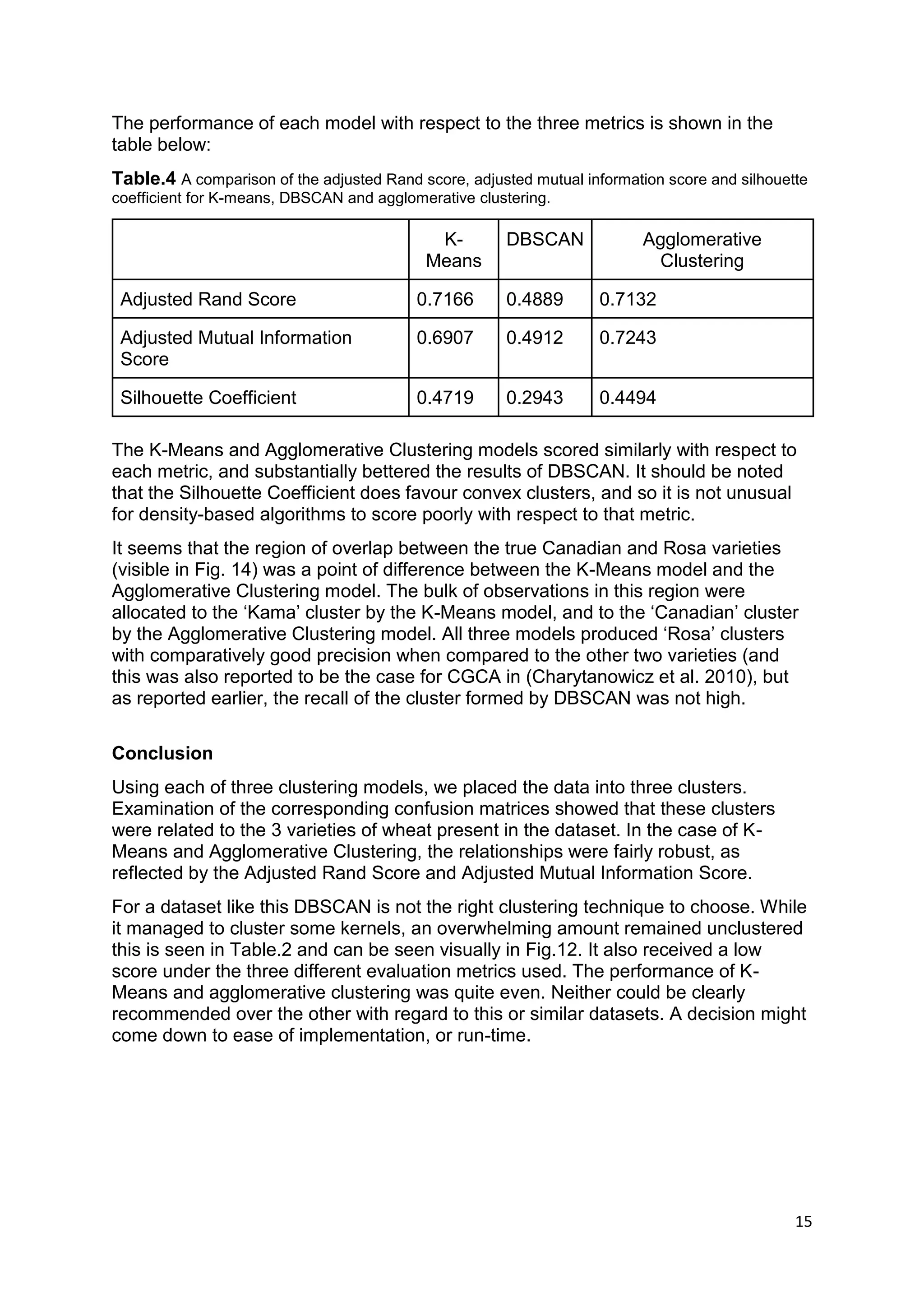
This document summarizes the results of applying three clustering algorithms (K-means, DBSCAN, and Agglomerative Clustering) to a dataset of wheat kernel attributes from three varieties. K-means and Agglomerative Clustering performed similarly well according to evaluation metrics, while DBSCAN struggled to form clear clusters and had many unclustered points. The best models were able to group examples by variety with high precision, though some varieties were less accurately recalled.