Download to read offline



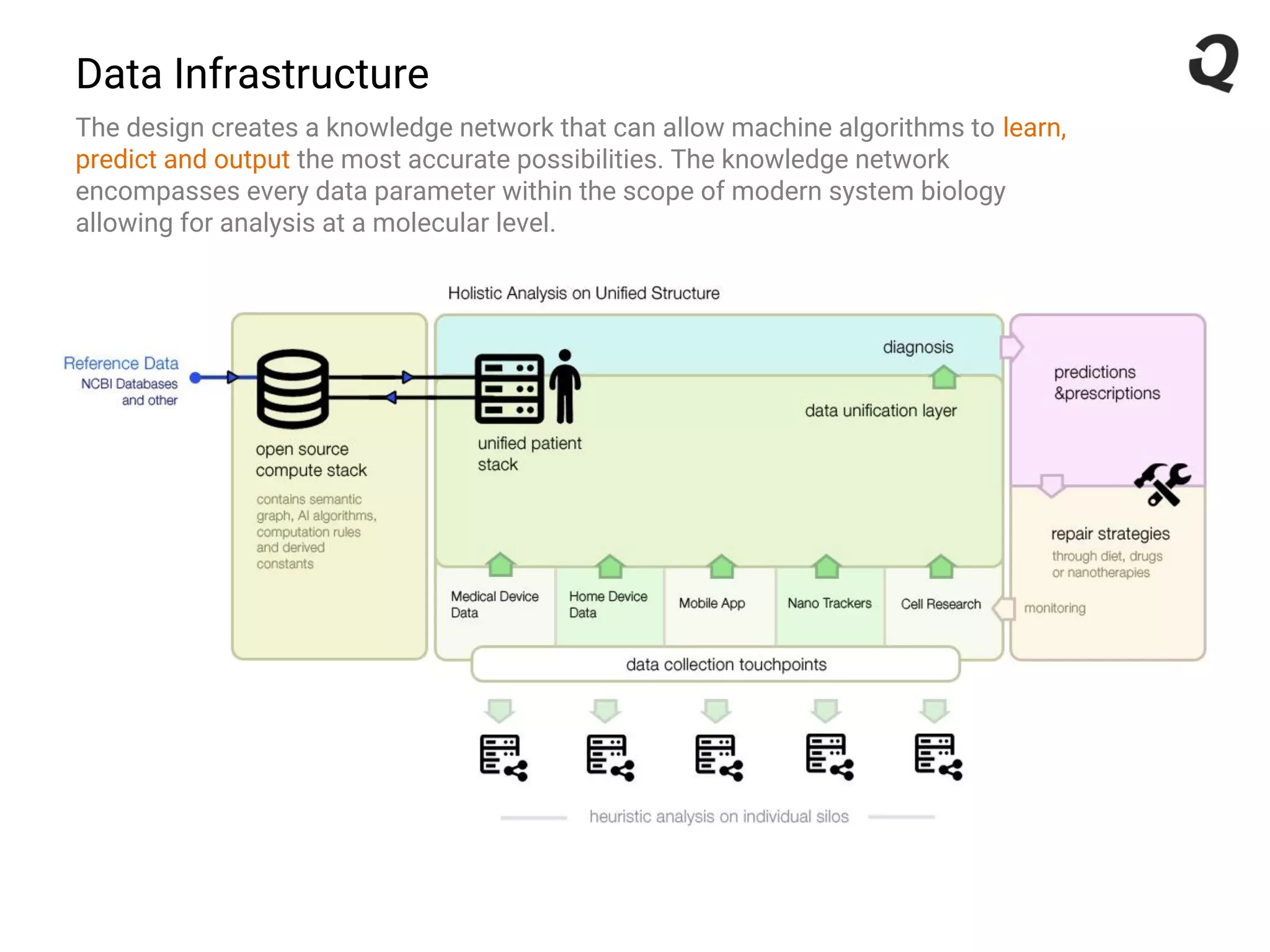
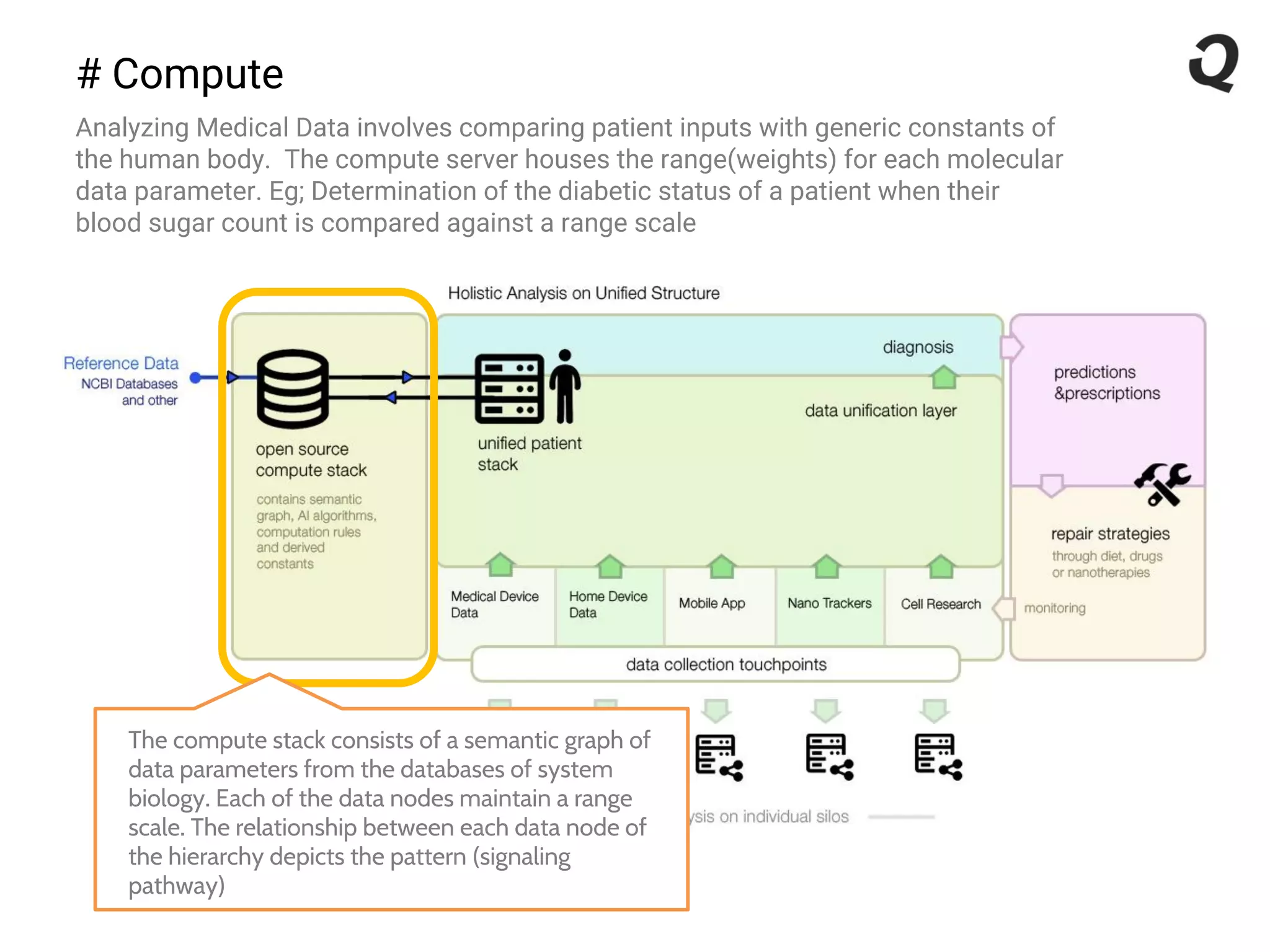
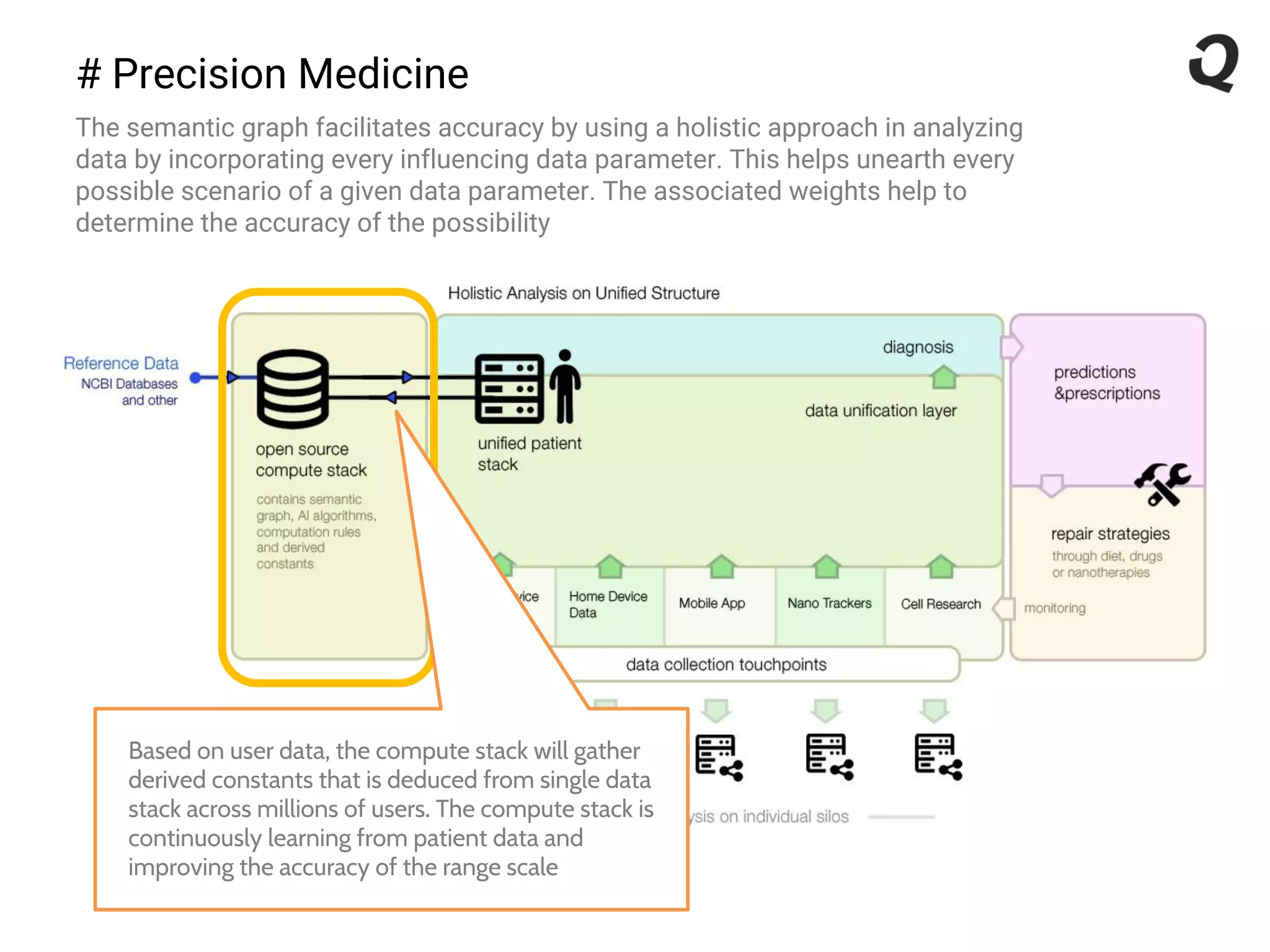
