Download to read offline




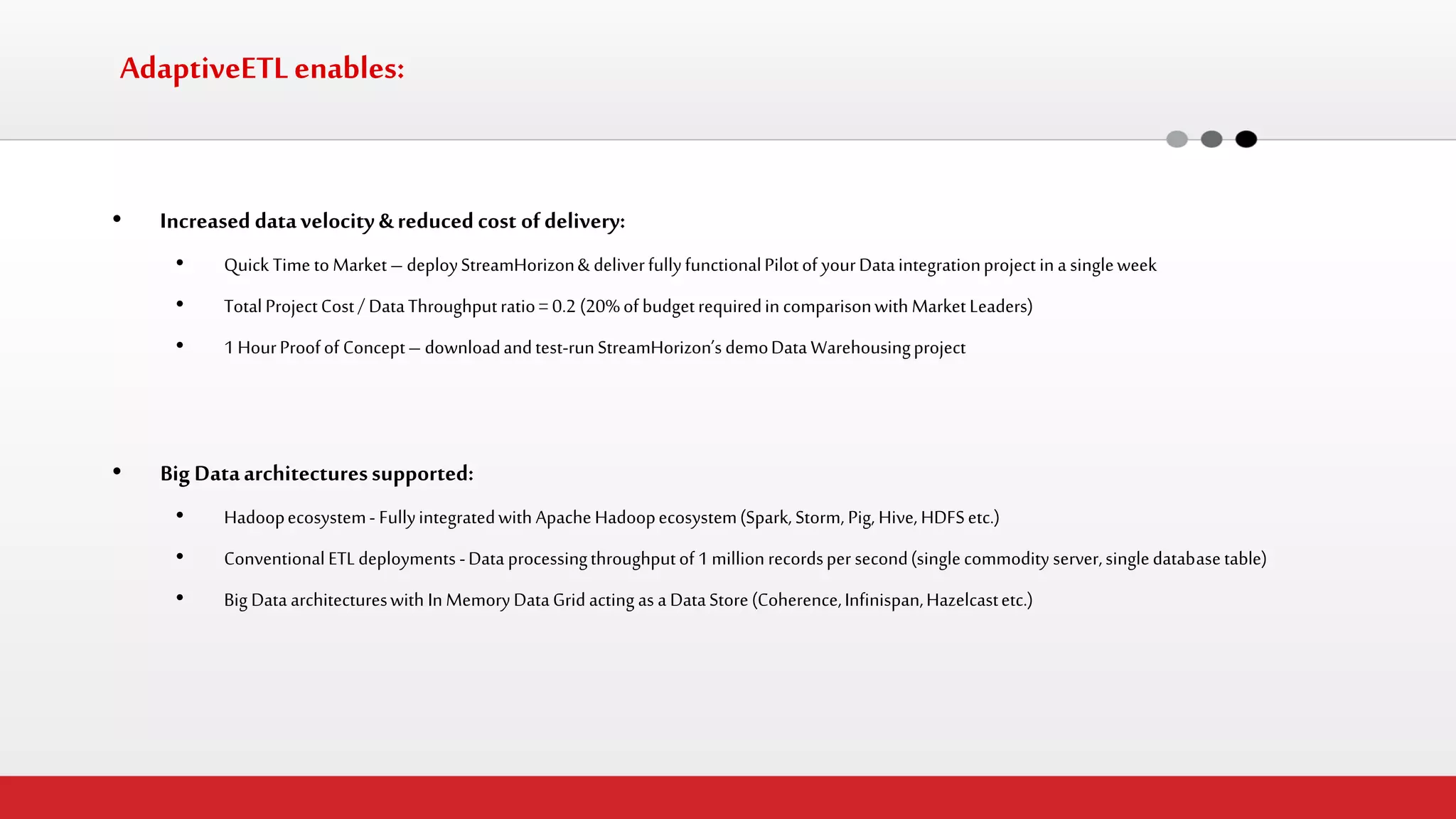



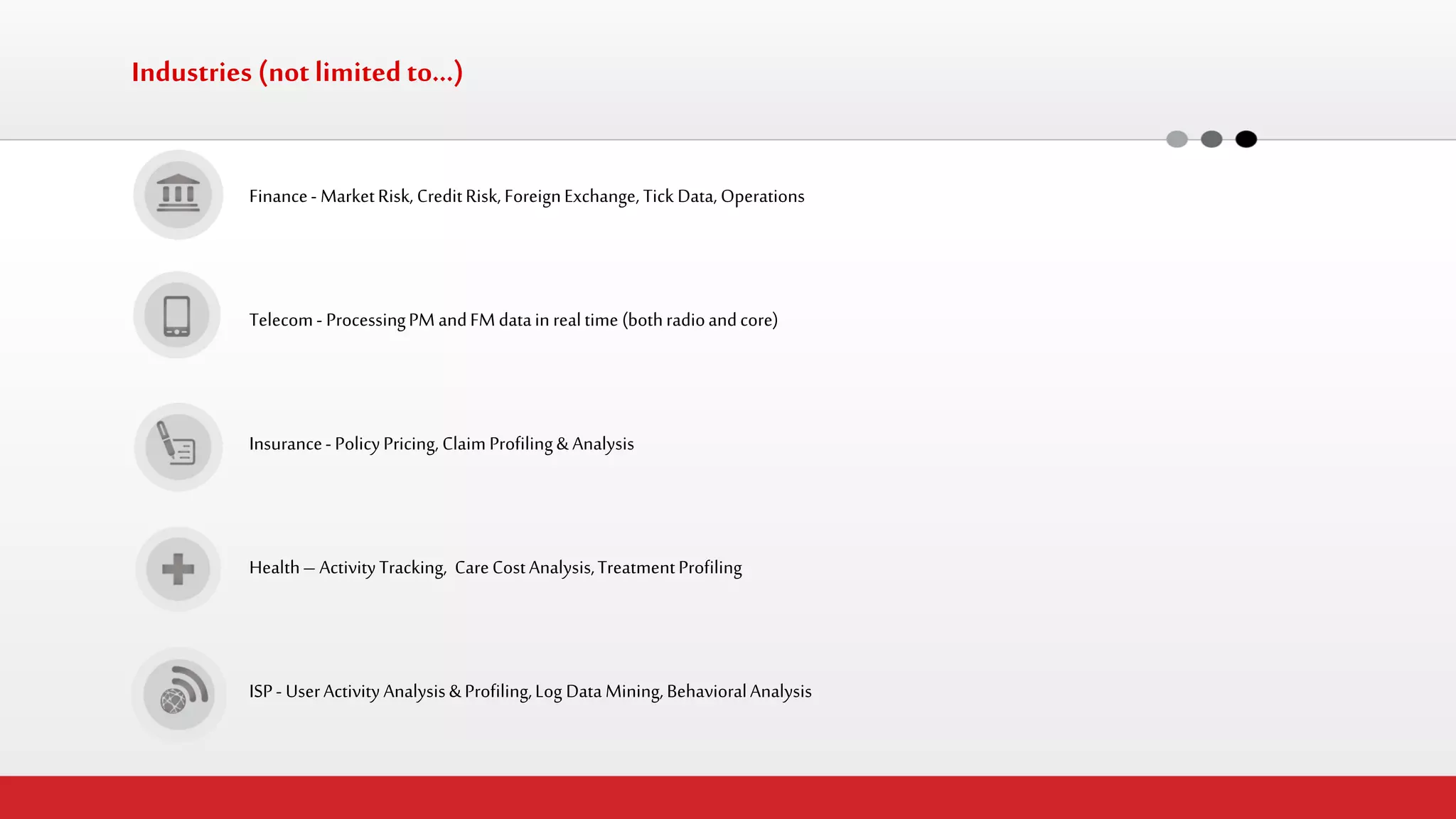
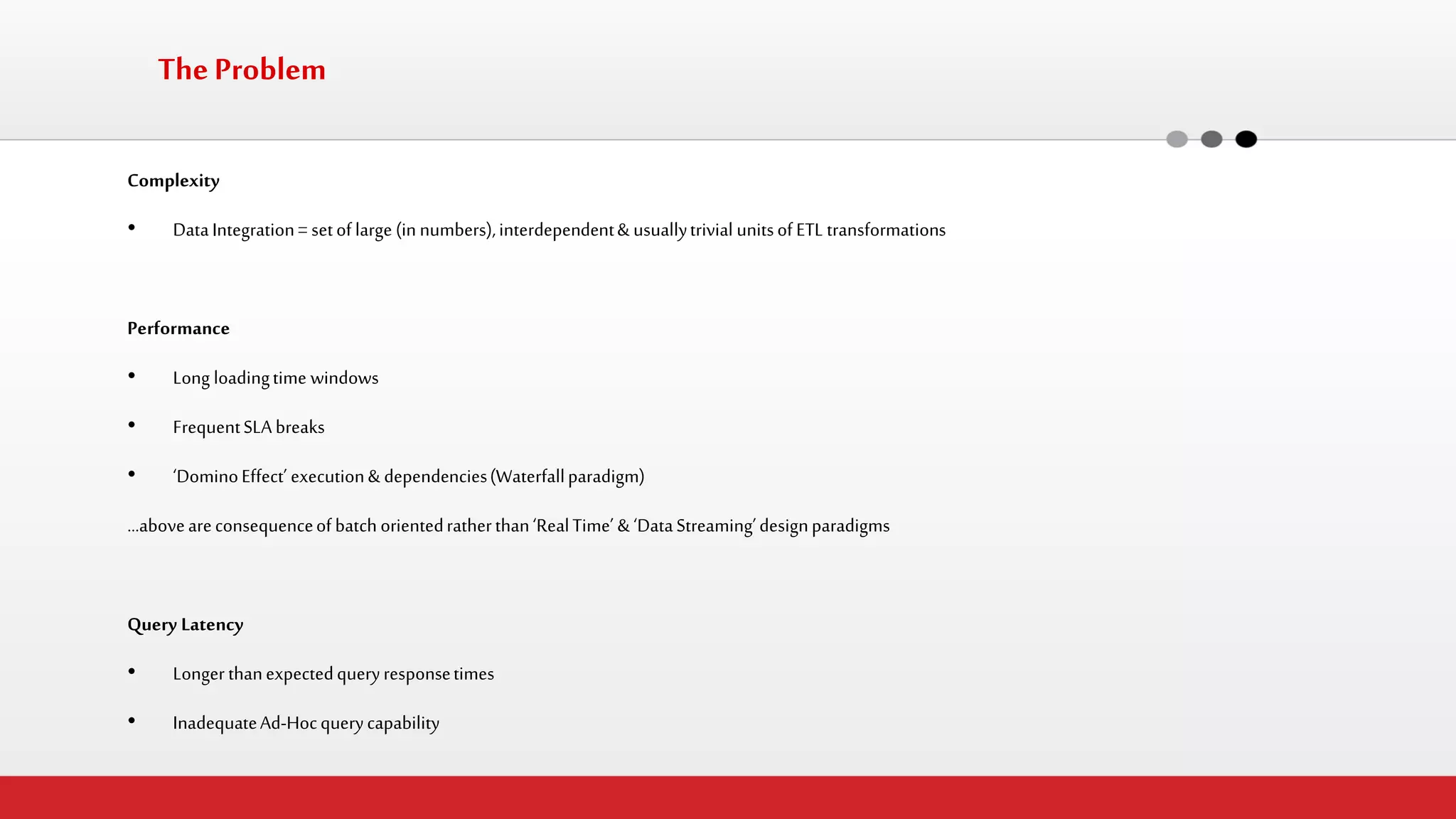



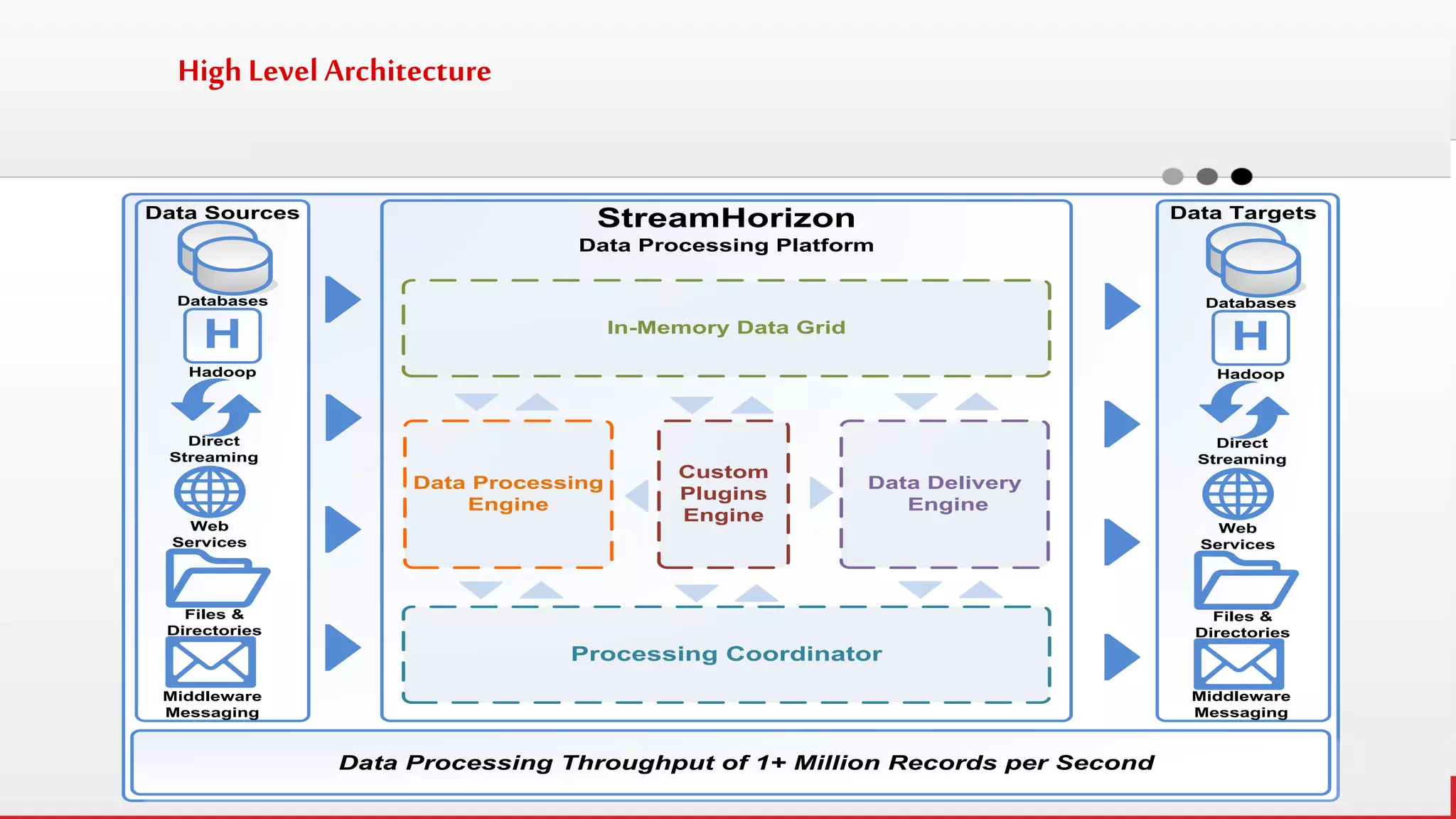
