드를 최소한으로 변경하고도 인스턴스 간의 서비스
부하를 분산시키는 방법은?
• 어떻게 하면 중앙집중화된 부하 분산을 할 수 있을까?
• 내부의 측정기준은 부하를 분산시키는 데 소용 없음
• load balancer를 proxy로 쓰려면 고가용성 부하 분산 클러스터
필요
• 중앙집중화된 알고리즘 사용 : Service Discovery에서 가용한
인스턴스의 목록을 가져와서 서비스의 인스턴스 간에 부하 분산
• Proxy 기능(비 추천) 또는 인스턴스 주소 지정자 기능 가능
• 부하 분산 주소 지정자(load balanced address locator) 역할을 하는
Service Discovery 설정
Service Registry에서
A 서비스 중에서 활성화된
인스턴스 (active instance)를
가져옴](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-20-320.jpg)
![[MP10] Introduce Circuit Breaker
21
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Hystrix
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• 사용자 요청사항의 일부는 시스템 내부에서 서비스 간의 통신 필요
Reuse Intention Introduce Fault Tolerance in inter-service communication using Circuit Breaker
Reuse Situation Fault Tolerance, High Availability
• 사용할 수 없는 서비스를 호출했을 때 빨리 실패하게 하여 서비스
호출이 시간 제한(time-out)에 걸릴 때까지 기다리지 않도록 하려면?
• 사용할 수 없는 서비스를 호출할 때 서비스를 대신하여 반응을
내보내 시스템 탄력성을 더 강하게 만들 수 있는 방법은 무엇인가?
• Open Circuit 상태에서 적절한 응답을 인식하는 것은 다소
어려우며 업무 관계자들의 협조 필요
• 서비스 소비자가 서비스를 호출할 때 Circuit Breaker 사용
• Close Circuit state : 서비스가 사용가능한 상태
• Open Circuit state : 서비스 반응을 모니터링하여 반응실패 횟수가
미리 정의한 문턱값을 넘어섰을 때 대응 응답 코드나 예외 반환,
캐싱 데이터 반환 등
• Half-open Circuit state : 시간 제한 이후에는 서비스 가용 여부를
확인하기 위해 서비스에 재접속 Open과 Close 결정/변경](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-21-320.jpg)
![[MP11] Introduce Configuration Server
22
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Spring Config Server, Archaius
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• 수많은 서비스 인스턴스
• 사용가능한 인스턴스 목록은 Service Discovery를 통해 제공
Reuse Intention Change a system’s configuration at runtime using Configuration Server
Reuse Situation Modifiability, Dynamicity, Deployment
• 실행중인 인스턴스 구성을 재배포하지 않고도 수정하는 방법은?
• 서비스 내에서 설정 정보 전파의 종착점(endpoint)과 사용 중인
모든 프로그래밍 언어에 대해 적응 전략을 구현
• 소스 코드와 소프트웨어 설정사항을 각각 저장할 두 개의 분리된
저장소가 별도로 마련
• 설정 저장소(configuration repository)에 변경 사항이 발생하면 이를
기준으로 실행되는 인스턴스에 전파되어야 하며 인스턴스는 그에
따라 스스로 적응
각 인스턴스는 구동시에 해당 설정
정보를 가져옴
나중에 변경된 설정정보는
실행중인 인스턴스에 push되며, 각
인스턴스는 스스로 알아서 적용](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-22-320.jpg)
![[MP12] Introduce Edge Server
23
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Zuul
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• 서비스의 초기화가 쉽기 때문에 새로운 서비스를 쉽게 도입
• 기존의 서비스도 새로운 요구사항에 맞게 재구성(re-architect) 쉬움
Reuse Intention Enable Dynamic Re-routing of external requests to internal services using Edge Server
Reuse Situation Modifiability, Dynamicity
• 최종사용자에게 서비스 내부 구조나 변화내용을 안보이게 하는
방법?
• 서비스 사용량과 전반적인 상태를 모니터링할 수 있는 방법은?