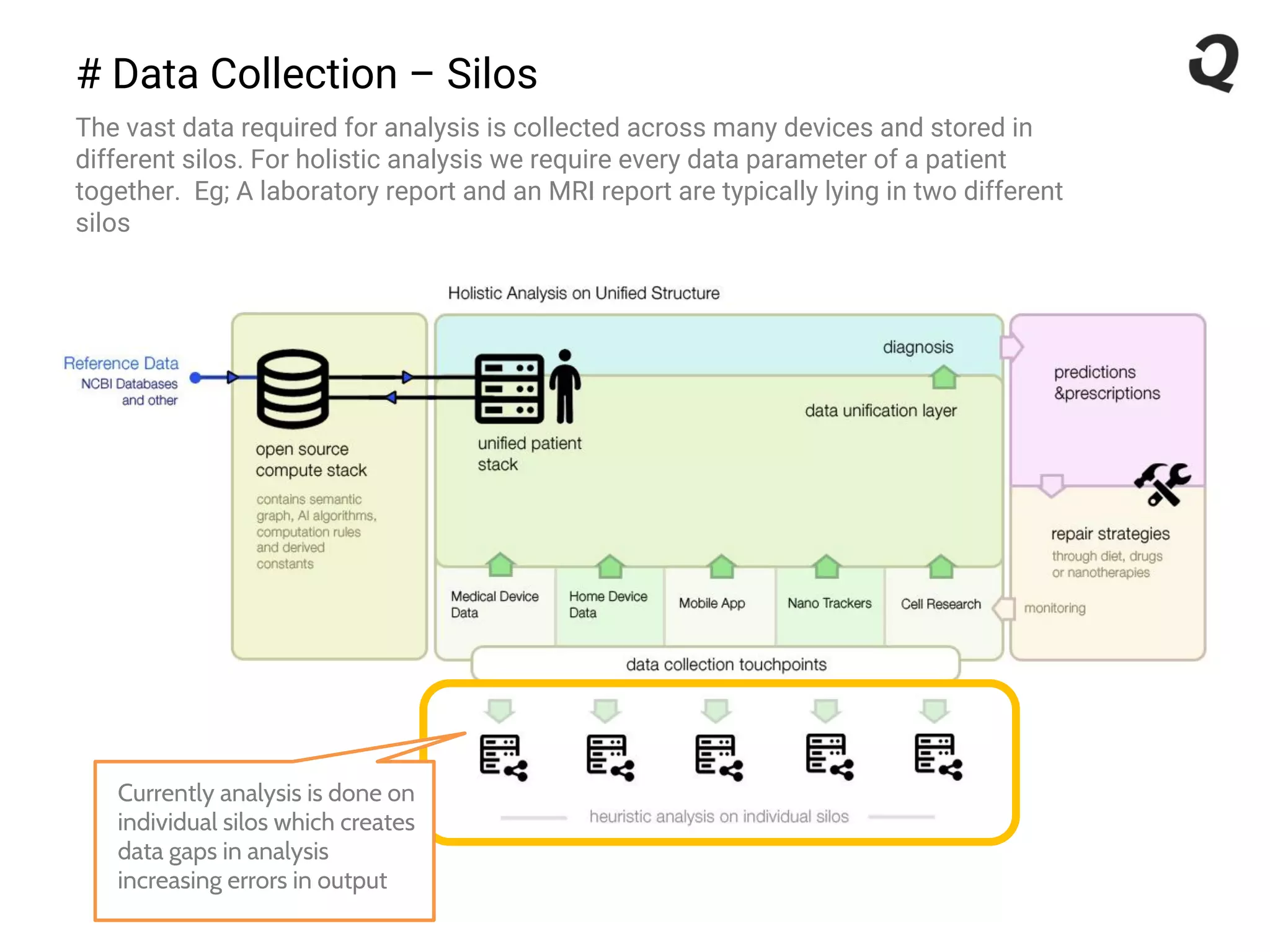
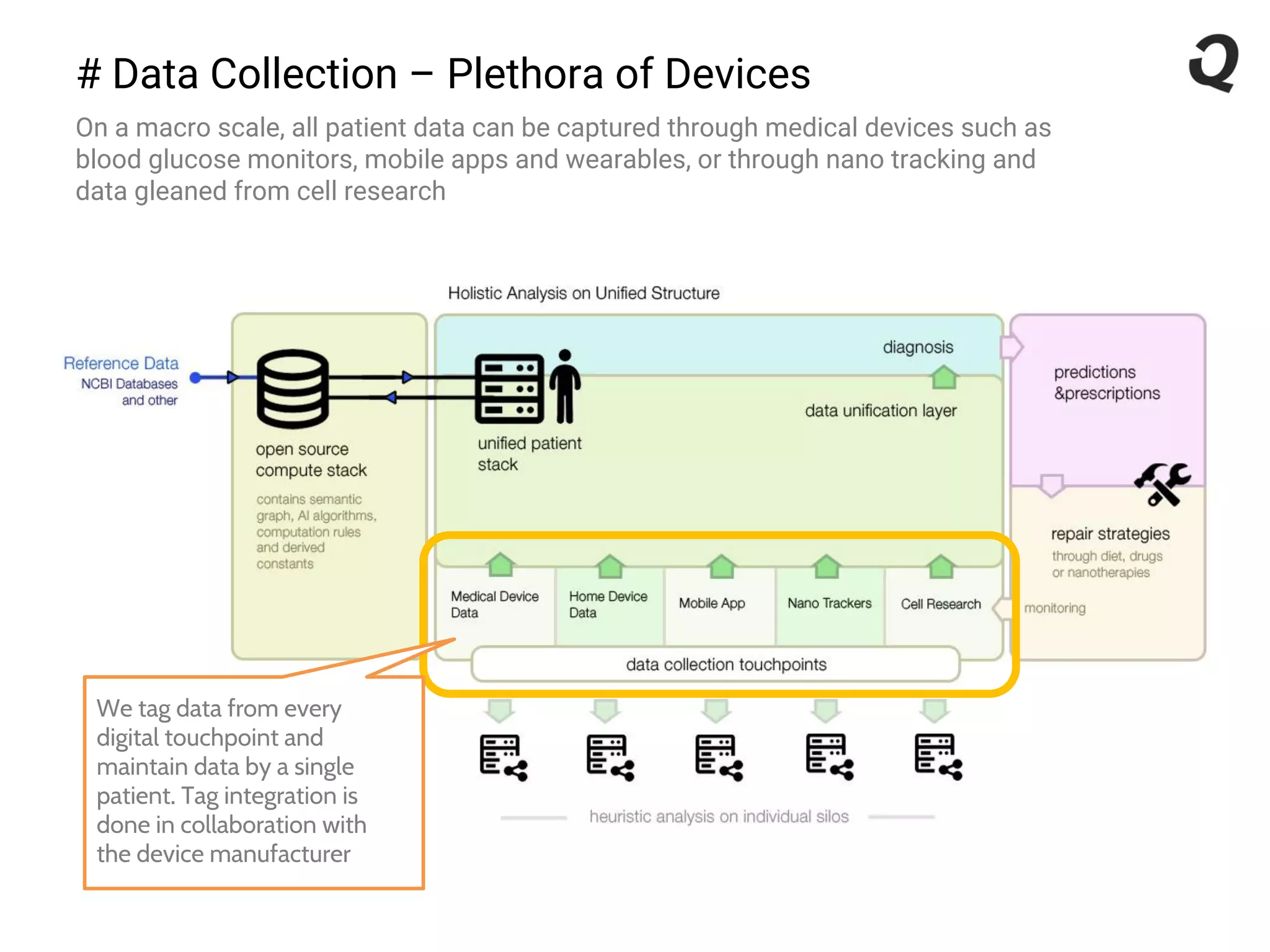
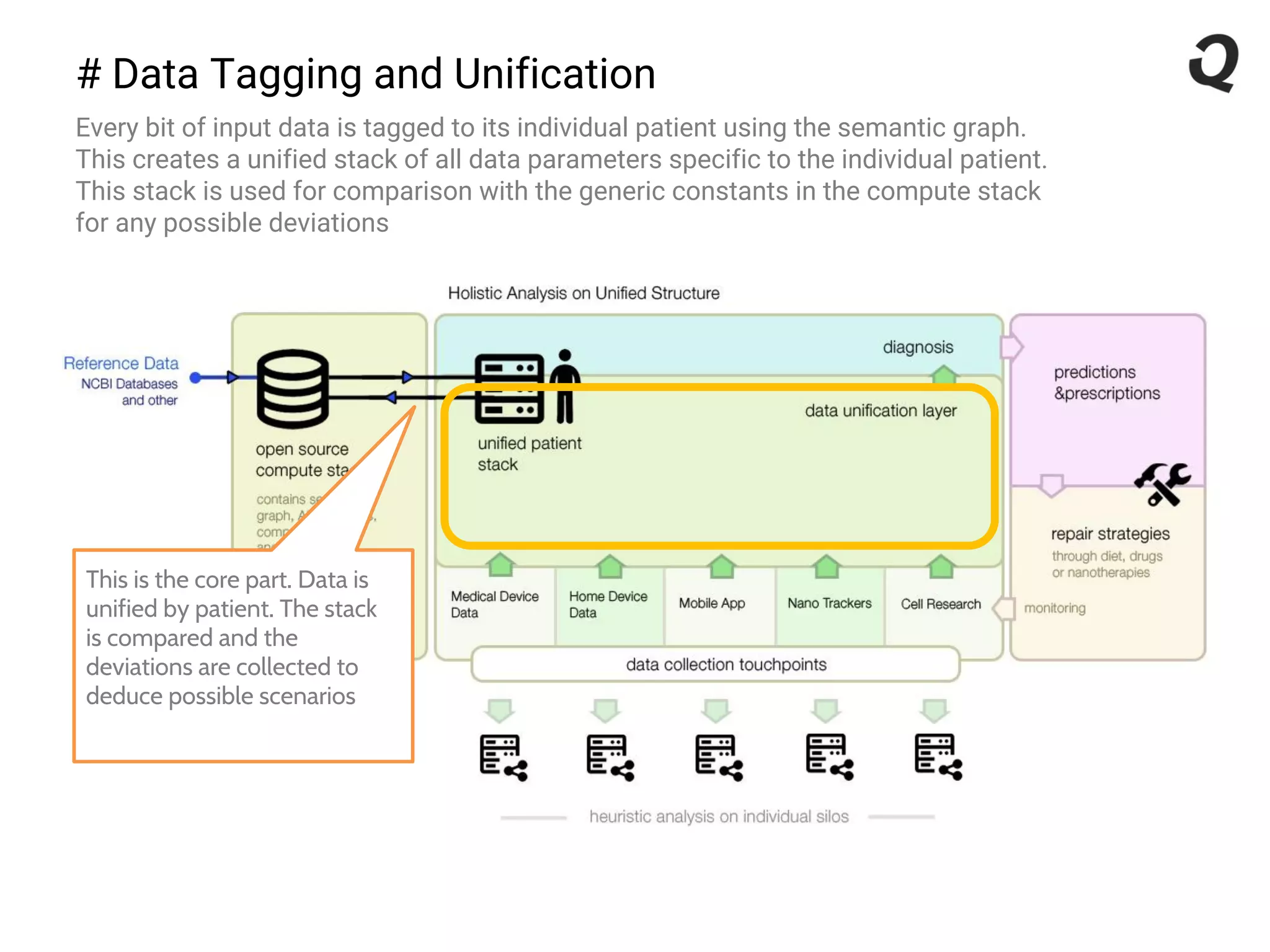
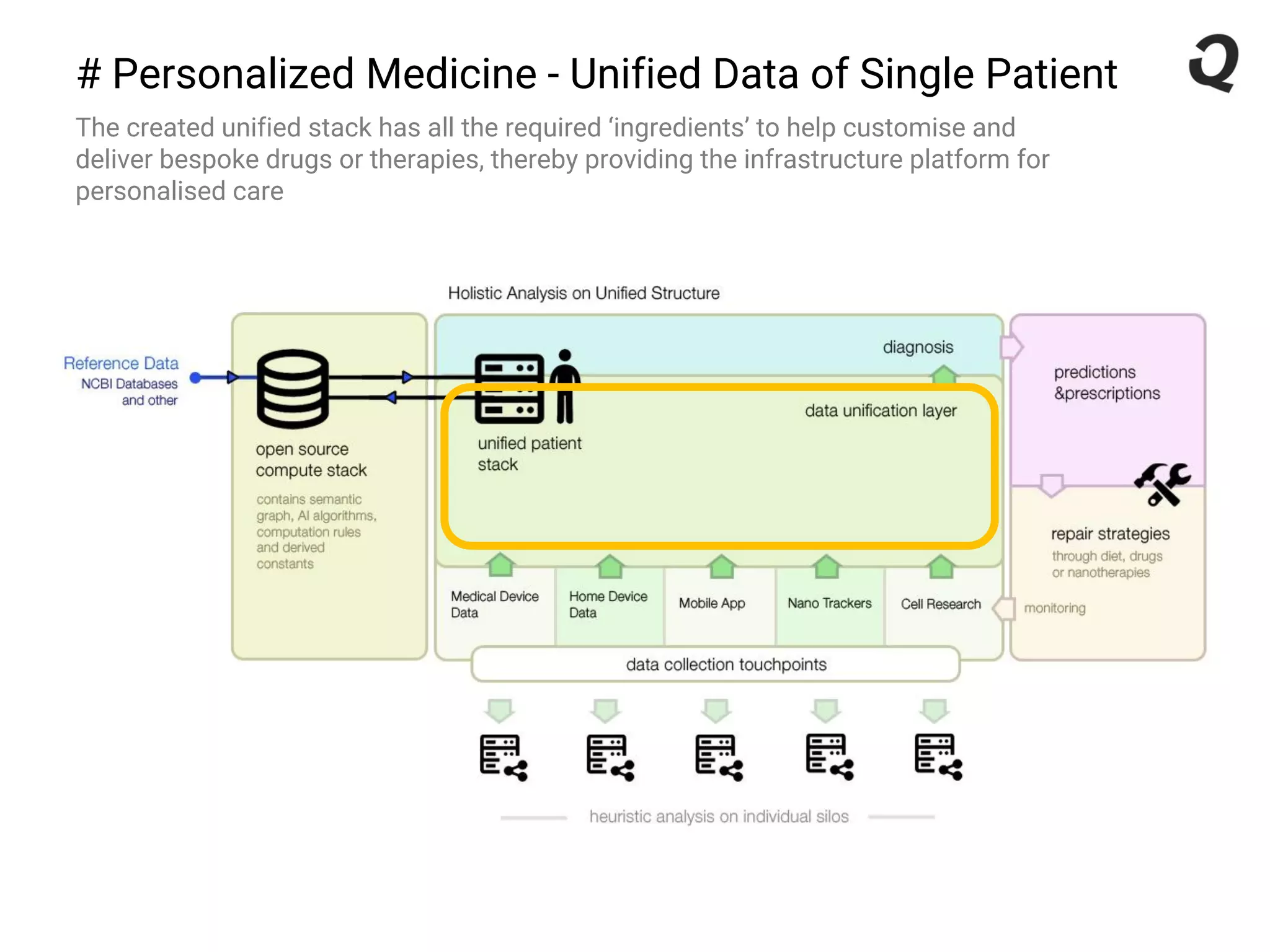