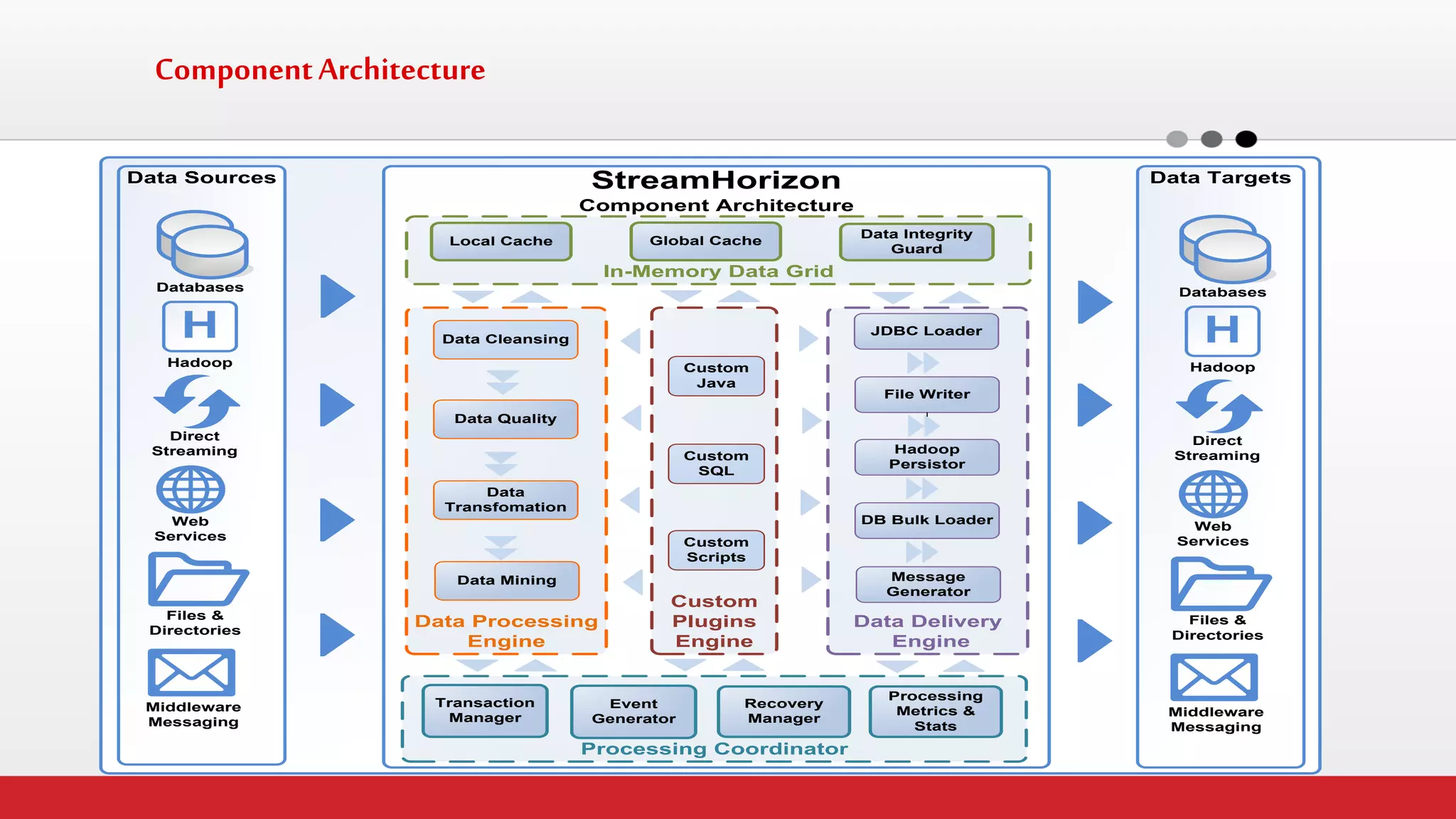
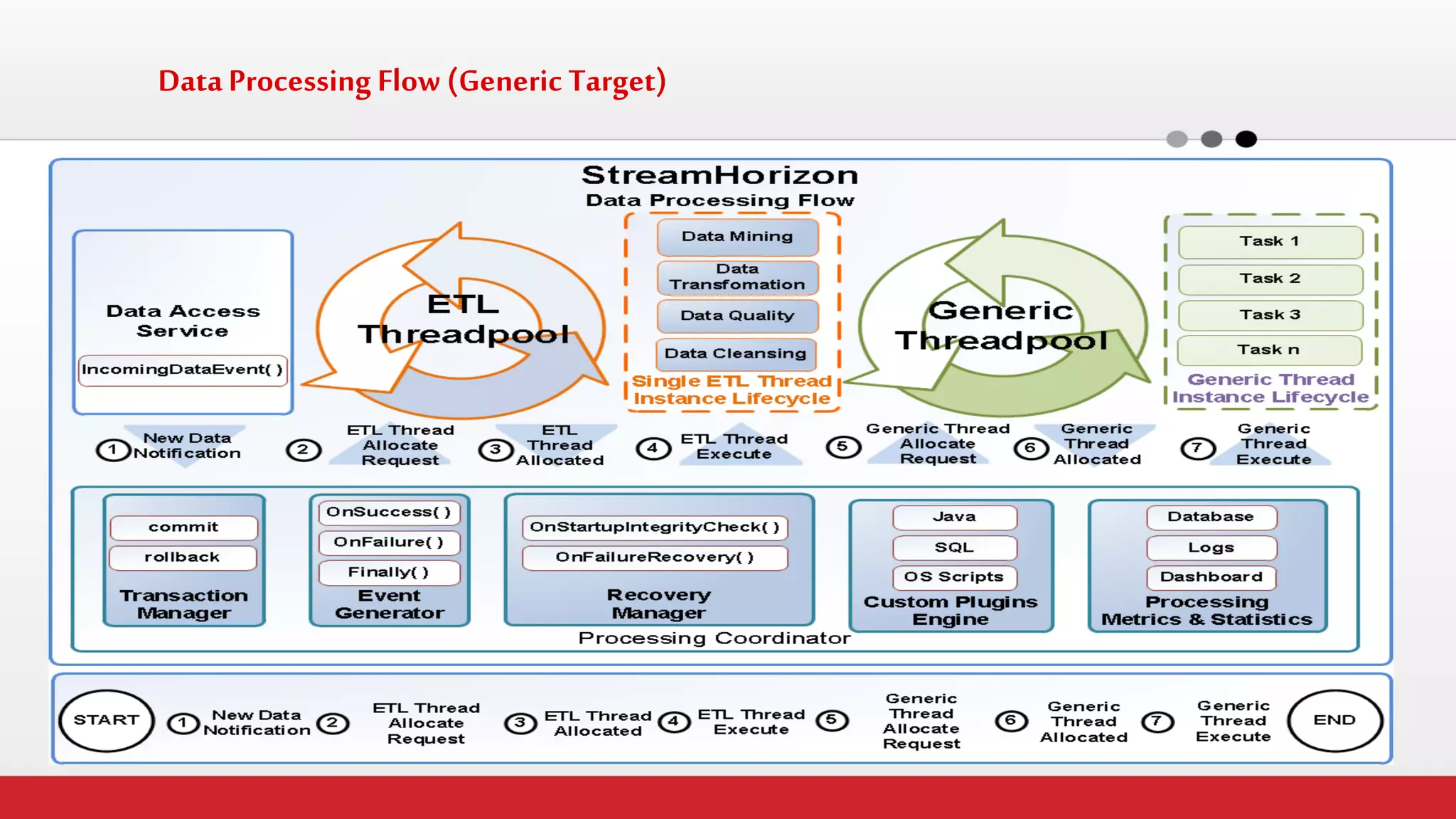
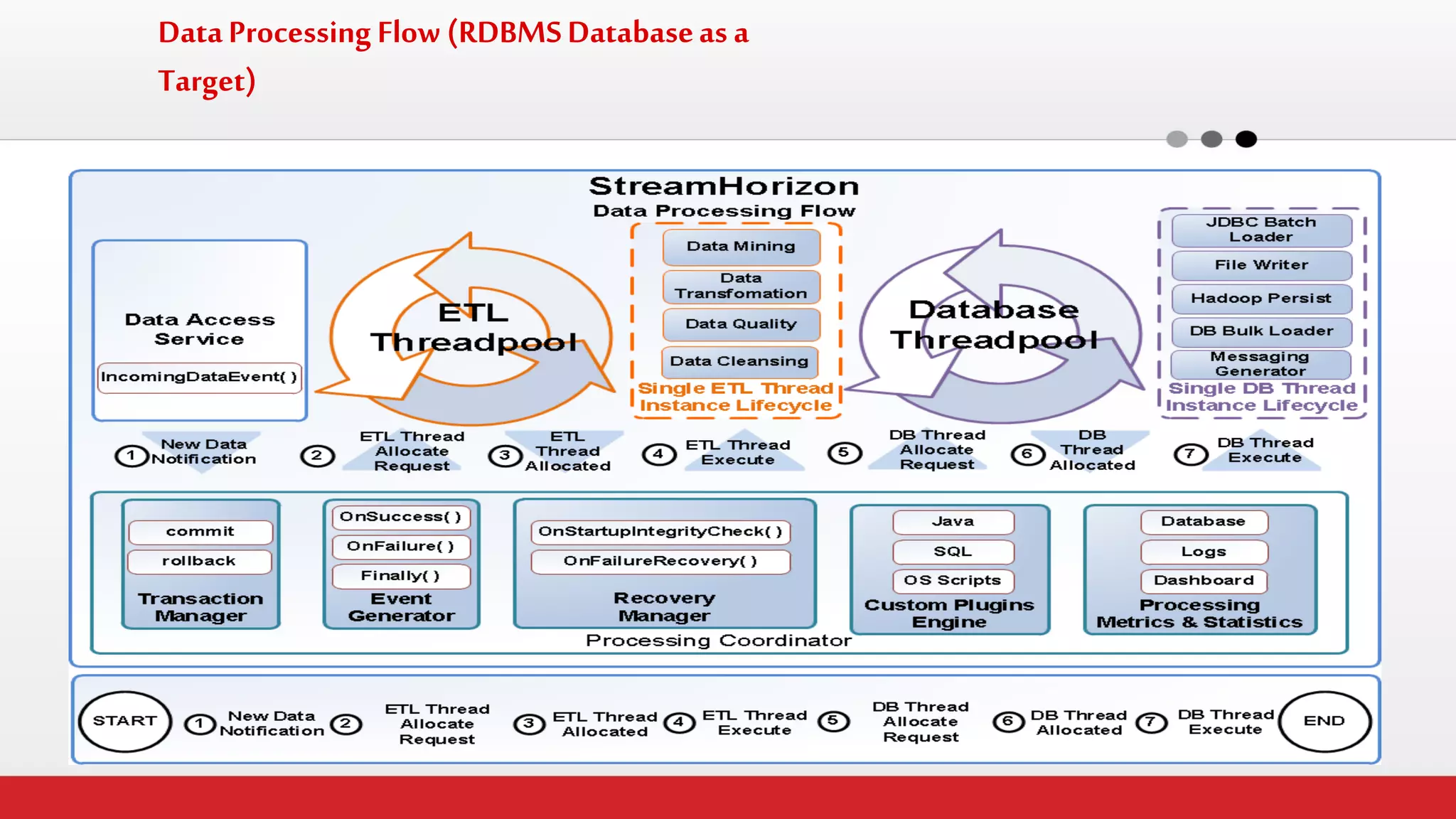

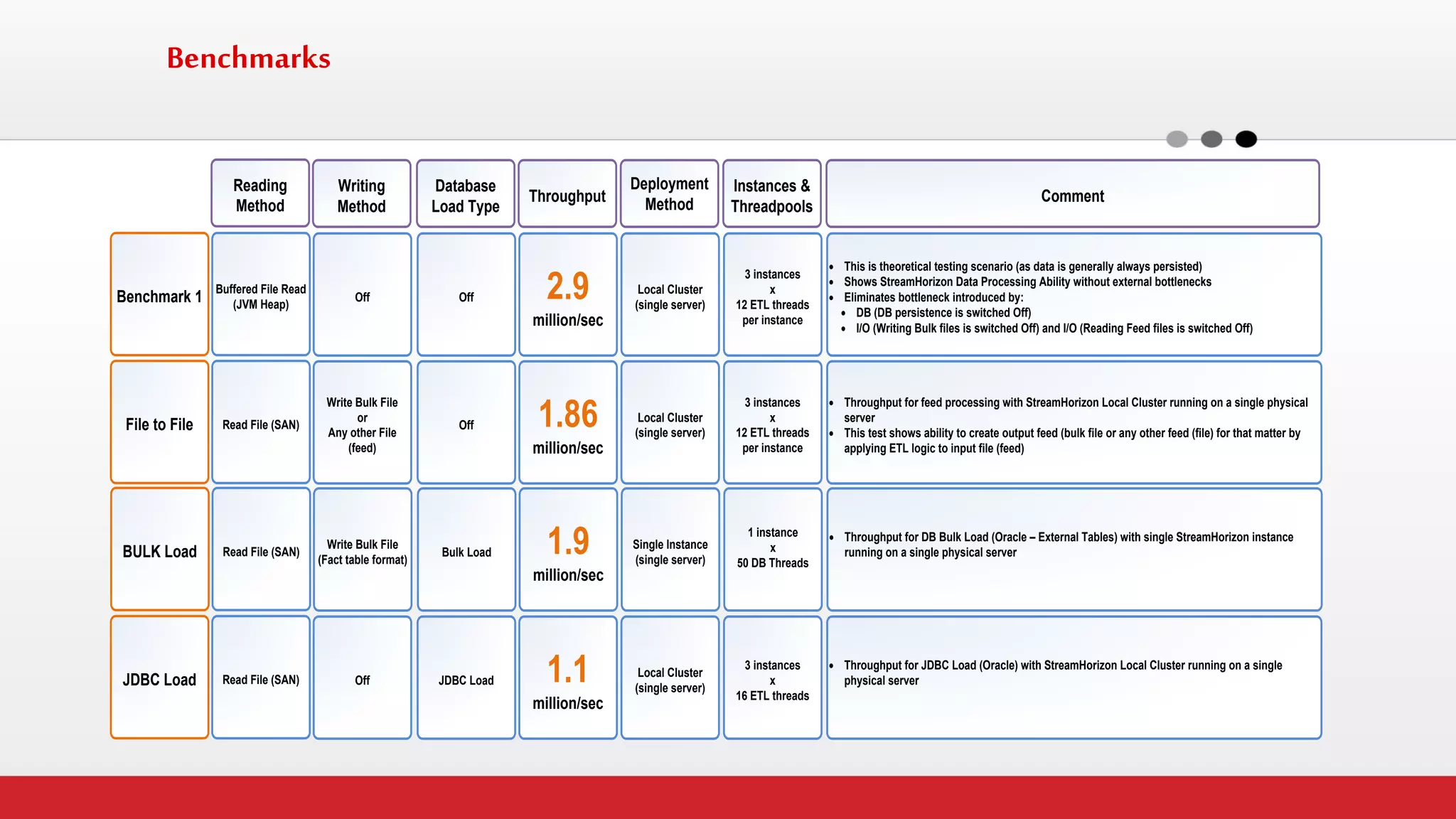


