Downloaded 13 times



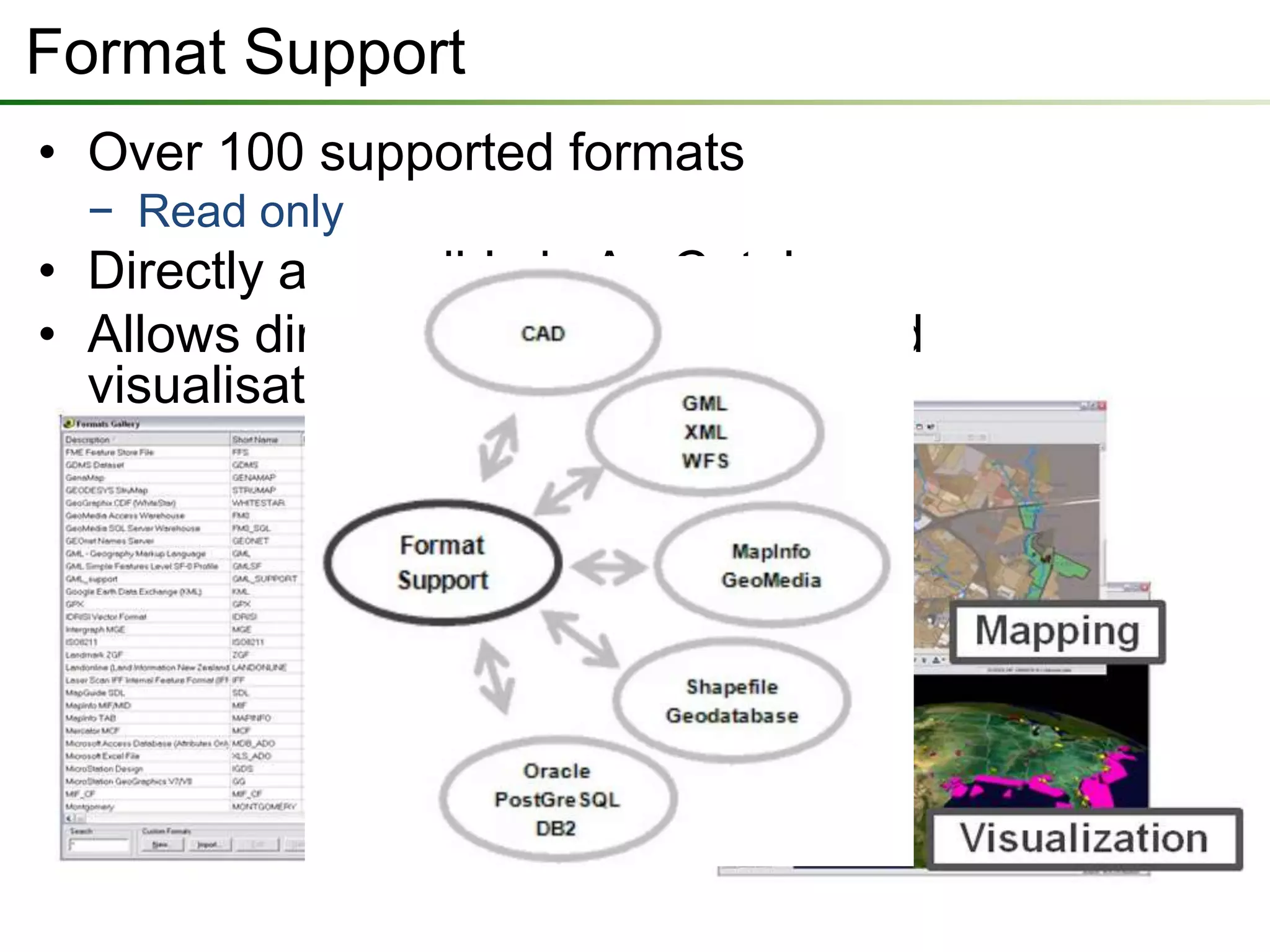
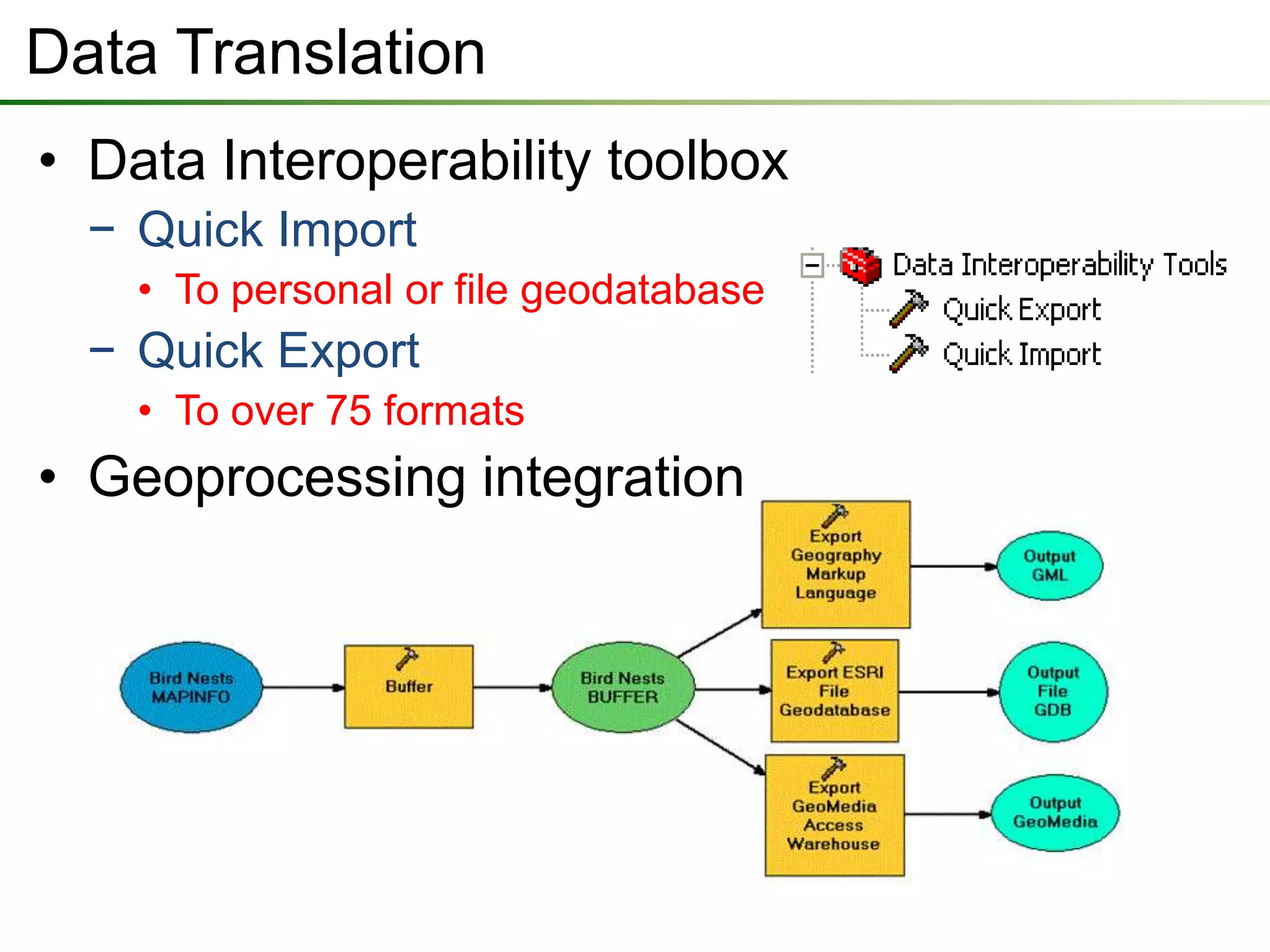

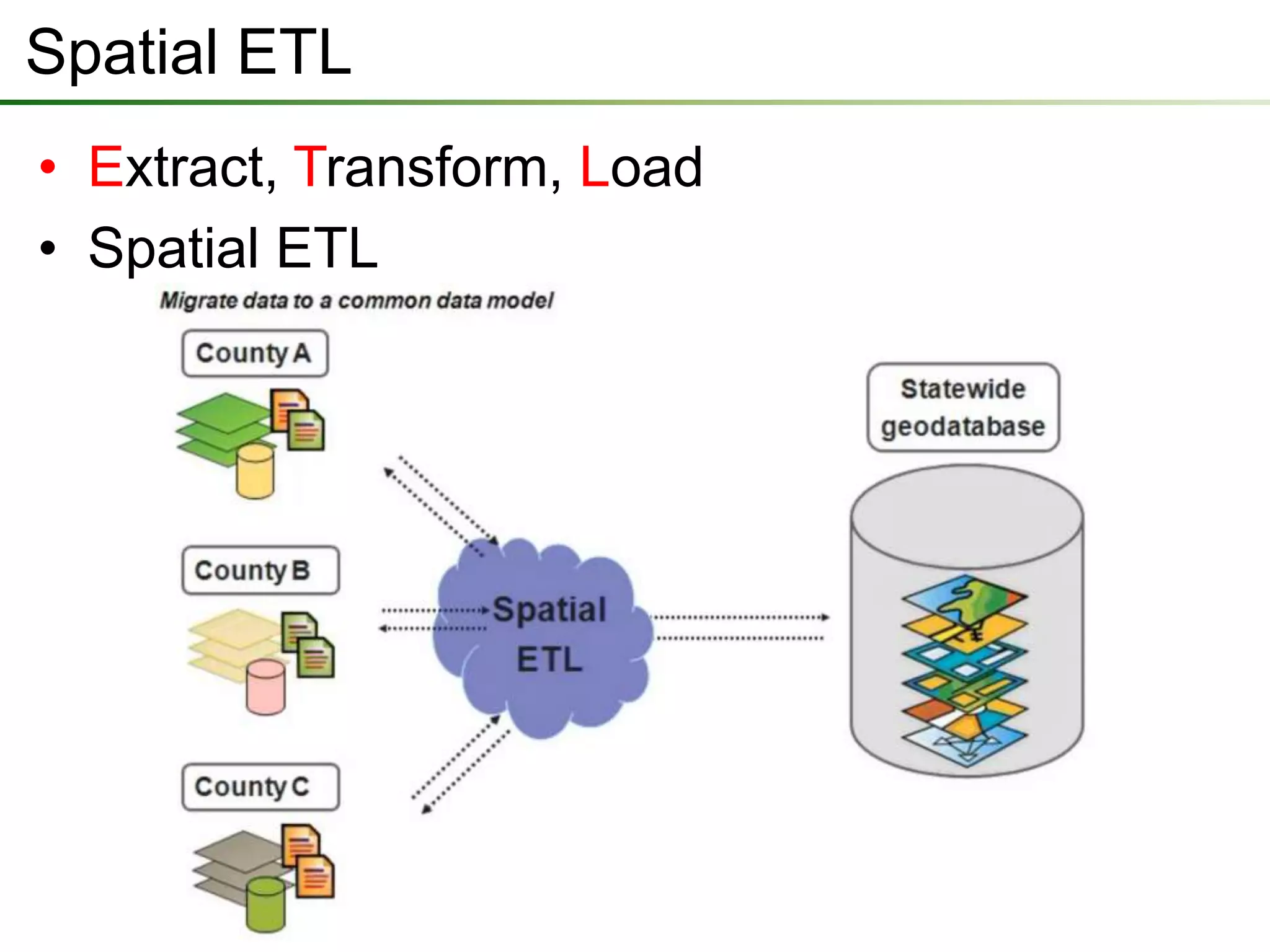