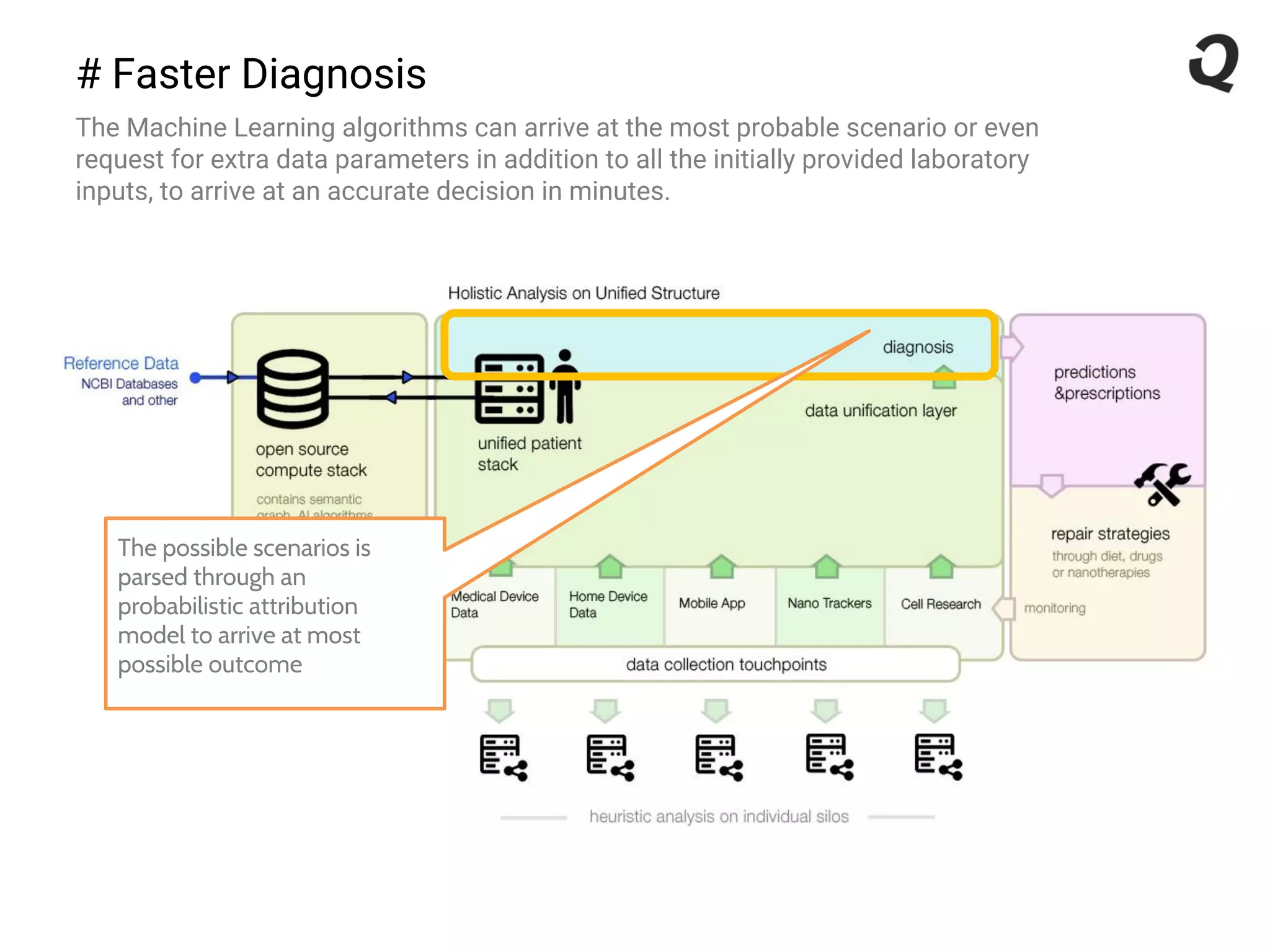
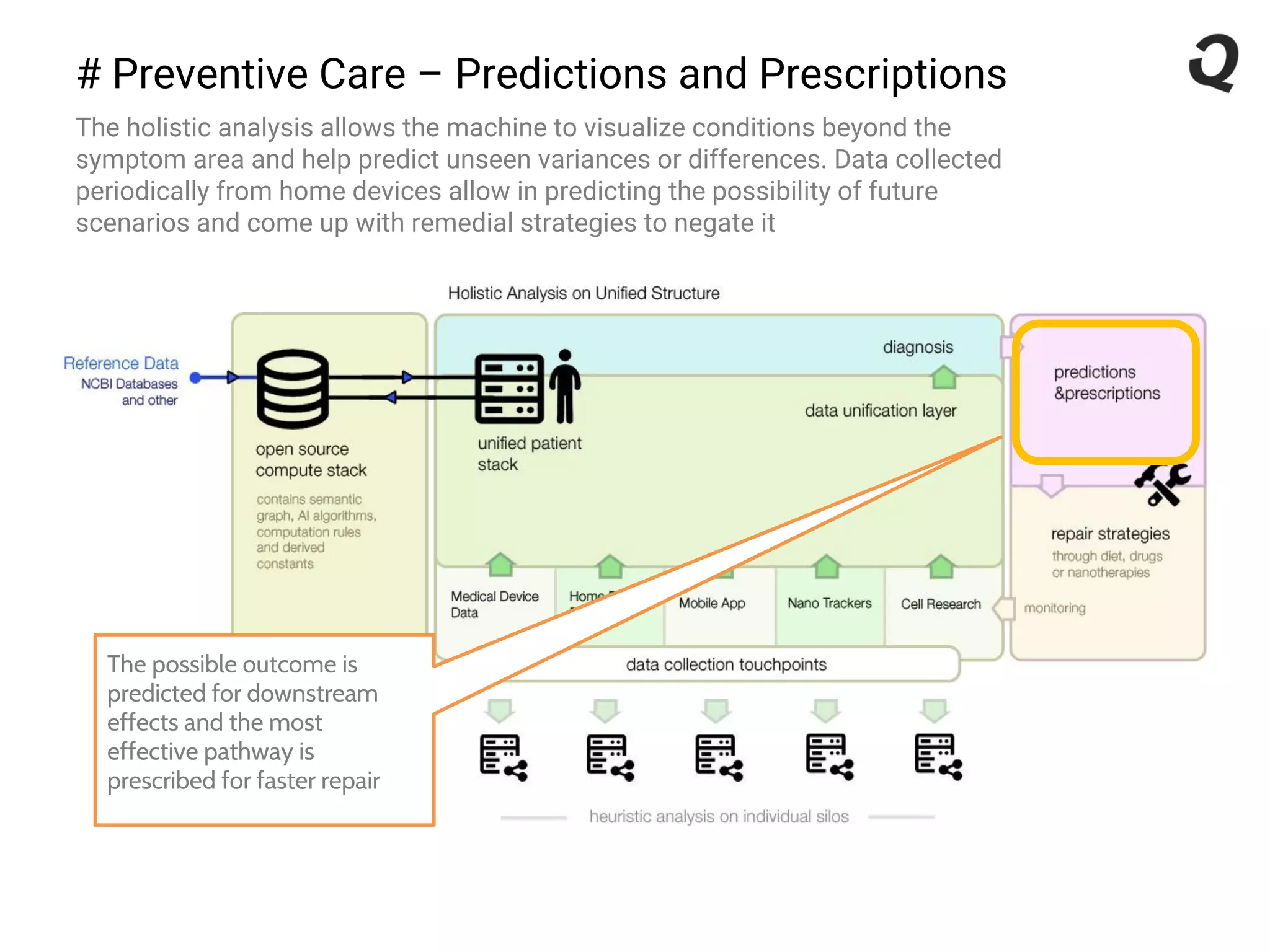
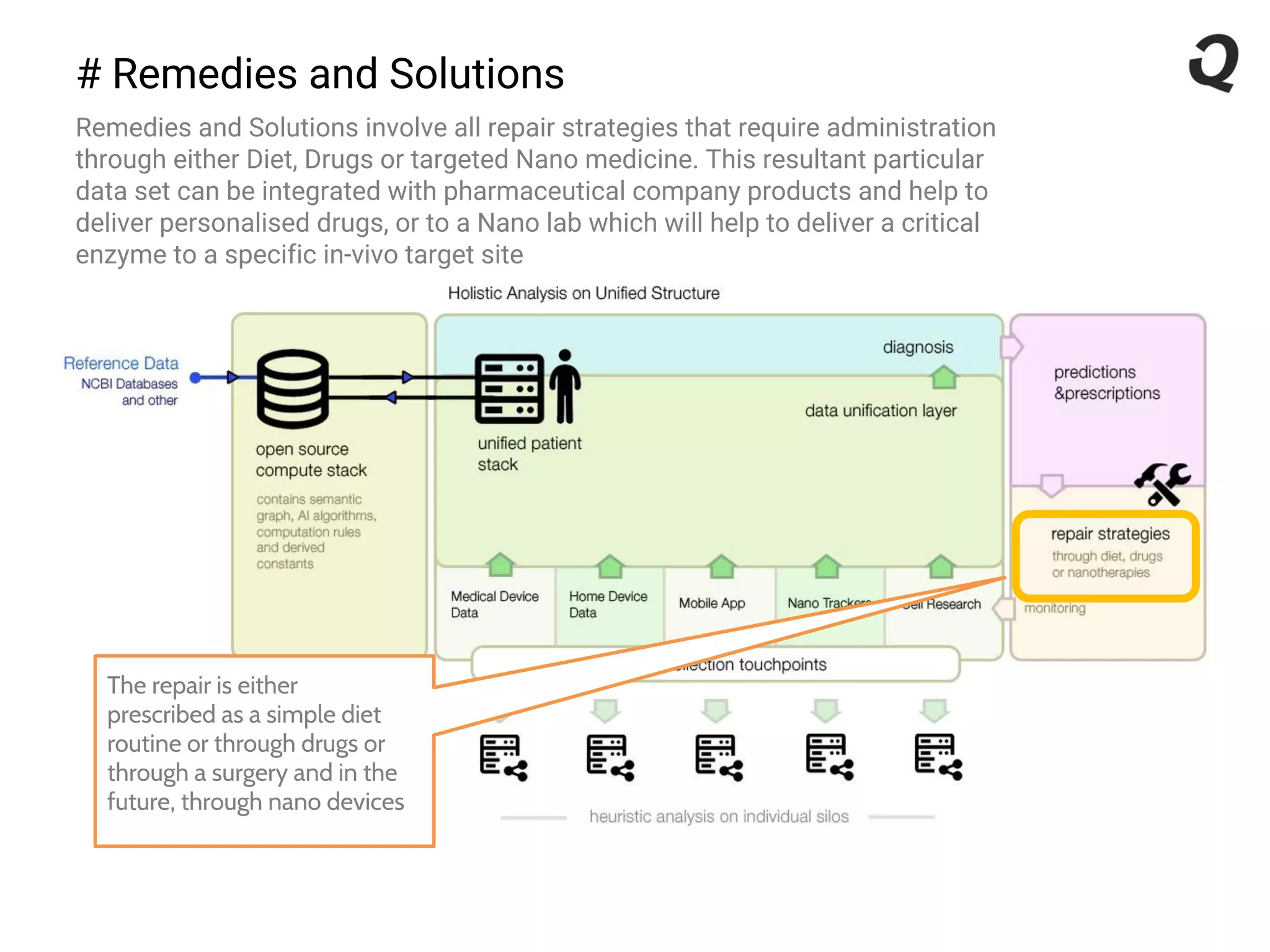
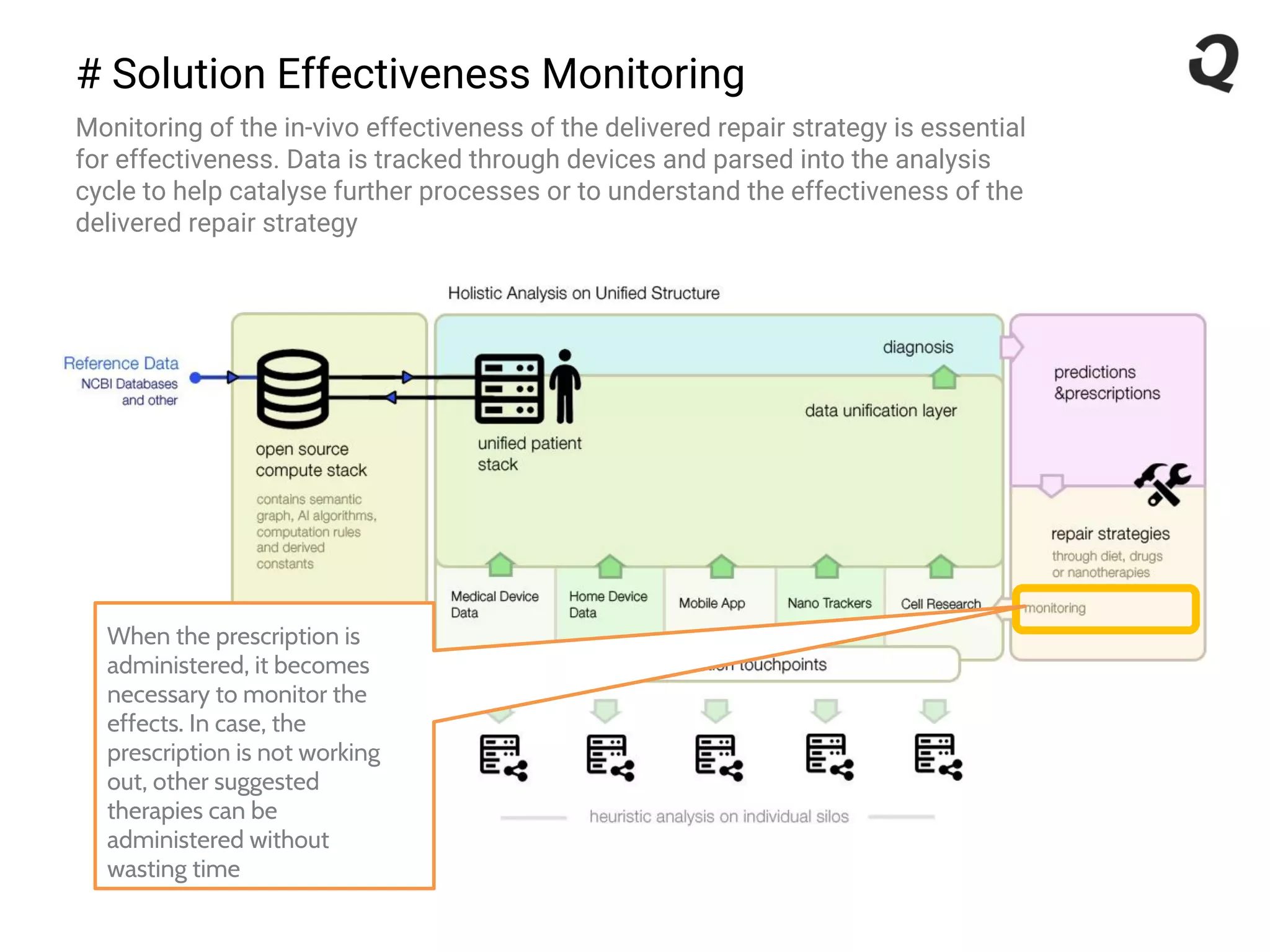
