


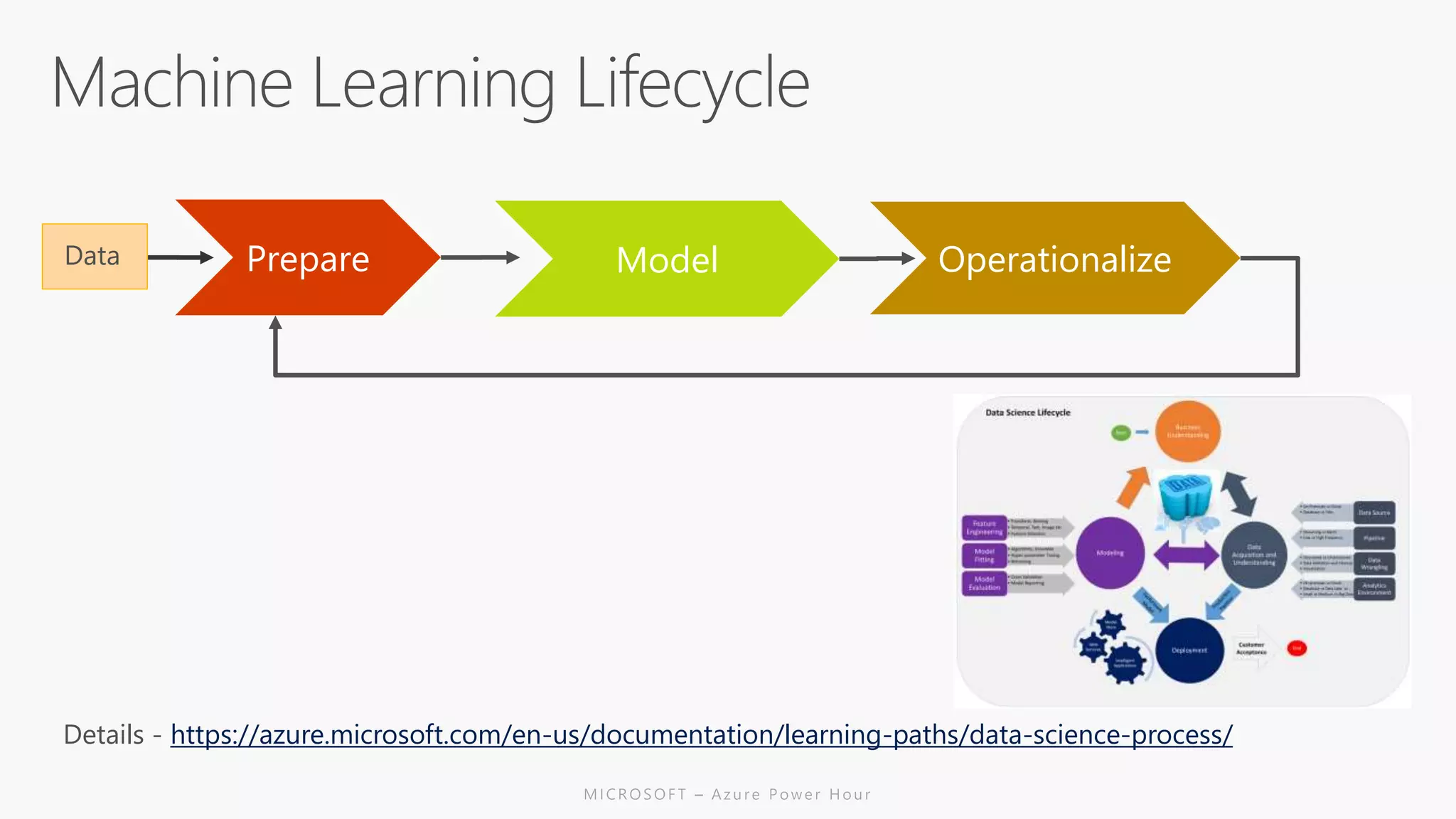
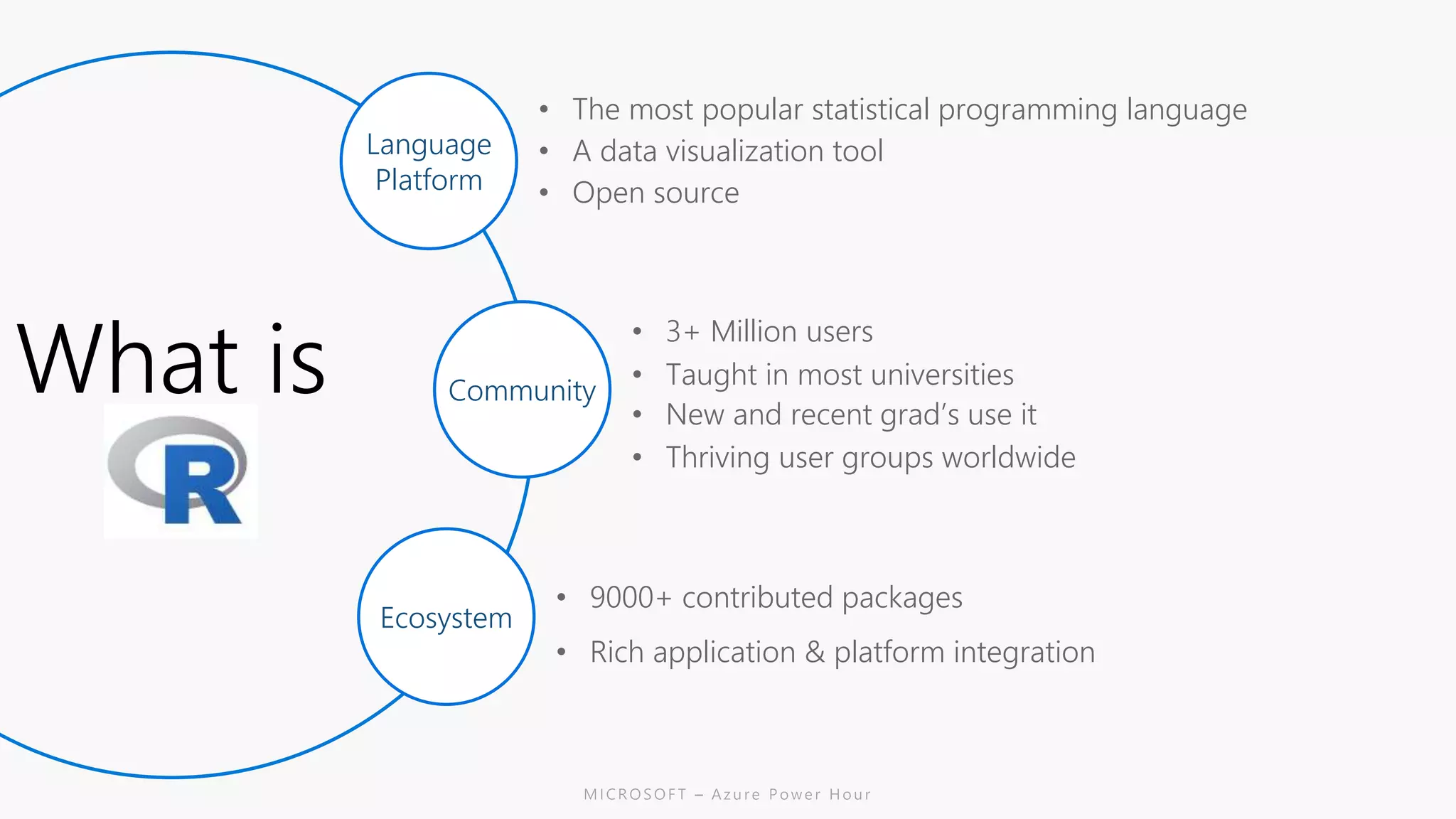
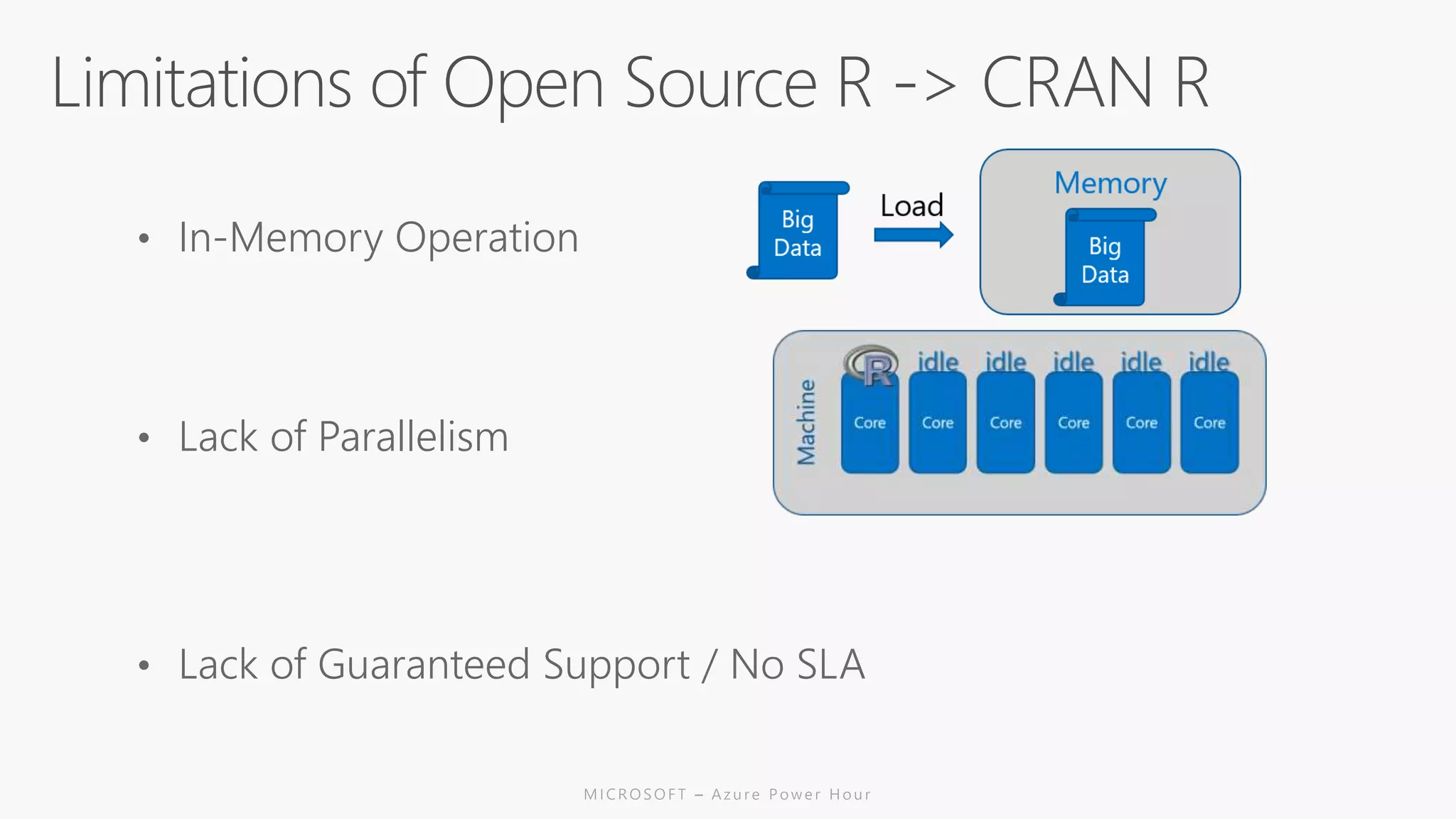


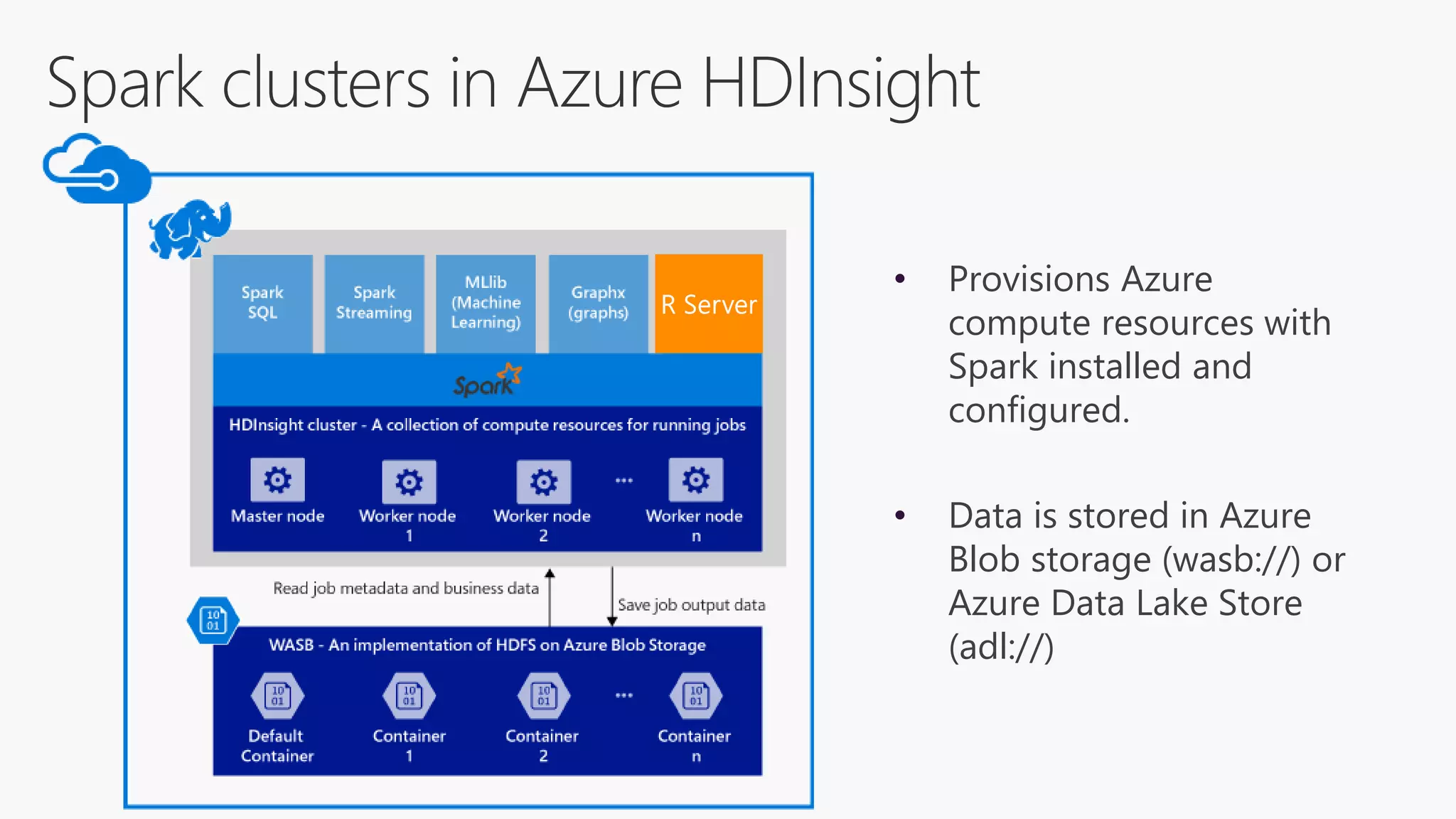
