The document discusses the significance of Extensible Markup Language (XML), highlighting its simplicity, success, and solid foundation in data storage and exchange. It covers XML syntax, rules, the differences between XML and HTML, and advanced concepts like XSL and XML Schema. The future of XML is predicted to include widespread usage across various devices and applications, potentially replacing other formats in information storage.




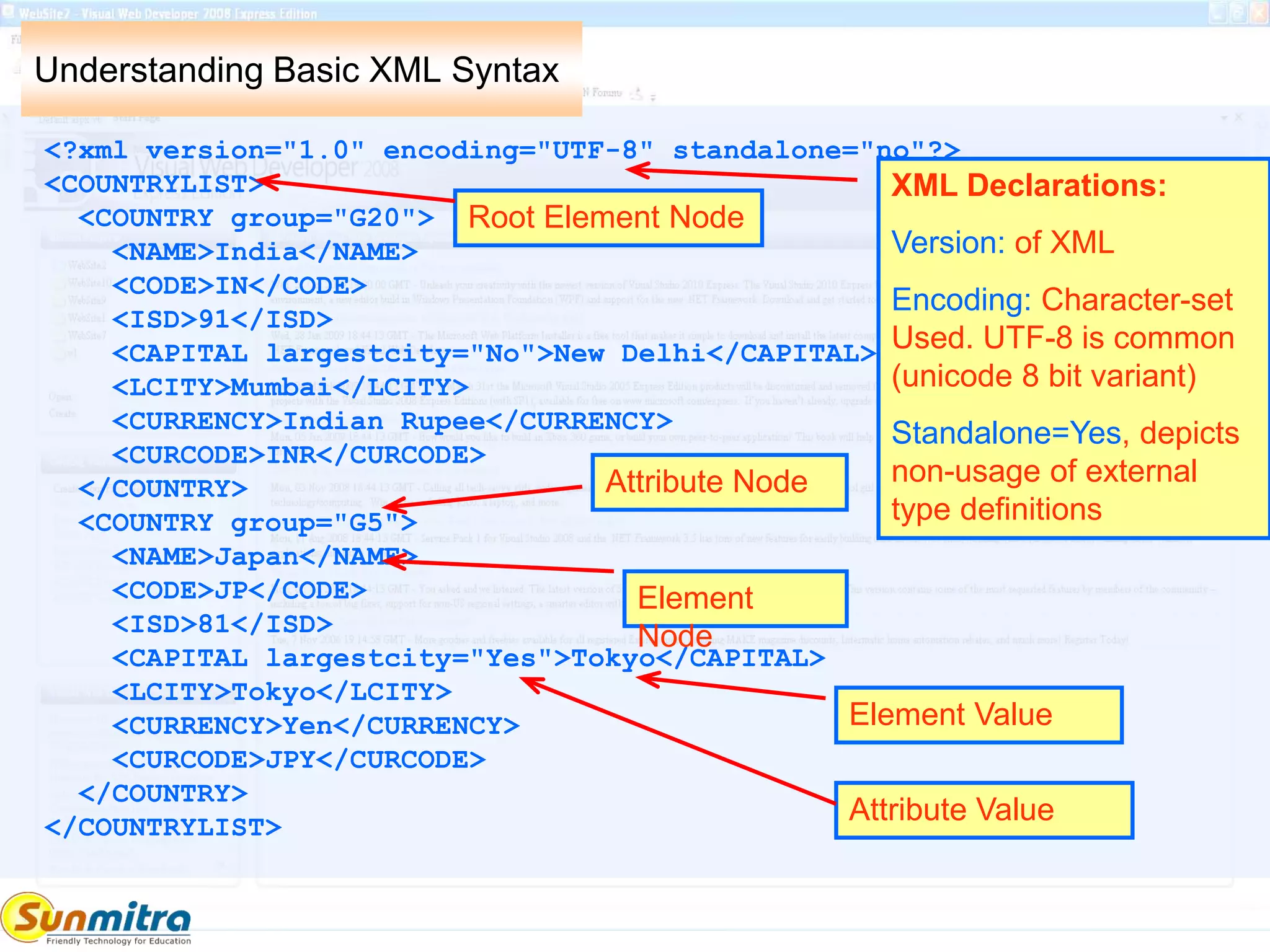
![XML Constituents
Elements
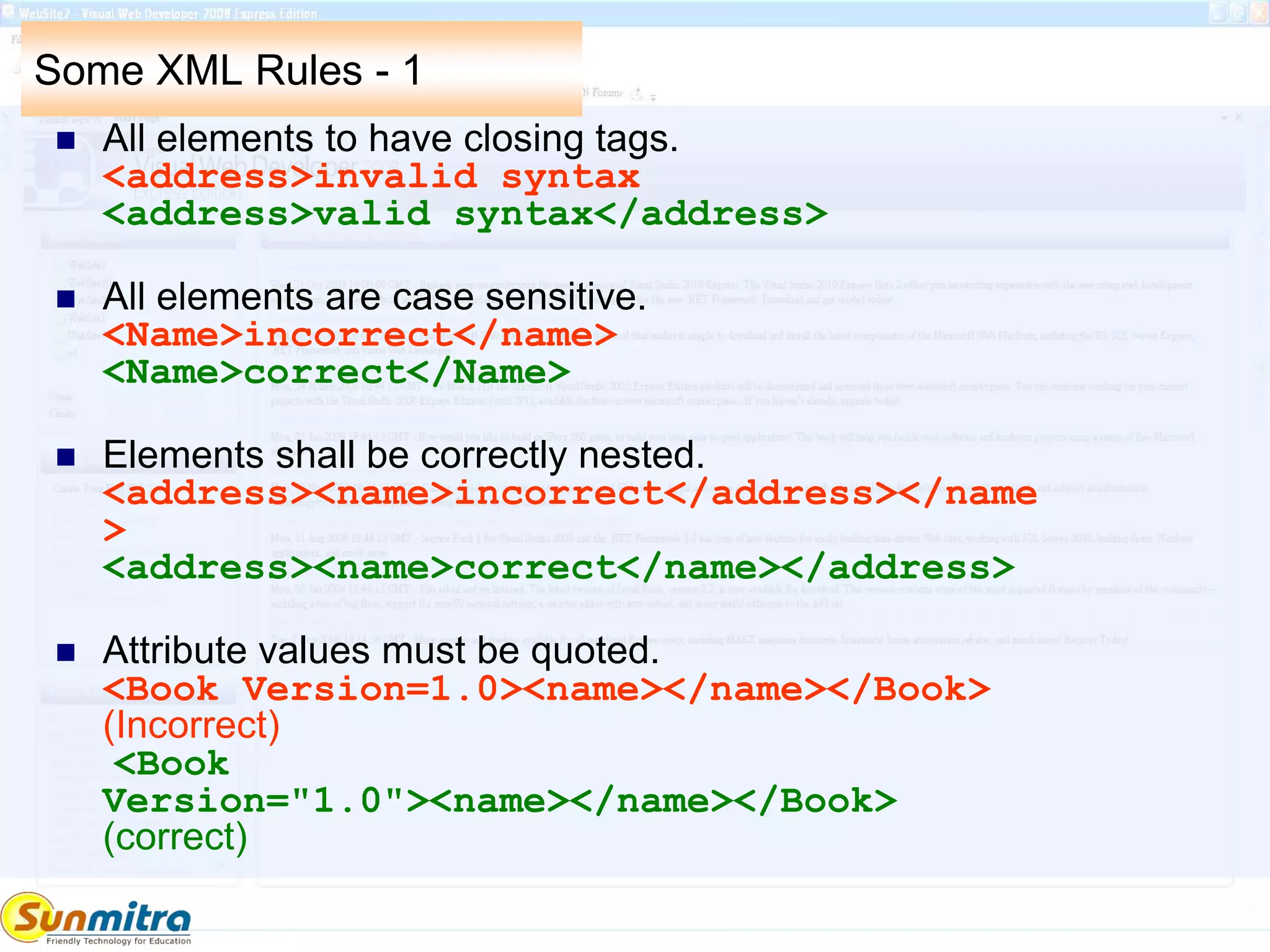
<address><name>somename</name></address>
Attributes
<Book Version="1.0"><name></name></Book>