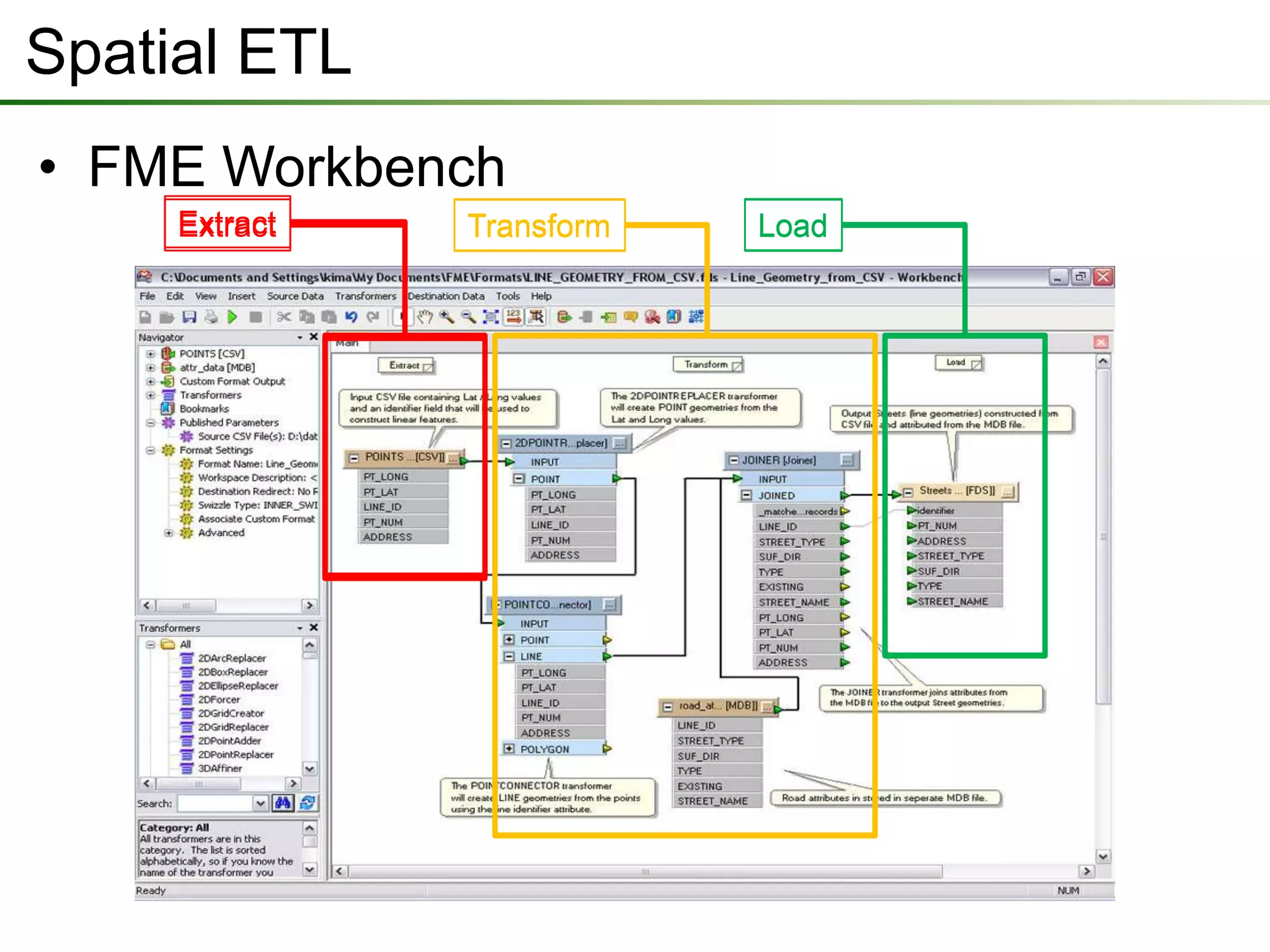

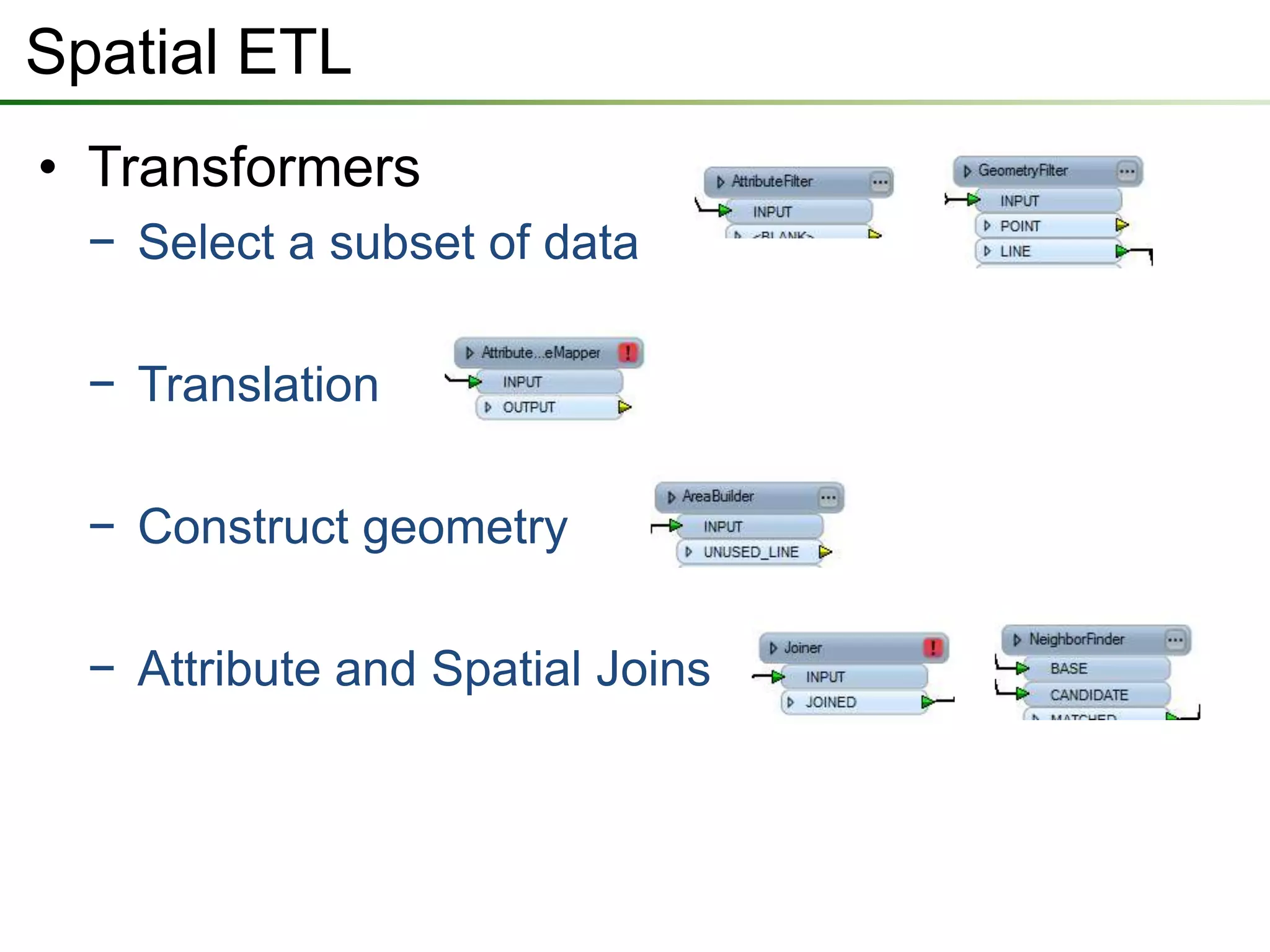



The document outlines a presentation on a data interoperability extension, highlighting its support for over 100 formats and integration with geoprocessing tools using Safe Software's FME technology. It describes functionalities such as data translation, spatial ETL (extract, transform, load), and provides capabilities for direct analysis and visualization. The extension allows efficient data import and export processes while facilitating discussions on its application.









































