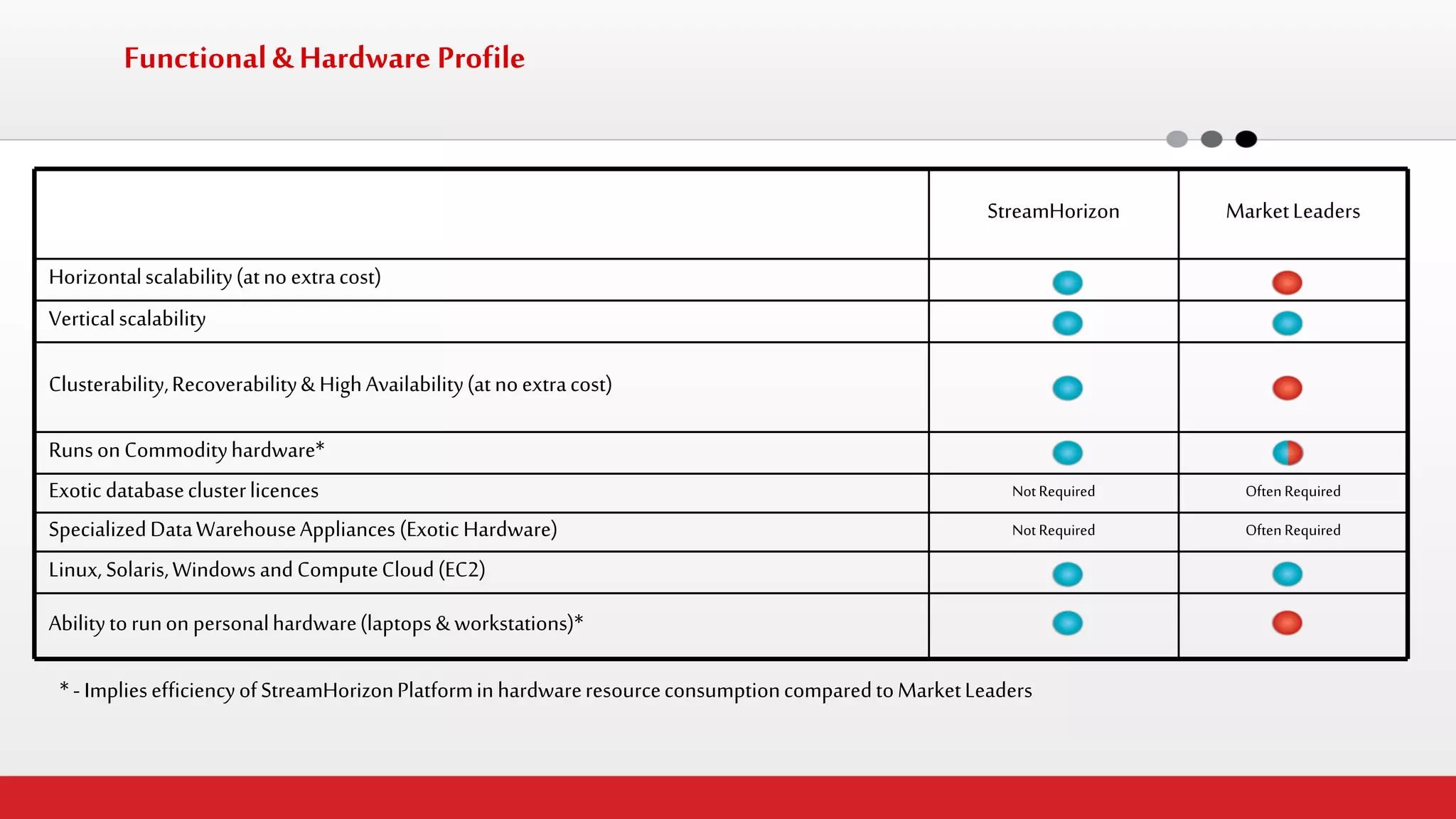
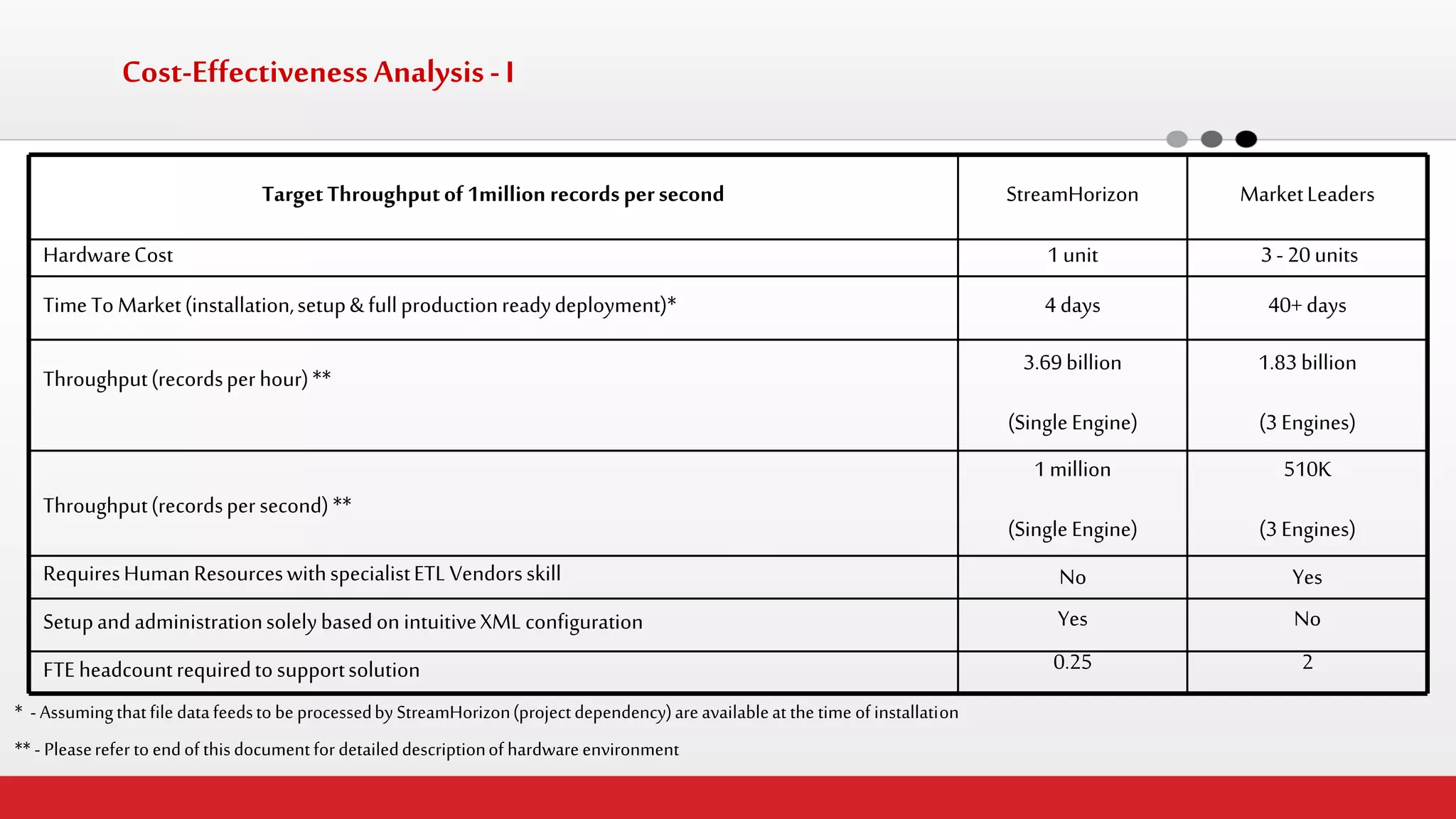
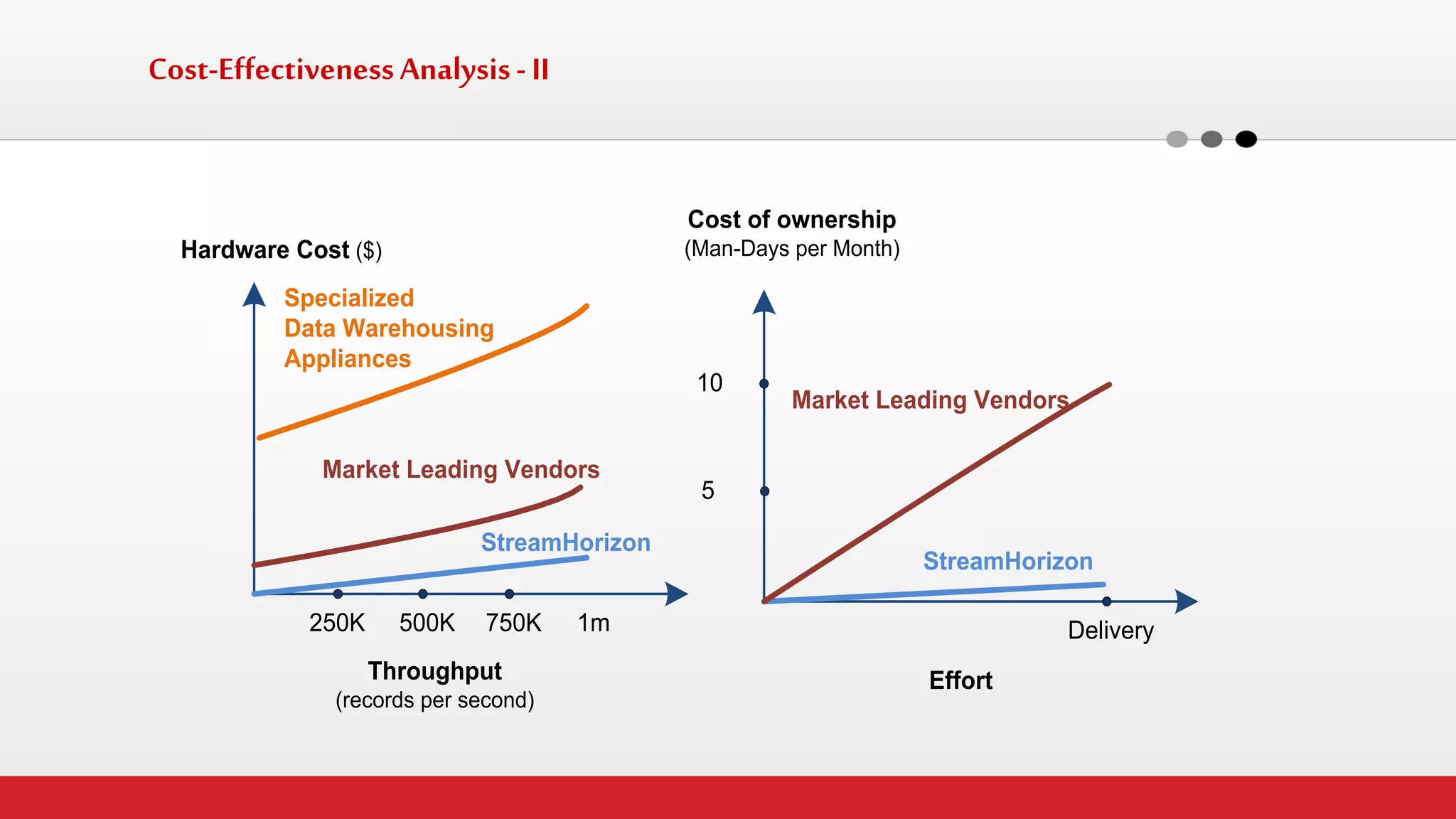
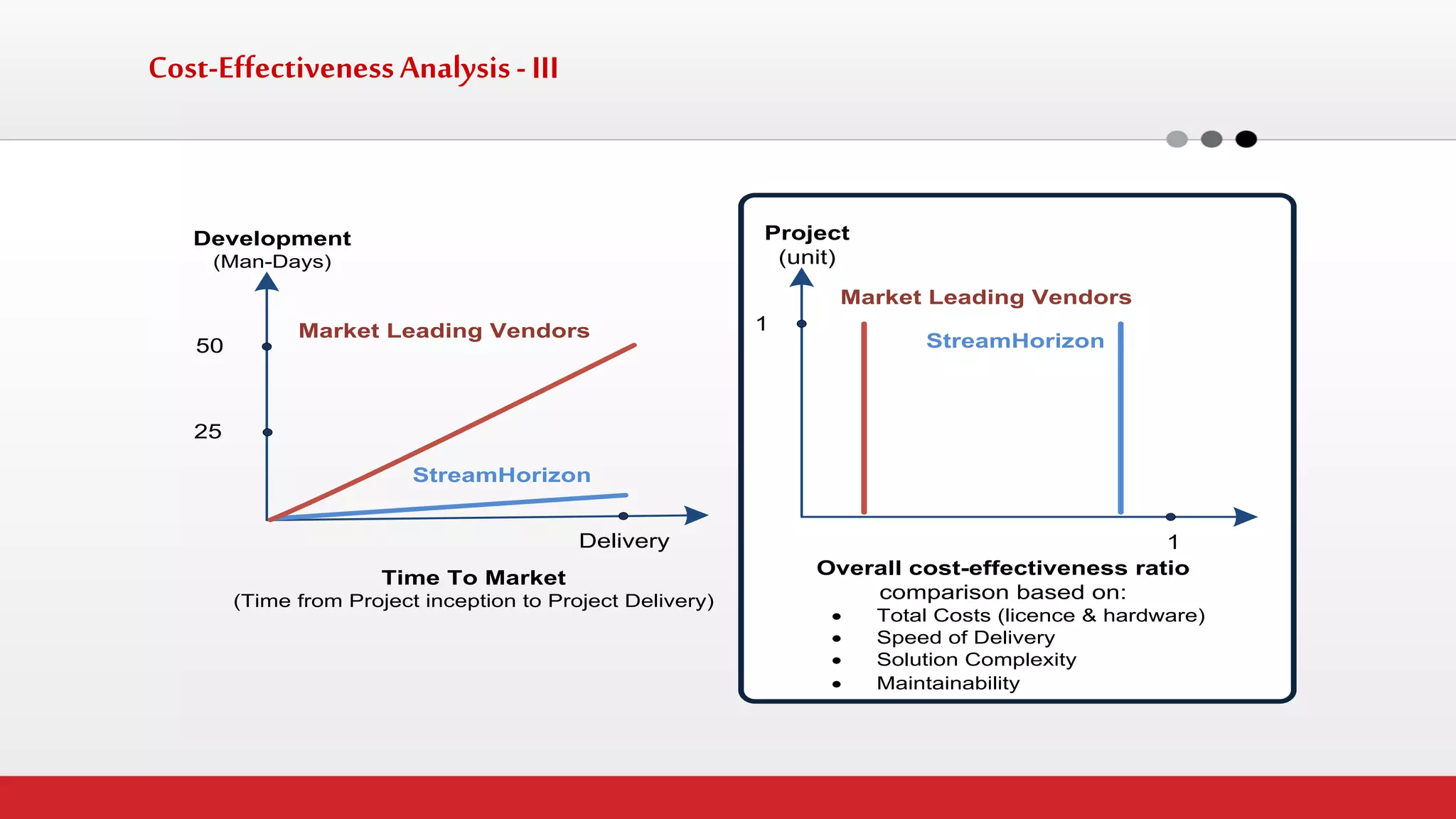







