Downloaded 131 times


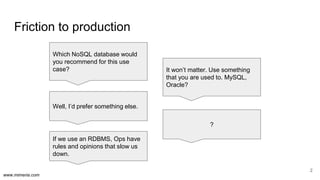
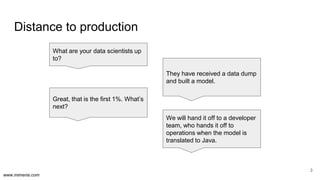

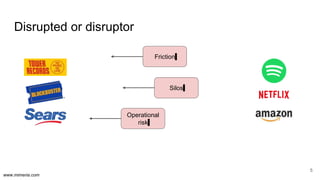
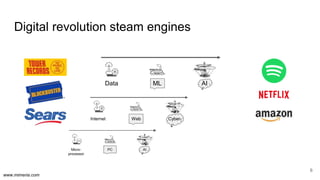
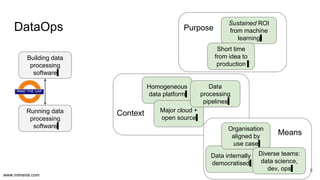
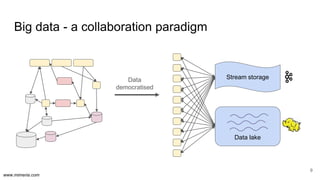
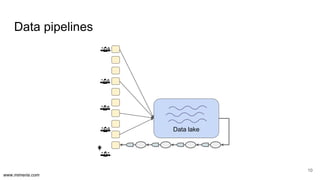
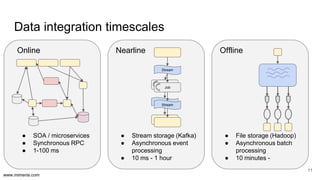
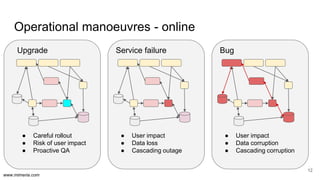
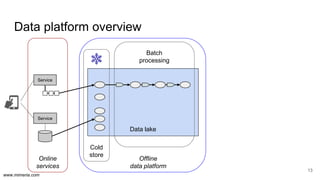
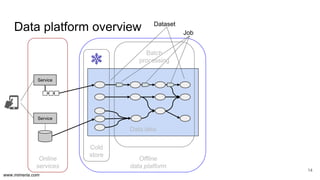
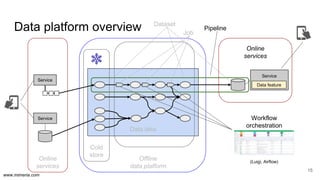
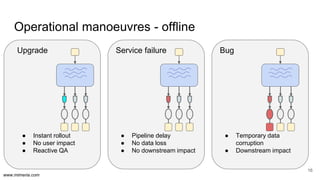
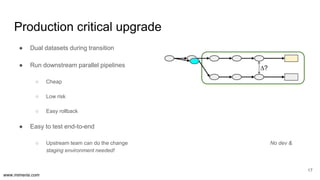
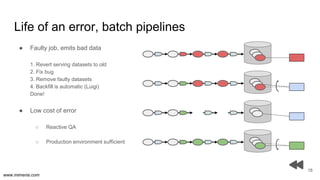
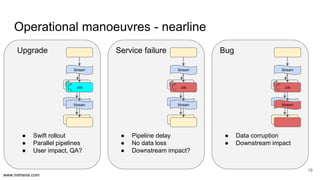
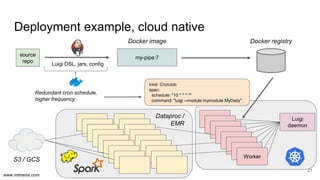
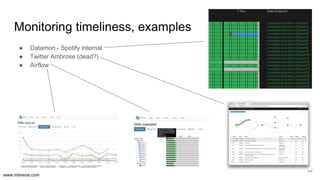
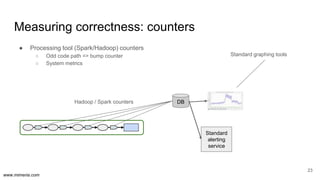
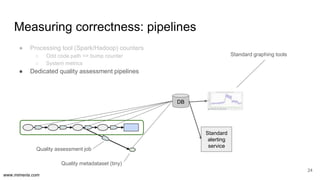
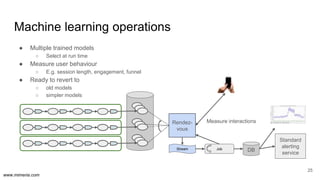
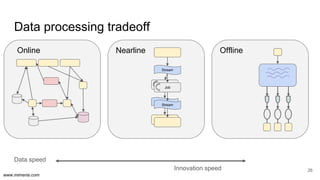

The document discusses the implementation of DataOps, emphasizing the importance of minimizing operational silos and friction in data processing pipelines. It highlights various strategies for efficient data management, including the use of machine learning, cloud services, and open-source tools for quick deployment and testing. Key aspects include managing errors in batch and stream processing, rollout strategies, and maintaining data quality through monitoring and assessment.























































































