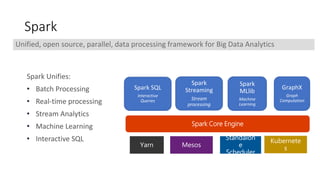
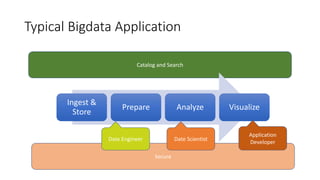
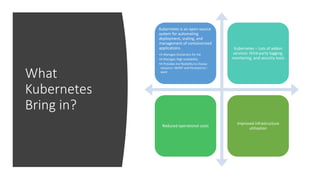
The document discusses the serverless Spark framework and its integration with Kubernetes for big data analytics, outlining various deployment options, including multitenant Spark clusters and function as a service. It emphasizes the advantages of Kubernetes, such as high availability, flexibility, and reduced operational costs. Additionally, the document highlights the role of data scientists in utilizing Spark for various analytics tasks and provides references for further resources.











































![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)



























![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





