Download as PDF, PPTX










![Basic Parallelized FTRL in Spark
16
def train(examples: RDD[LearningExample]): Unit={
val delta = examples
.repartition(numWorkers)
.mapPartitions(xs => updatePartition(xs, weights, counts))
.treeReduce{case(a, b) => (a._1+b._1, a._2+b._2)}
weights += delta._1 / numWorkers.toDouble
counts += delta._2 / numWorkers.toDouble
}
def updatePartition(examples: Iterator[LearningExample],
weights: DenseVector[Double],
counts: DenseVector[Double]):
Iterator[(DenseVector[Double], DenseVector[Double])]=
{
// standard FTRL code for examples
Iterator((deltaWeights, deltaCounts))
}
hack:
actually a single
result, but Spark
expects an iterator!](https://image.slidesharecdn.com/large-scale-ad-ranking-151020053857-lva1-app6892/75/Training-Large-scale-Ad-Ranking-Models-in-Spark-16-2048.jpg)




![Accumulators
21
• Use accumulators for ensuring correctness!
• Example:
- parse data, ignore event if there is a problem with the data
- use accumulator to count these failed lines
class Parser(failedLinesAccumulator: Accumulator[Int]) extends Serializable {
def parse(s: String): Option[Event] = {
try {
// parsing logic goes here
Some(...)
}
catch {
case e: Exception => {
failedLinesAccumulator += 1
None
}
}
}
}
val accumulator = Some(sc.accumulator(0, “failed lines”))
val parser = new Parser(accumulator)
val events = sc.textFile(“hdfs:///myfile”)
.flatMap(s => parser.parse(s))](https://image.slidesharecdn.com/large-scale-ad-ranking-151020053857-lva1-app6892/75/Training-Large-scale-Ad-Ranking-Models-in-Spark-21-2048.jpg)