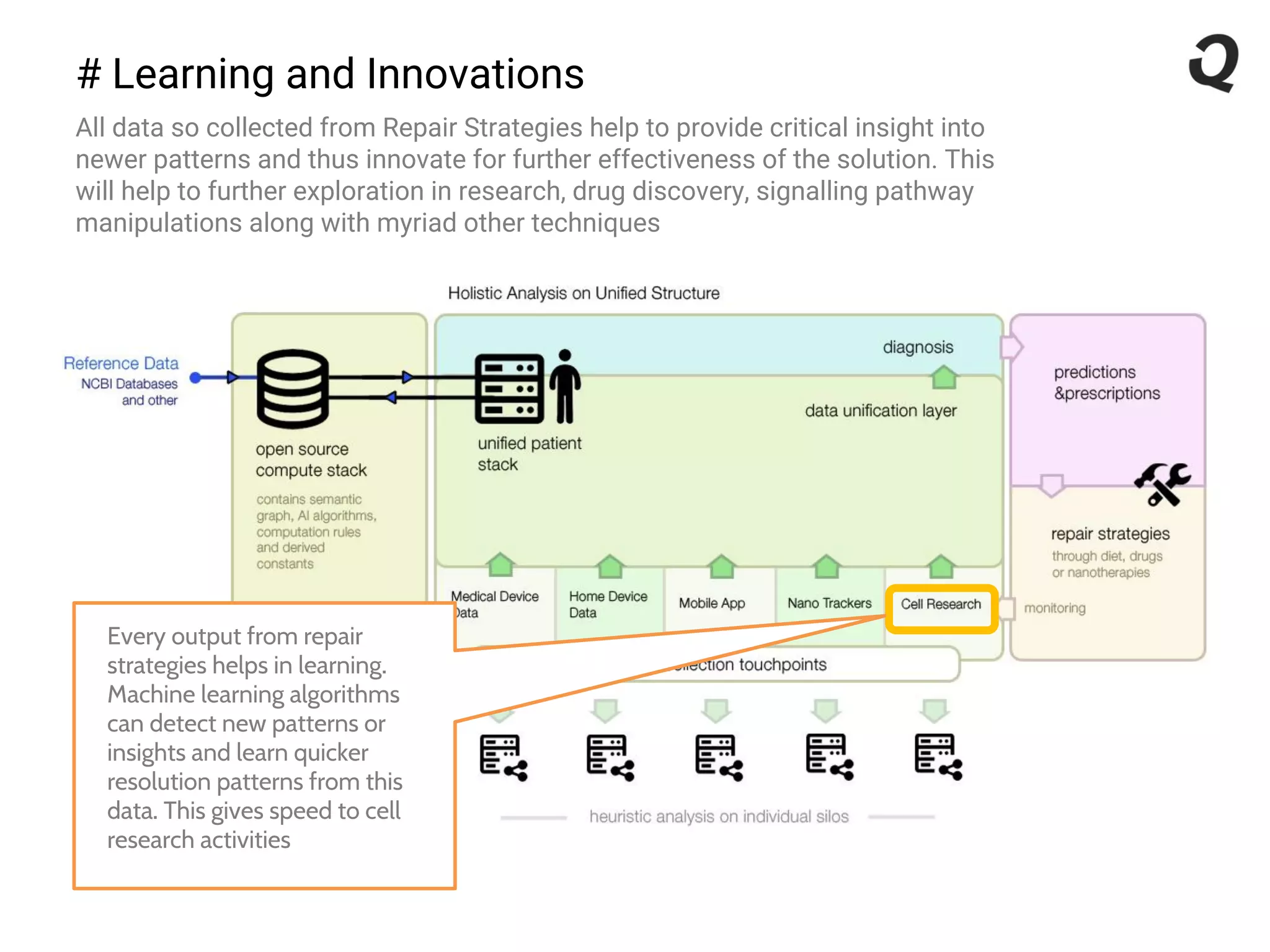
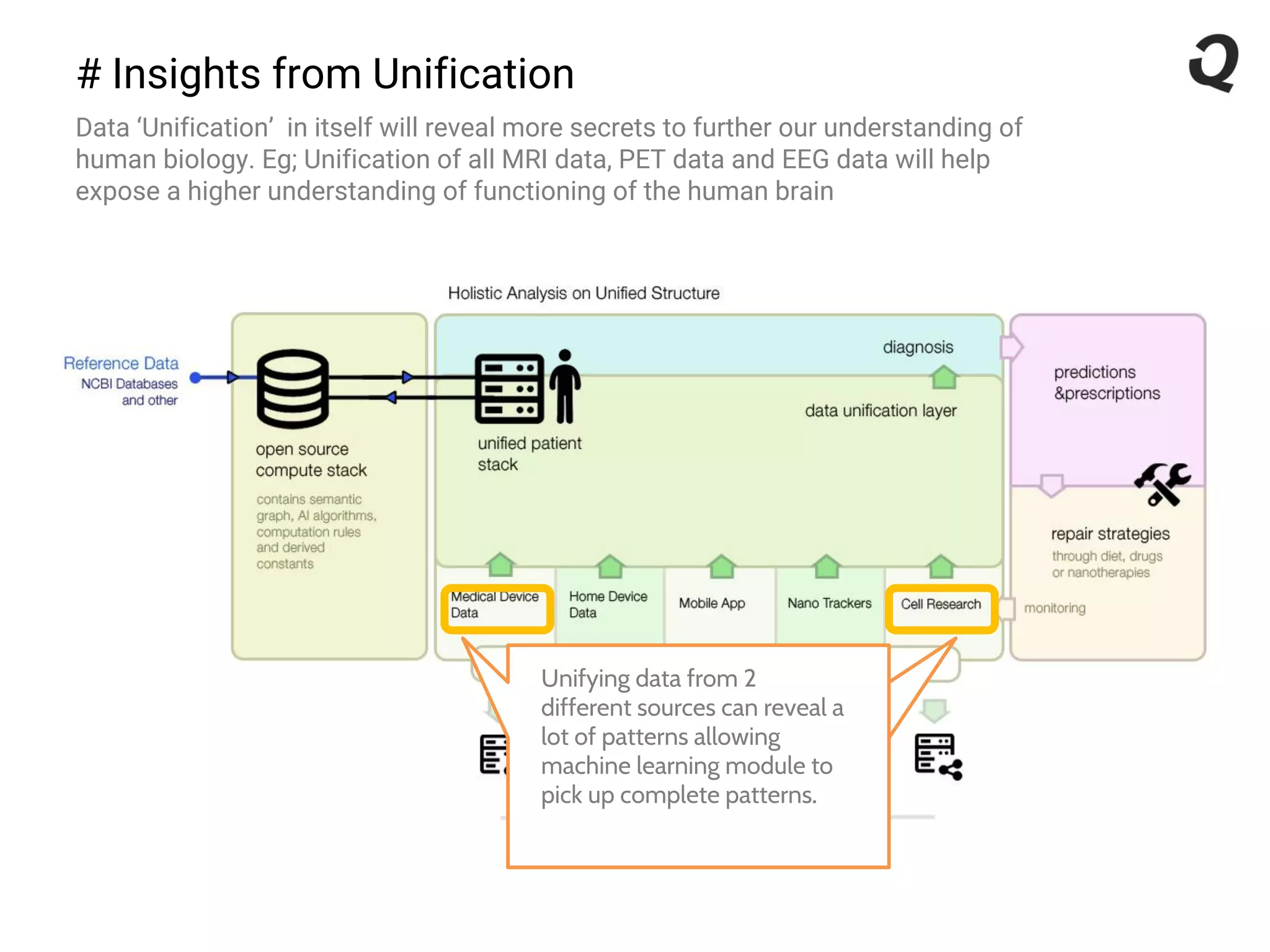
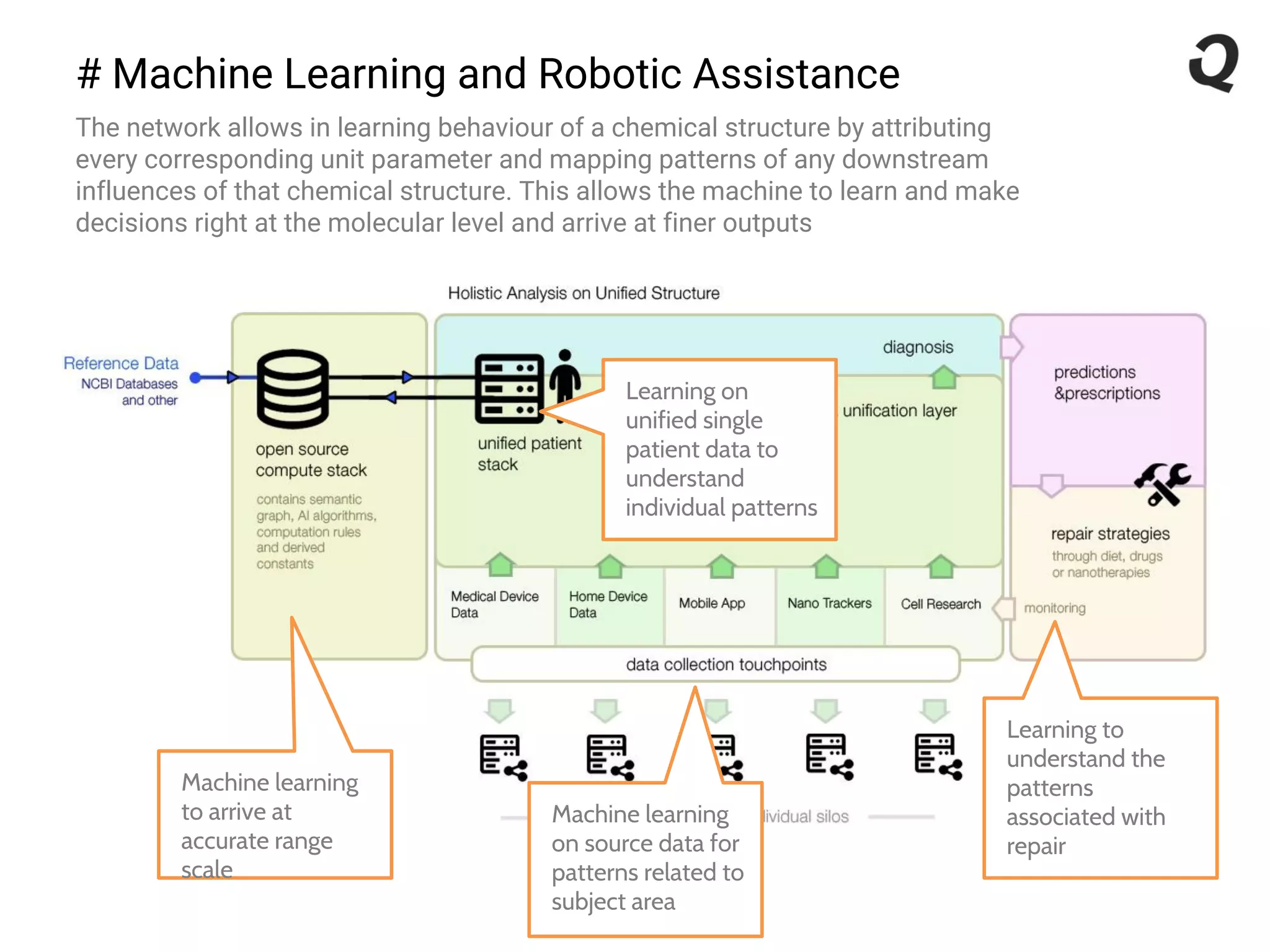


The document discusses the importance of a robust data infrastructure in healthcare, which could save over a million lives annually by improving diagnostic accuracy and reducing the time taken to make decisions. It introduces the Quahog decision platform, which integrates medical data from various sources into a unified system for personalized medicine and faster diagnoses. The platform utilizes machine learning to analyze data comprehensively, enabling predictive care and more effective treatments, ultimately transforming healthcare management.






























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)