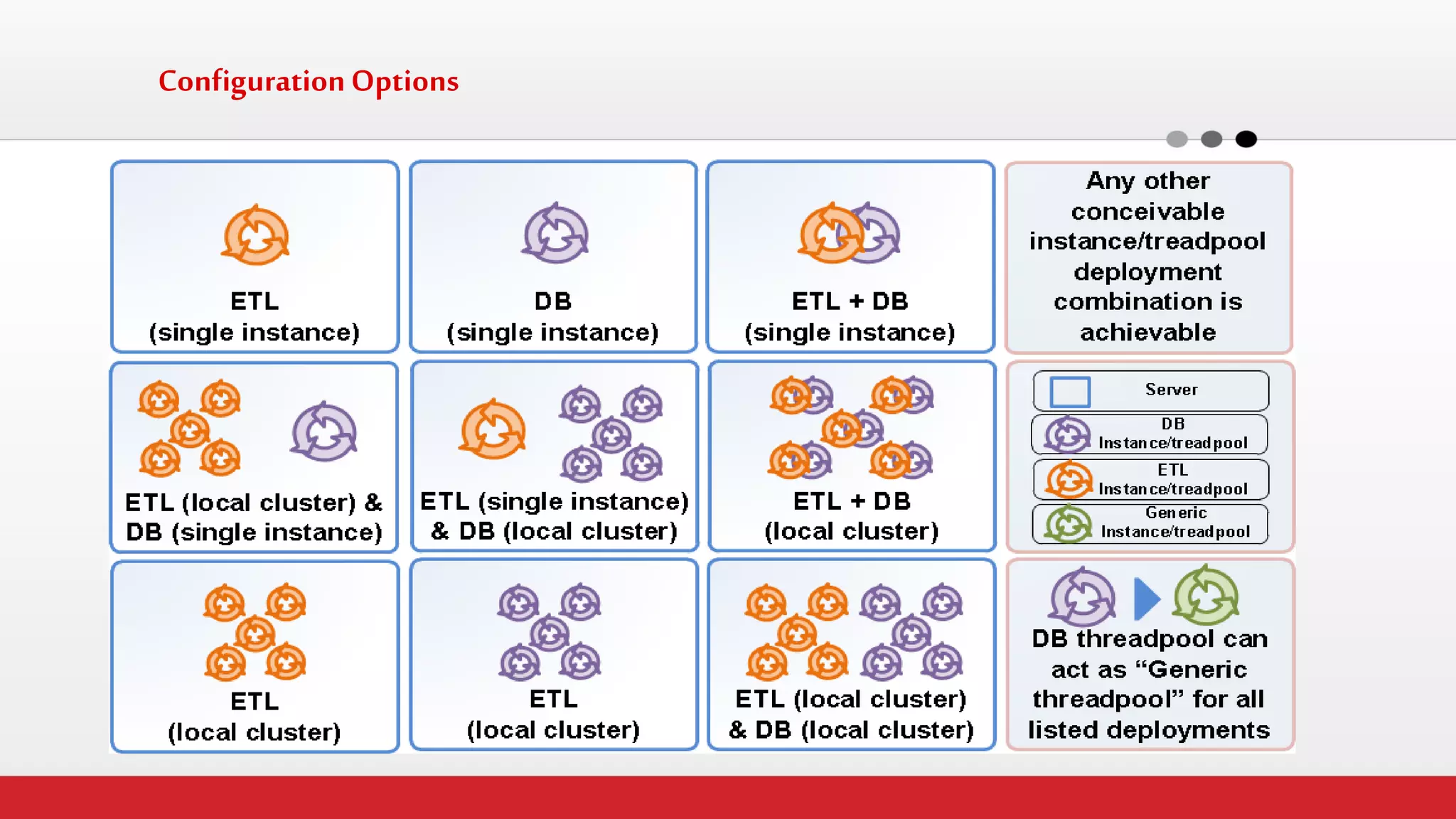
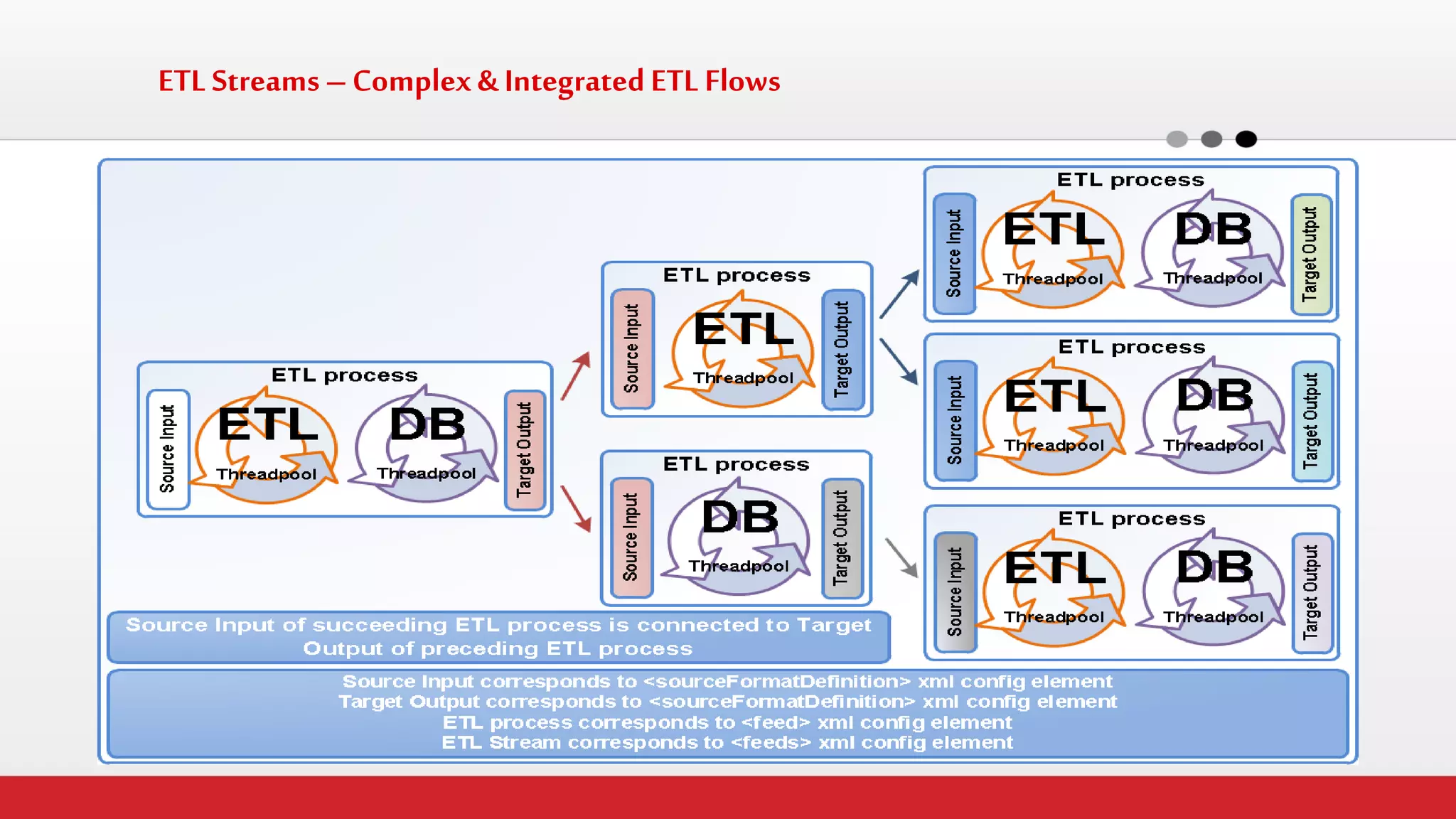
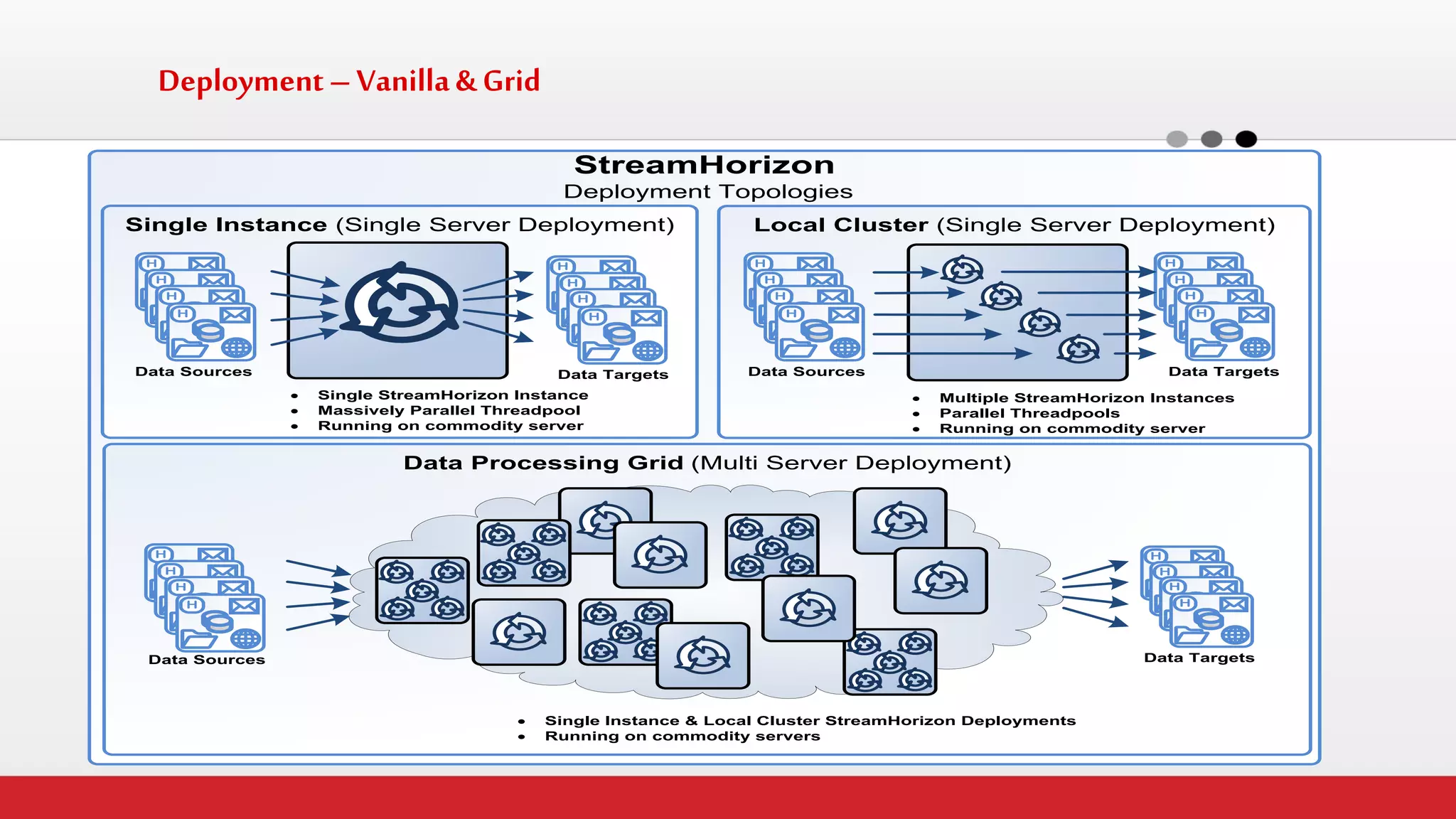


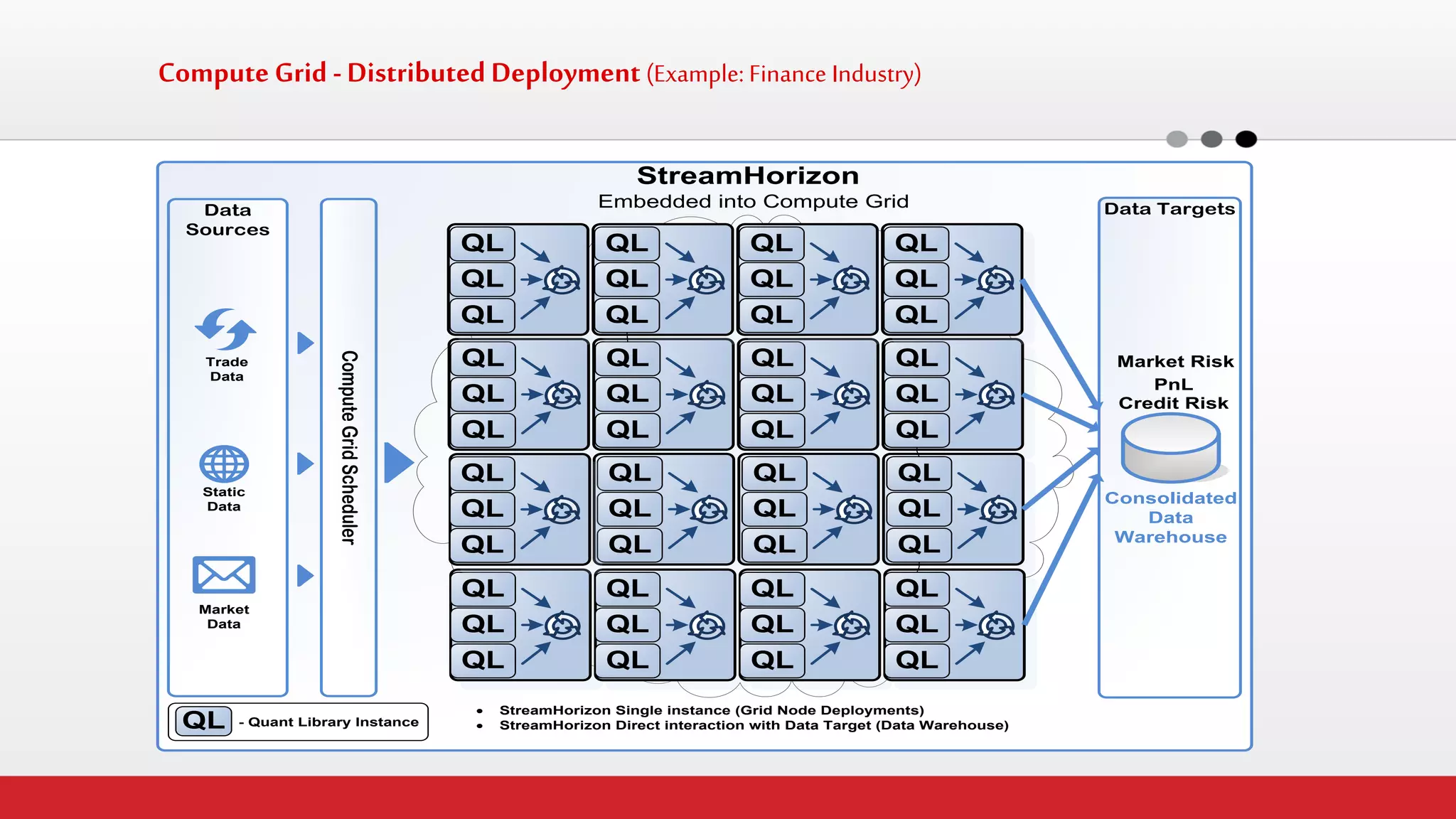
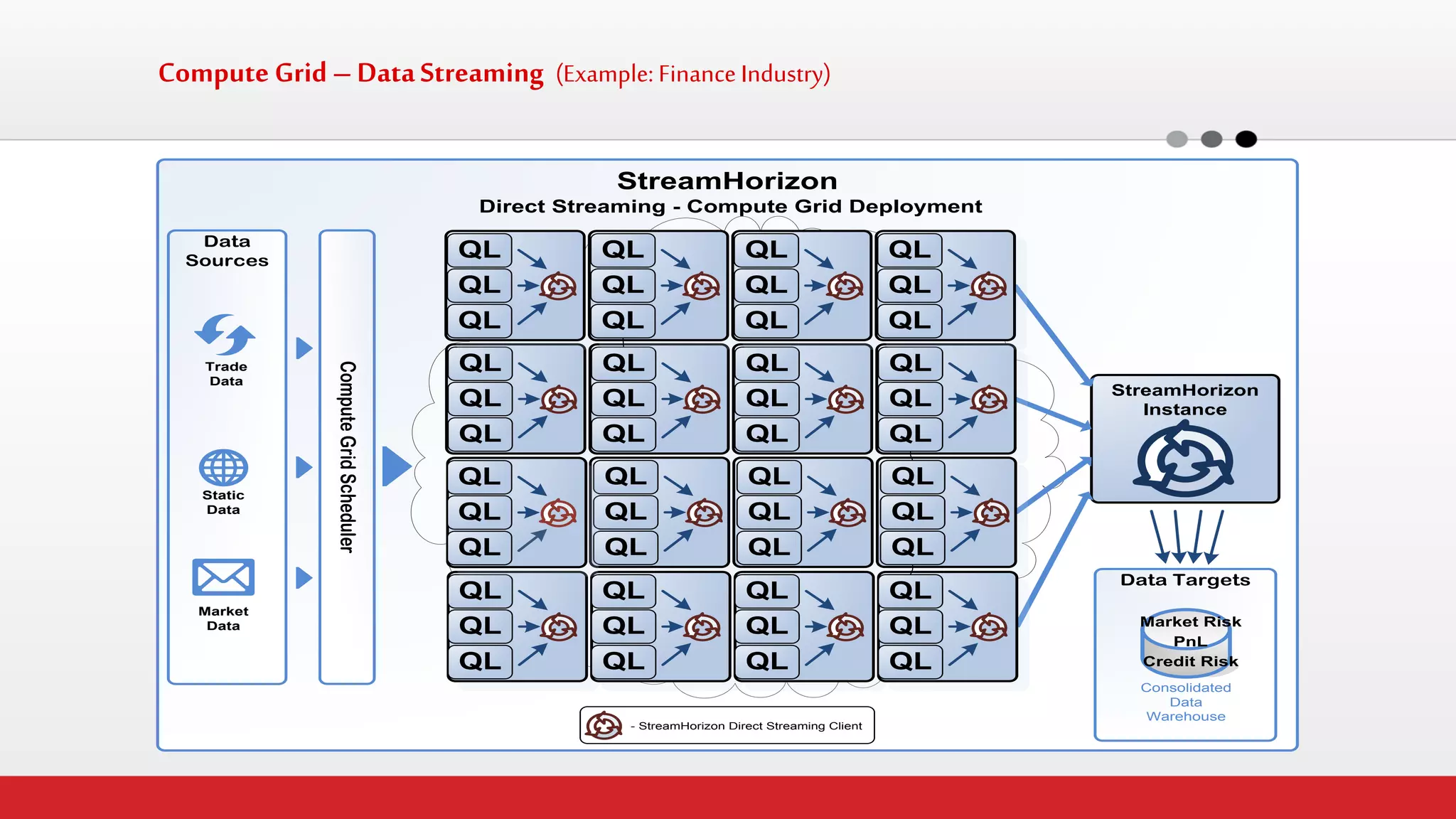