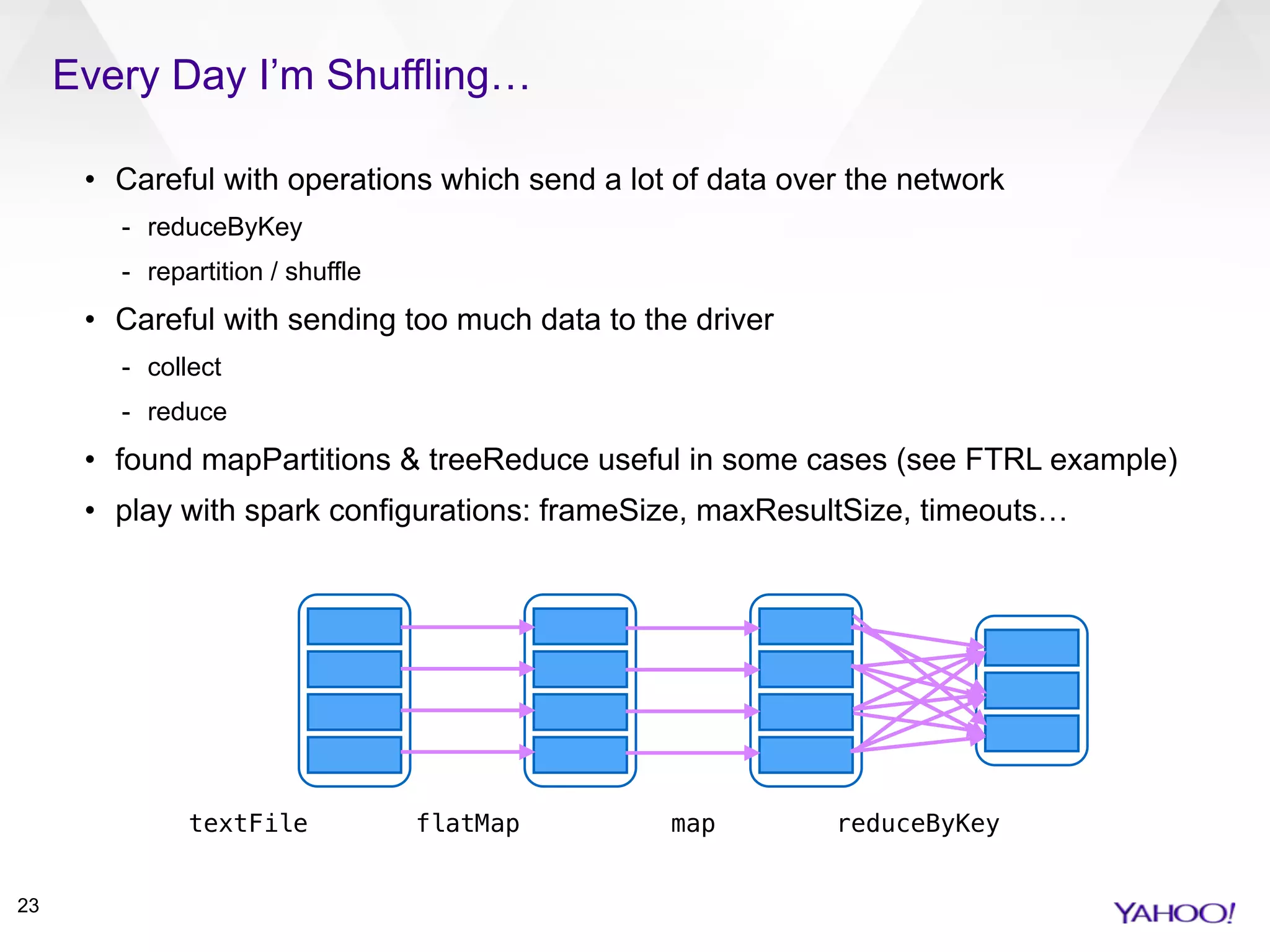



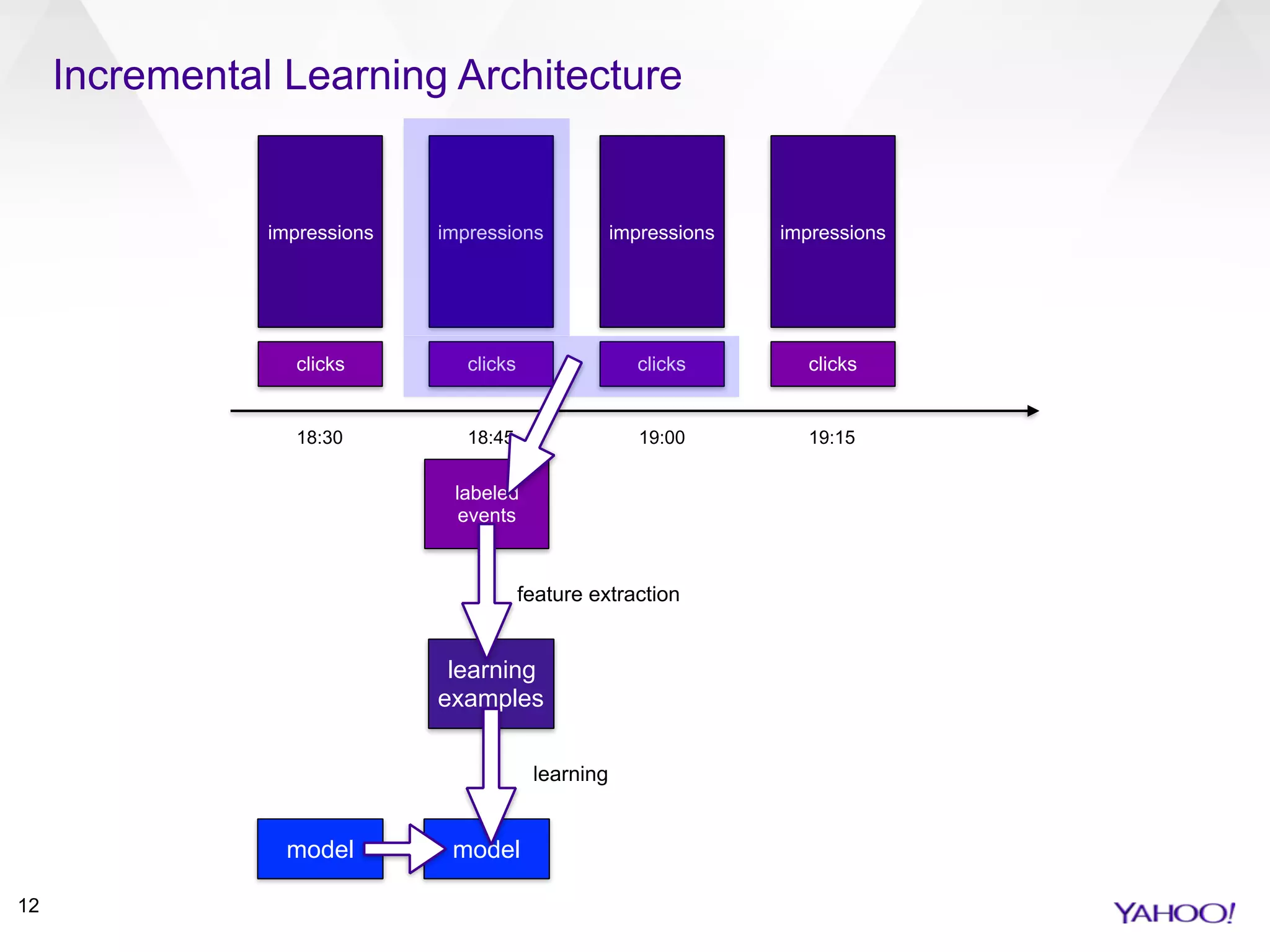
This document summarizes Patrick Pletscher's presentation on training large-scale ad ranking models in Apache Spark. It discusses using Spark to implement logistic regression for click-through rate prediction on billions of daily ad impressions at Yahoo. Key points include joining impression and click data, implementing an incremental learning architecture in Spark, using feature hashing and online learning algorithms like follow-the-regularized-leader for model training, and lessons learned around Spark configurations, accumulators, and RDDs vs DataFrames.



































