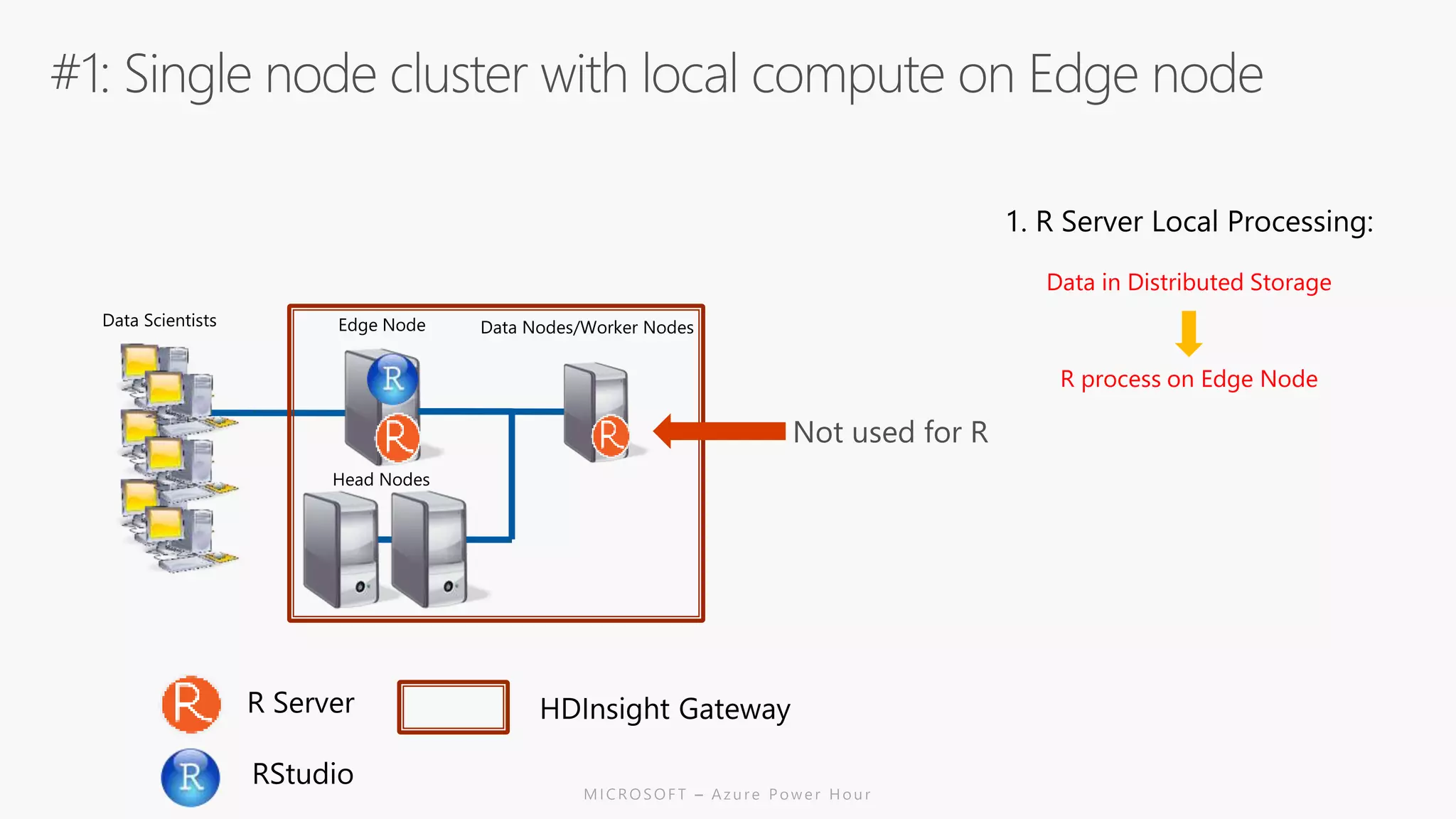
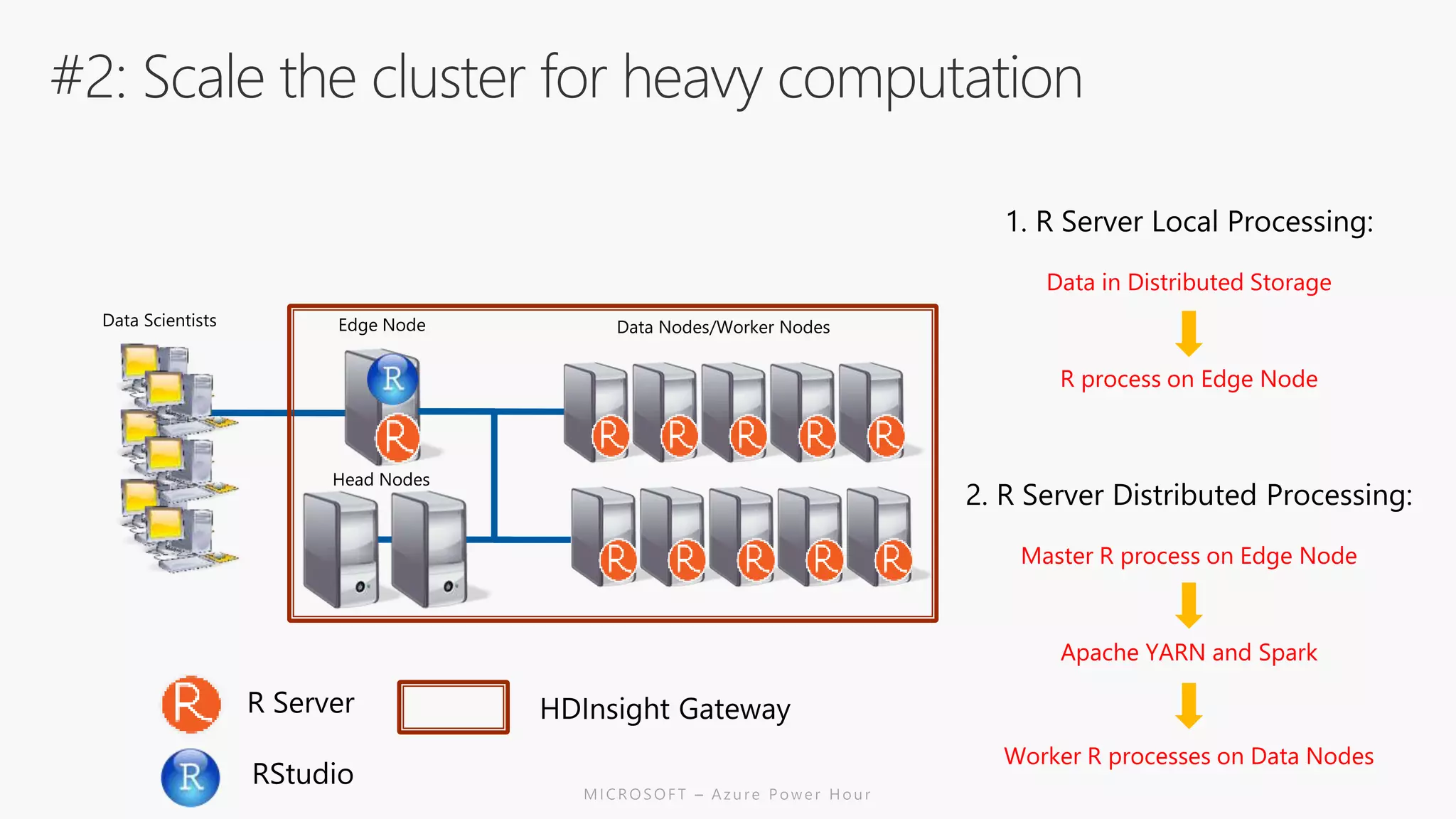


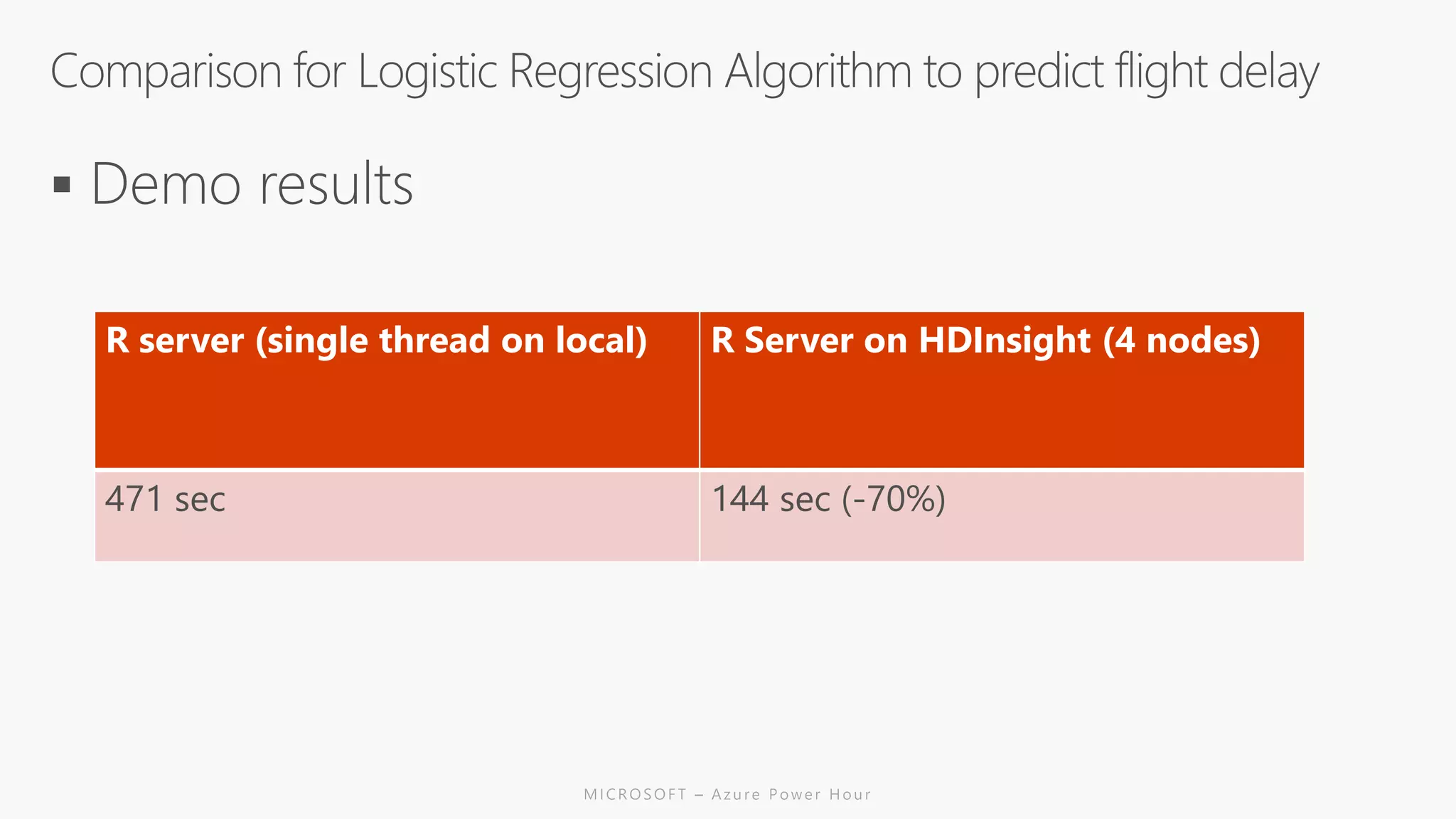



The document discusses the features and capabilities of R, a popular open-source statistical programming language used for data analysis and visualization, which is supported by a vast community and numerous packages. It outlines the integration of R with Azure services, including Azure Compute and Spark, and details specific functions for processing and analysis. Additionally, it provides links to resources for further learning and implementation of R in cloud environments.












































![[Research] azure ml anatomy of a machine learning service - Sharat Chikkerur](https://cdn.slidesharecdn.com/ss_thumbnails/researchazuremlanatomyofamachinelearningservice-sharatchikkerur-150820102331-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