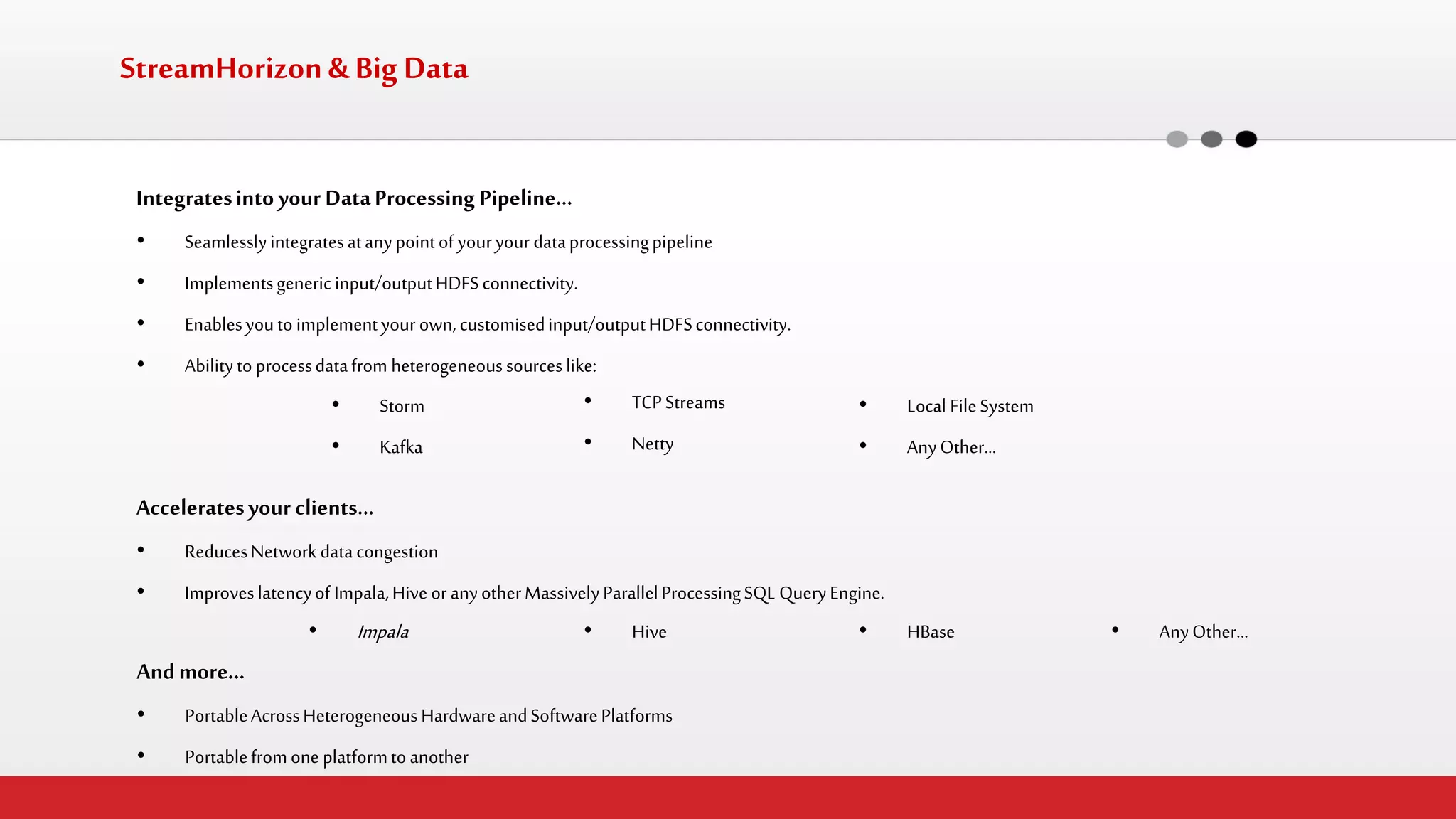

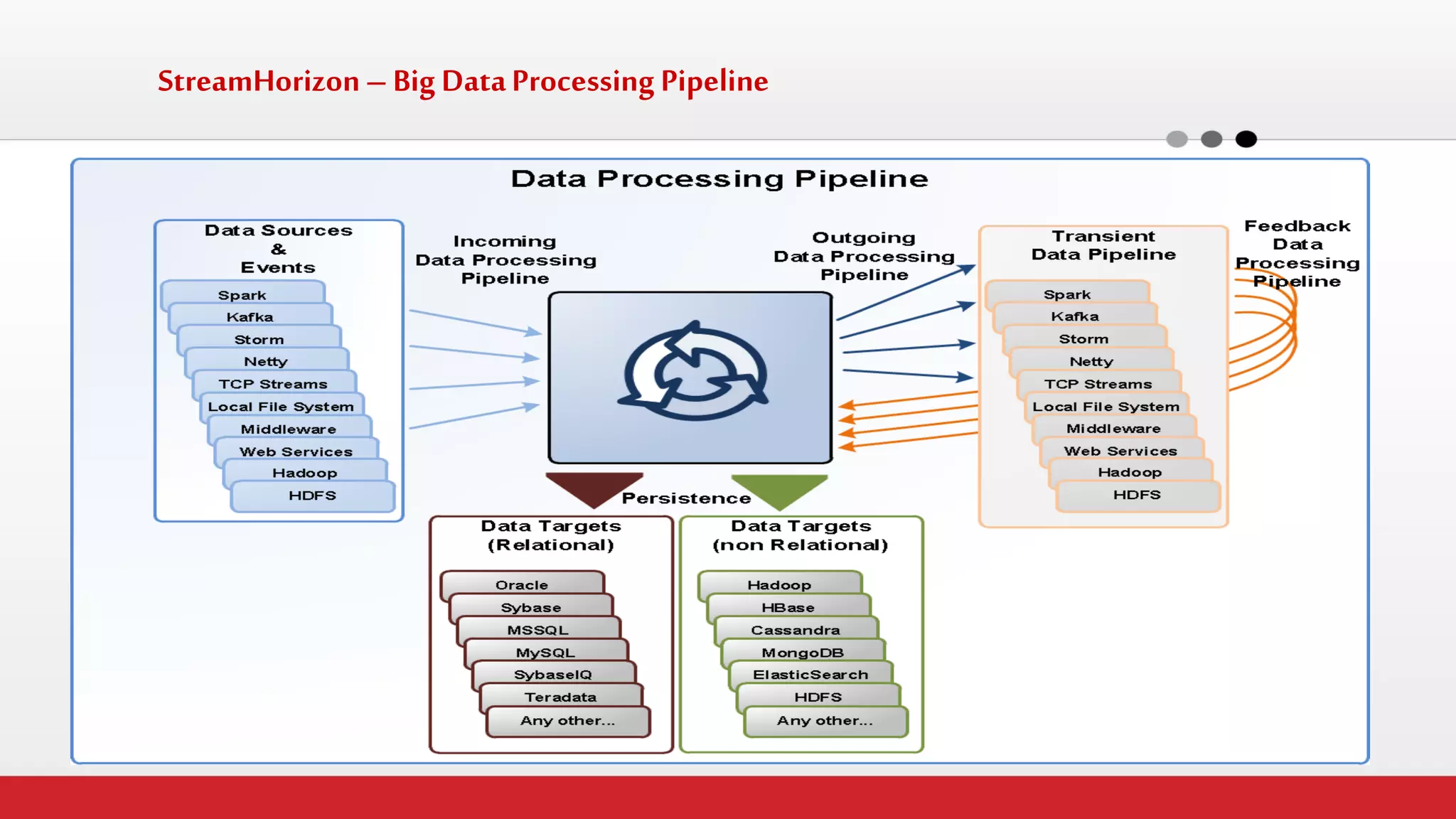
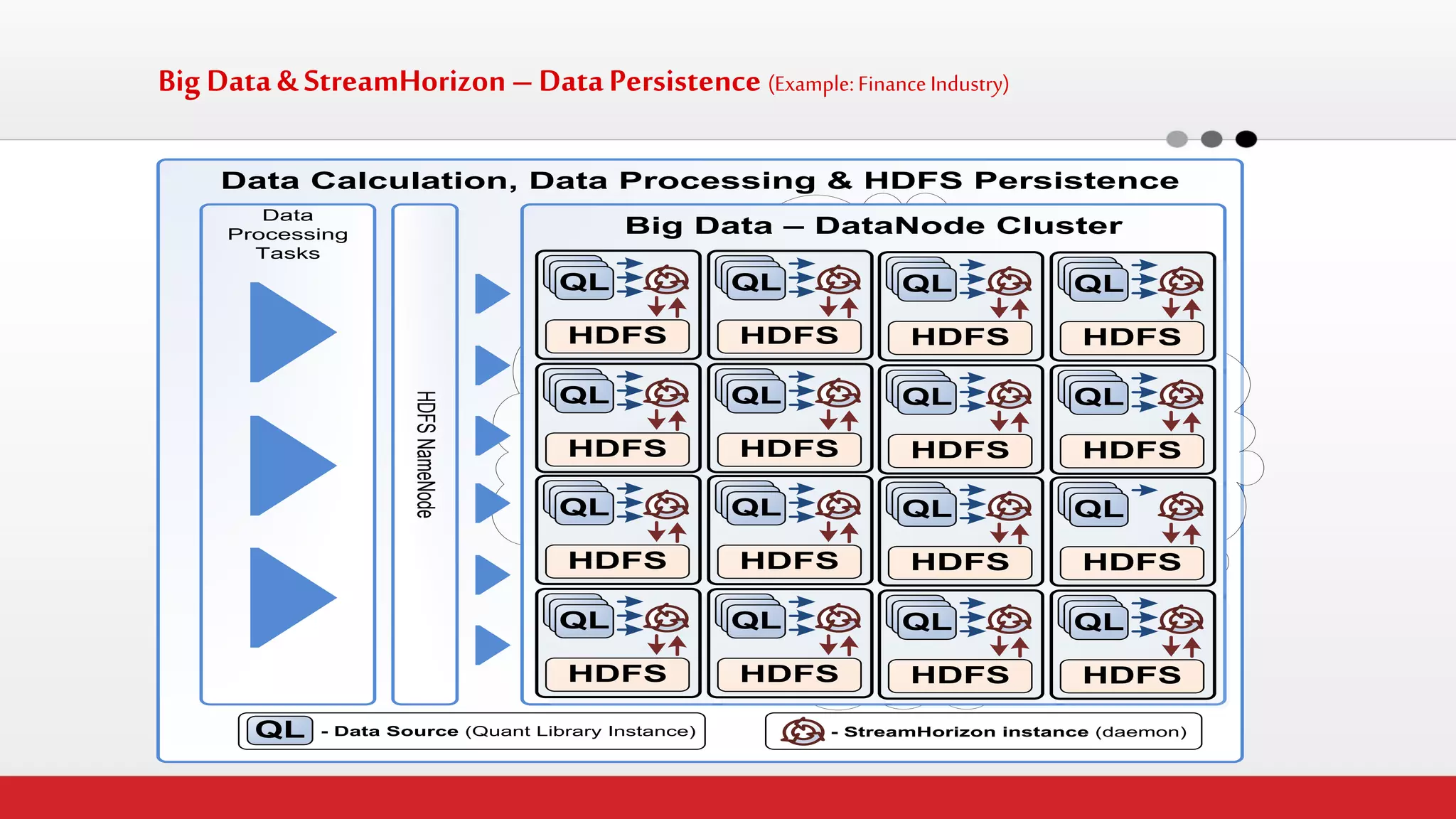
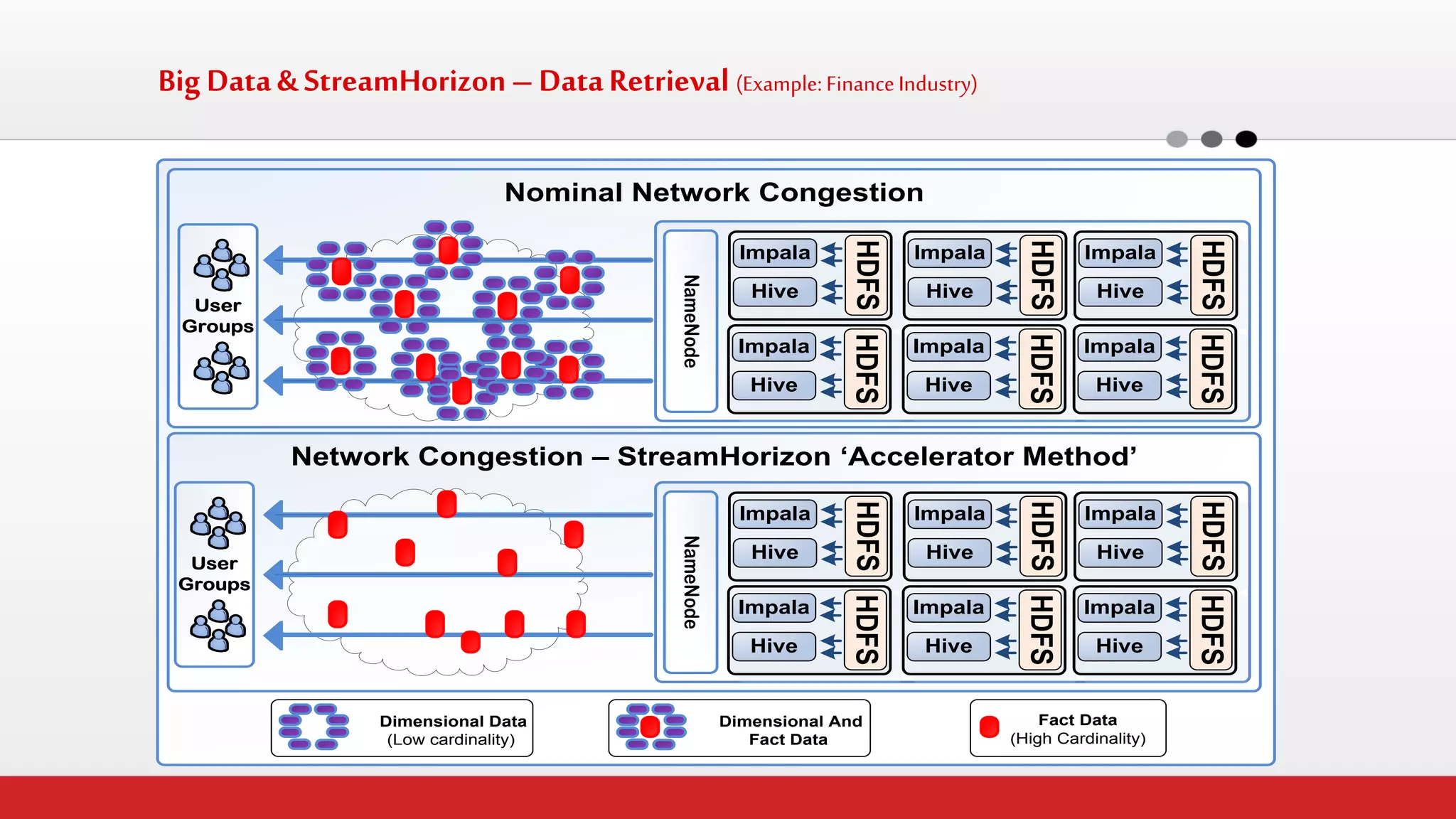
