Downloaded 88 times



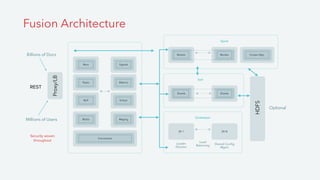













Fusion is a scalable search and analytics platform built on Apache Lucene and Solr. It allows users to easily ingest and analyze large amounts of data to power machine learning, recommendations, and personalization. Fusion leverages proven frameworks like Spark and Solr to handle large datasets and scales to support billions of documents and millions of users. It provides data exploration, visualization, natural language processing and out-of-the-box recommender systems.








































































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)














![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

