• 모든 트래픽이 통과하므로 single-point-of-failure 위험 부하 분산
메커니즘을 이용해 복제 필요
• 시스템의 출입문 역할을 하는 간접적인 층, Edge Server 도입
• 미리 정의된 설정사항에 따라서 동적인 트래픽 배분 역할
• 서비스 인스턴스의 주소는 하드 코딩하거나 Service Discovery에서
• 최종사용자는 이 층과만 인터페이스 : 내부 변경에 영향받지 않음
• 모든 트래픽이 통과하므로 전반적인 모니터링하기에 최적](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-23-320.jpg)
![[MP13] Containerize the Services
24
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Docker
단점 (Challenge)
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Continuous Integration pipeline이 구축되어 작동 중
• 개발환경과 운영환경의 차이 때문에 같은 코드, 다른 결과
Reuse Intention Have the same behavior in development and production environment using Containerization
Reuse Situation Resource-efficiency, Deployment
• 개발/운영환경에서 같은 코드가 같은 결과를 가져오게 하는 방법은?
• 설정관리 도구의 복잡성과 수작업 배포의 어려움을 없앨 방법은?
• 컴퓨팅 자원의 과소비 : 가상화로 인해 서비스 격리에 많은 자원
소요
• 배포할 때 컨테이너라는 층을 하나 더 얹음 복잡도 증가
• 격리된 VM에서 서비스를 개별 배포, 설정 관리 도구로 필요 환경
제공
• 컨테이너 이미지 활용 설정관리 도구 불필요
• Continuous Integration pipeline에 컨테이너 이미지 구성(build)단계
추가 개별 이미지 저장소에 저장하여 운영/개발 환경에 실행
• 각 서비스는 서비스 컨테이너를 실행하기 위한 스크립트 소유
• 서비스 실행을 위한 환경변수 목록 관리 누구나 변수의 변화
감지](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-24-320.jpg)
![[MP14] Deploy into a Cluster and Orchestrate Containers
25
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Mesos+Marathon, Kubernetes
• 소프트웨어 시스템은 작은 서비스들로 분해되어 있으며,
• Continuous Integration pipeline이 구축 컨테이너 이미지 사용
• 서비스 숫자가 많아서 배포와 재배포가 복잡하고 관리 어려움
Reuse Intention Deploy service instances’ container images in a cluster using cluster management tools
Reuse Situation Resource-efficiency, Deployment
• 서비스 인스턴스를 클러스터에 배포하는 방법은?
• 최소의 노력으로 모든 서비스의 배포와 재배포를 조율하는 방법은?
• 컴퓨팅 노드의 클러스터를 관리할 수 있는 시스템 도입
- 필요에 따라 특정 인스턴스나 다른 노드에 컨테이너 이미지 배포
- 인스턴스의 장애 처리, 재시작
- 서비스를 자동 확장(auto-scaling)할 수 있는 수단 제공
- Service Discovery 같은 일부 서비스는 IP 주소 대신 이름으로
식별되어야 하므로 내부 (서비스)이름 확인 전략을 사용
• 배포 절차를 효과적으로 조율하기 위해서 서비스의 배포
아키텍처를 명시적으로 정의할 수 있는 수단을 제공
• 자동 확장, 서비스 장애관리 등은 클러스터 관리 도구가 수행](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-25-320.jpg)
![[MP15] Monitor the System and Provide Feedback
26
적용 상황 (Context)
의문 사항 (Problem)
해결 방안 (Solution)
Technology Stack
Collectd + Logstash + ElasticSearch + Kibana
• MSA 스타일로 소프트웨어 시스템 구축
• 운영계의 개별 서비스가 여러 개의 인스턴스를 갖는 컨테이너
클러스터에서 실행
Reuse Intention Monitor the running services’ instances and Provide feeback to the development team
Reuse Situation Monitoring, Modifiability
• Infrastructure는 어떻게 모니터링 할 것인가?
• 개발팀에 피드백하여 시스템을 재구성(re-architect)하는 방법은?