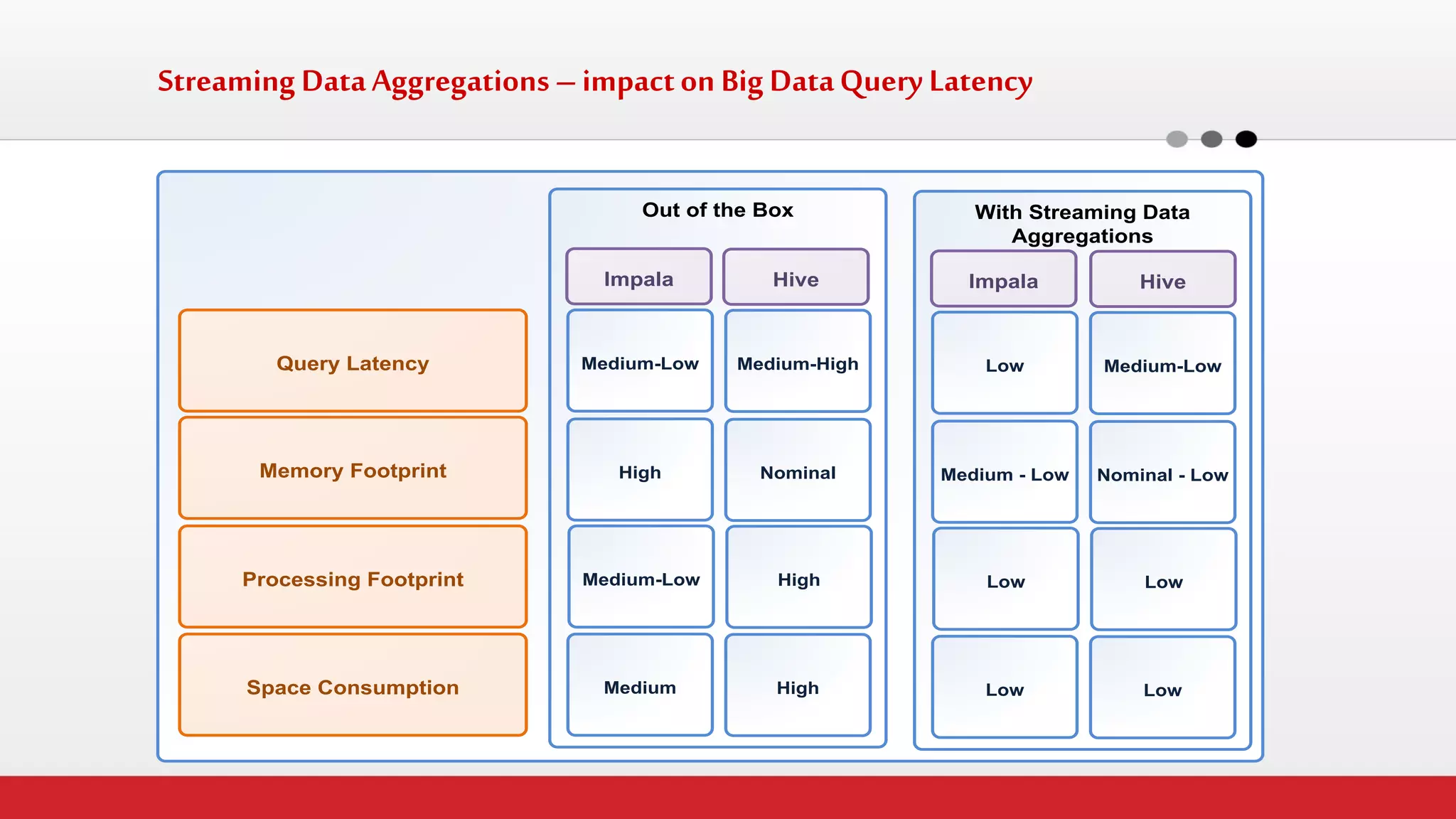





The document discusses StreamHorizon's "adaptiveETL" platform for big data analytics. It highlights limitations of legacy ETL platforms and StreamHorizon's advantages, including massively parallel processing, in-memory processing, quick time to market, low total cost of ownership, and support for big data architectures like Hadoop. StreamHorizon is presented as an effective and cost-efficient solution for data integration and processing projects.








































































