Download to read offline









![11
• Feature Extraction
• TF-IDF
• Word2Vec
• Dimensionality reduction
• Training
• Logistic Regression
• SVM
• Naïve Bayes
• LDA
• Prediction
• Evaluation metrics
How are we using Spark?
[1.0, [1.0, 0.0, 3.0]]
Feature
Extraction
Training
Prediction](https://image.slidesharecdn.com/ddtx2016casbon16x9-160119171728/75/Data-Day-TX-2016-Jan-16-2016-11-2048.jpg)
![12
Feature Extraction
Extract
Content
Tokenize
Bigrams
Trigrams
Feature
Lookup
[1.0, 0.0, 3.0]
Vector](https://image.slidesharecdn.com/ddtx2016casbon16x9-160119171728/75/Data-Day-TX-2016-Jan-16-2016-12-2048.jpg)
![13
Training
LogisticRegression
WithLBFGS
[1.0, [1.0, 0.0, 3.0]]
LabeledPoint
Model
Storage
[1.0, 0.0, 3.0]
Vector
Add
classification
LogisticRegressionModel](https://image.slidesharecdn.com/ddtx2016casbon16x9-160119171728/75/Data-Day-TX-2016-Jan-16-2016-13-2048.jpg)
![14
Prediction
Extract
Content
Tokenize
Bigrams
Trigrams
Feature
Lookup
[0.0, 1.0, 4.0]
Vector
Model
Lookup
Predict
New tweet
[0.0, 1.0, 4.0]
Vector
Classification
Lookup](https://image.slidesharecdn.com/ddtx2016casbon16x9-160119171728/75/Data-Day-TX-2016-Jan-16-2016-14-2048.jpg)






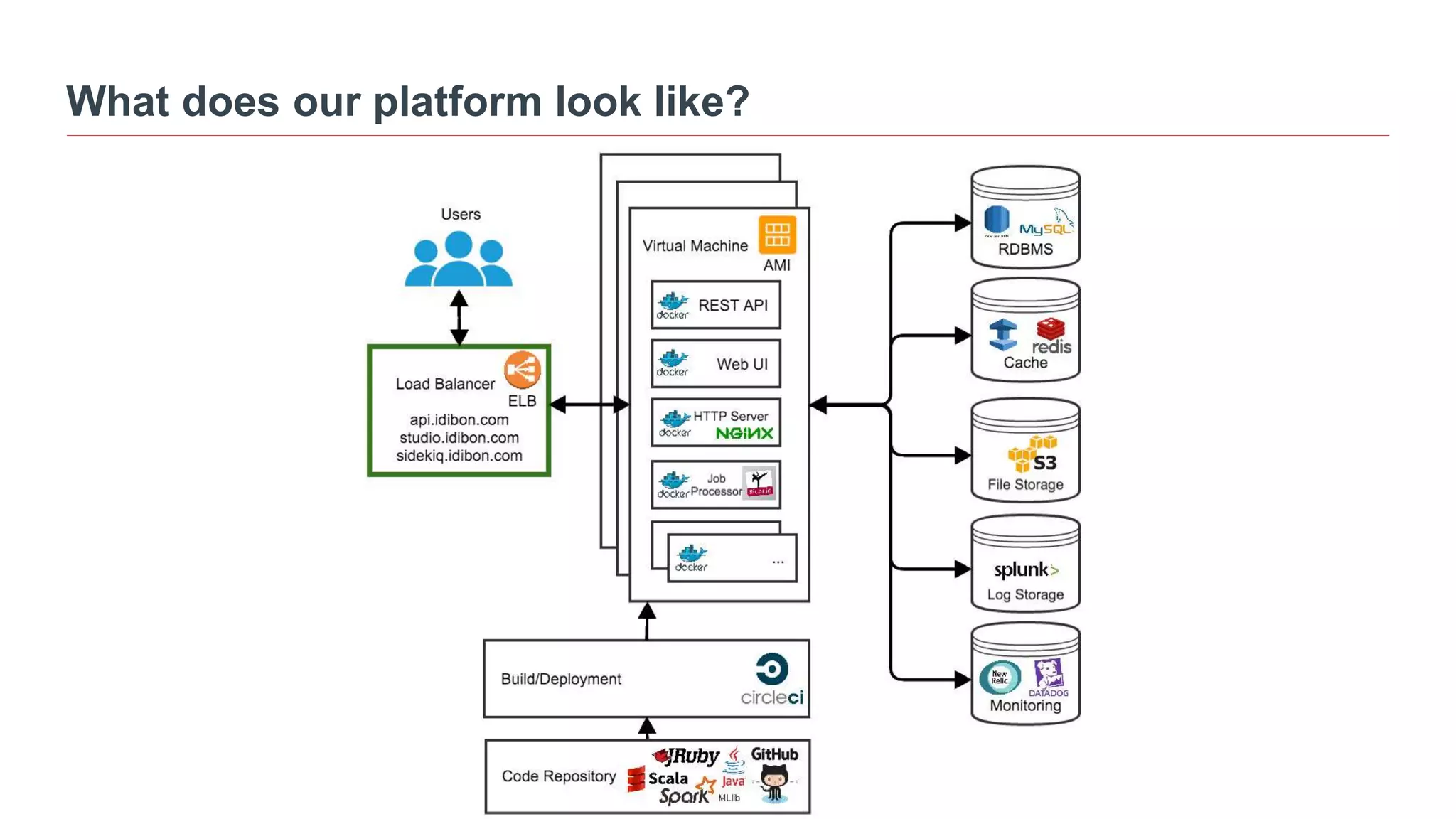
Michelle Casbon presented on Idibon's scalable natural language processing (NLP) services. Idibon uses machine learning to analyze text in any language. Their platform uses Spark for tasks like feature extraction, training models, and prediction. This allows them to process thousands of predictions per second and continuously train models. Idibon also developed a persistence layer and REST API to integrate Spark models into their existing systems and allow for real-time operationalization of many models across different platforms. Their goal is to build performant NLP systems that are faster, better, and can rapidly incorporate new features through tools like Spark.


































