• 개별 서비스는 해당 서비스 관리팀의 운영(Ops) 파트가 직접 관리
• CPU와 RAM 사용량과 같은 모니터링 정보를 수집하여 모니터링
서버에 전달
• 모니터링 서버 : 정보들을 구문 분석하고 구조화된 정보 형태로
집계
• 인덱싱 서버 : 집계된 정보 저장 효율적으로 쿼리
• 모니터링 정보는 통해 서비스 개발(Dev) 파트가 성능 병목현상이나
기타 이상 현상을 제거하기 위해 아키텍처를 리팩토링하는 데 활용](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-26-320.jpg)





![[첨부] Continuous Integration server
1. Cl Server
• 빌드 프로세스를 관리하는 서버
• Jenkins, Hudson, CruiseControl.NET. TeamCity
2. SCM(Source Code Management)
• 소스코드 형상관리 시스템 : 소스코드의 개정과 백업 절차를
자동화하여 오류 수정 과정을 도와줄 수 있는 시스템
• 프로젝트 내에서 각자가 수정한 부분을 팀원 전체가 자동으로 동기화
• Subversion, Git, Mercurial
3. Build Tool
• 검파일. 테스트. 정적분석 등을 실시해 동작 가능한 소프트웨어를
생성
• Ant Maven. MSBuild. Make
4. Test Tool
• 테스트 코드에 따라 자동으로 테스트를 수행하는 도구. 빌드 툴의
스크립트에서 실행
• Unit. CppTest. MSTest, Selenium(사용자테스트 자동화 가능)
5. Test Coverage tool
• 테스트 코드가 대상 소스 코드에 다하 어느정도 커버하는지 분석하는
도구
• Emma, Cobertura, TestCocoon
6. Inspection Tool
• 프로그램을 실행하지 않고. 소스코드 자제로 품질을 판단할 수 있는
정적분석 도구
• 코딩 표준 준수, 코드 메트릭 측정. 중복코드. 코드 인스펙션 등 검사
• CheckStyle, FindBugs, Cppcheck, Valgrind
34
<출처> http://happystory.tistory.com/89
CI 서버란?
형상관리 서버에 Commit된 소스코드를 주기적으로 폴링하여
컴파일, 단위테스트, 코드 인스펙션 등의 과정을 수행하며 신규
또는 수정된 소스코드가 결함이 있는지 여부를 지속적으로 검증
검증 결과는 이메일, RSS 등을 통해 개발자들에게 전달
CI 시스템 구축을 위한 핵심 구성요소](https://image.slidesharecdn.com/cloudmigrationpatternusingmicroservices-170111021929/85/Cloud-migration-pattern-using-microservices-34-320.jpg)












![[오픈소스컨설팅]Data Center to cloud - 최지웅 컨설팅코치, 오픈소스컨설팅](https://cdn.slidesharecdn.com/ss_thumbnails/awssummit2017datacentertocloud-170529054823-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Partner TechShift 2017] APN 컨설팅 파트너사와 함께 하는 클라우드 소프트웨어 사업](https://cdn.slidesharecdn.com/ss_thumbnails/12-171102000046-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS Media Symposium 2019] 고객사례 | SBS Web Service Cloud Migration Process - 김...](https://cdn.slidesharecdn.com/ss_thumbnails/03sbswebservicecloudmigrationprocesssbs-191029011303-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Retail & CPG Day 2019] 마켓컬리 서비스 AWS 이관 및 최적화 여정 - 임상석, 마켓컬리 개발 리더](https://cdn.slidesharecdn.com/ss_thumbnails/kurly-191024042353-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS & 베스핀글로벌, 바이오∙헬스케어∙제약사를 위한 세미나] AWS 101, Cloud Computing is New Normal](https://cdn.slidesharecdn.com/ss_thumbnails/biohealthcareseminarsession03-180614105725-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Cloud migration pattern[한글]](https://cdn.slidesharecdn.com/ss_thumbnails/cloudmigrationpatternko-170111022142-thumbnail.jpg?width=640&height=640&fit=bounds)



![[2017 AWS Startup Day] 서버리스 마이크로서비스로 일당백 개발조직 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/awsstartupday2017-microservicespiljoong-171101081359-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenInfra Days Korea 2018] Day 2 - E6 - 마이크로서비스를 위한 Istio & Kubernetes [다운로드...](https://cdn.slidesharecdn.com/ss_thumbnails/e61700microserviceswithistioandkubernetesfinal-180704062831-thumbnail.jpg?width=640&height=640&fit=bounds)





