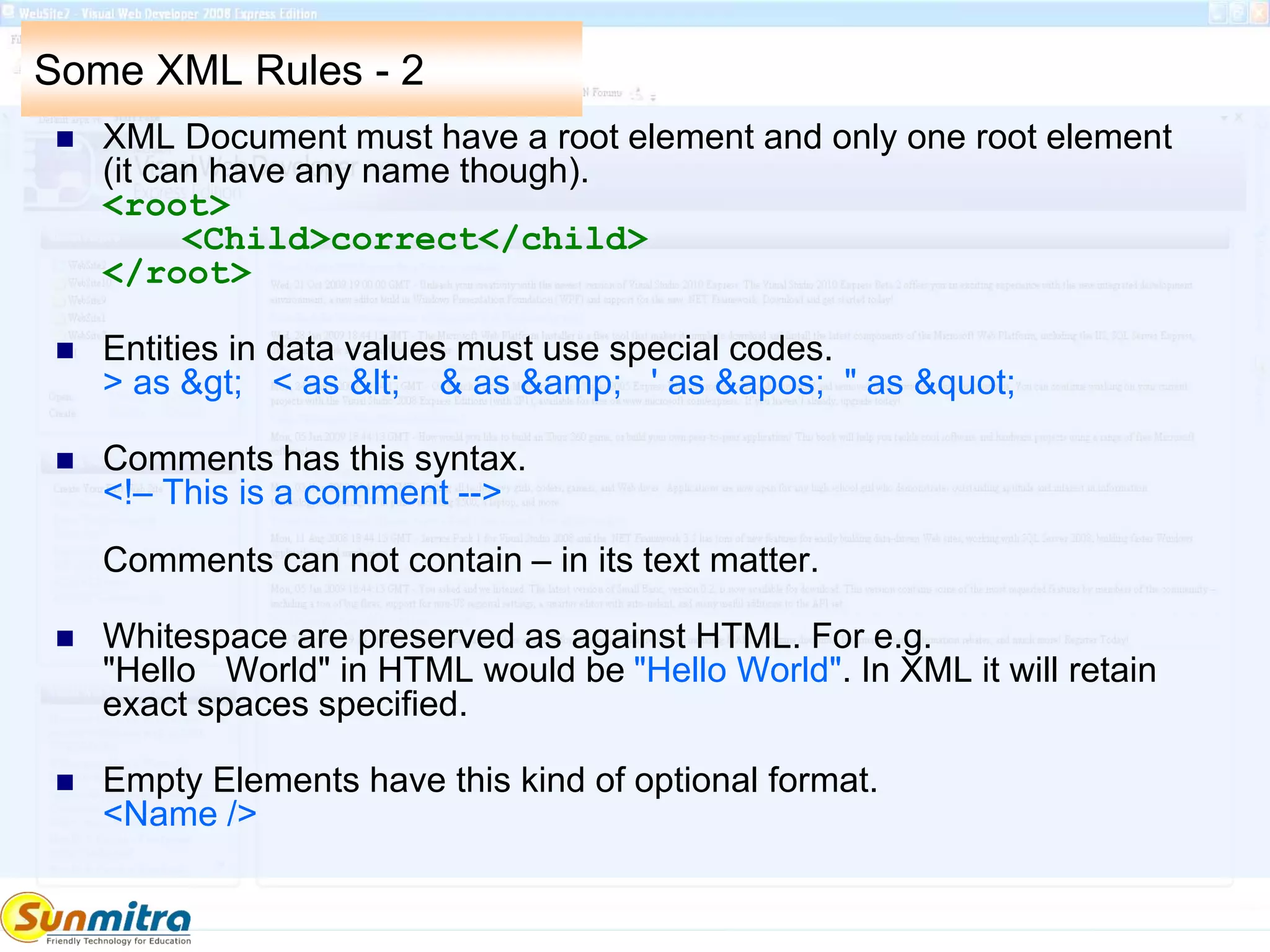
Five predefined Entities to allow for special charaters in the PCDATA
area.
> to >
< to <
& to &
' to '
" to "
CDATA section (Character Data Not to be parsed). This is meant for
putting lot of code like or general purpose data. Even HTML data can
be put here.
<![CDATA[ ... ]]>
Processing Instructions (PI) or Directives given betweem <? ?>
<?xml-stylesheet type="text/css" href="mySheet.css"?>
or even initial declaration like below is a PI
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
Parsable Character data (PCDATA)
between element <address> start and end
tags.
Attribute has a name and a value in
quotes.](https://image.slidesharecdn.com/basicsofxml-140714034622-phpapp01/75/Basics-of-XML-7-2048.jpg)







![DTD (Document Type Definition)
A DTD is referred within a DOCTYPE
declaration in an XML file such as.
<!DOCTYPE note SYSTEM "Note.dtd">
This DTD file will have the format as
follows.<!DOCTYPE note
[
<!ELEMENT note
(to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
XML file has the root node
named note with four sub-
elements.
The sub-
elements have
the PCDATA
format.](https://image.slidesharecdn.com/basicsofxml-140714034622-phpapp01/75/Basics-of-XML-19-2048.jpg)



















![Xml theory 2005_[ngohaianh.info]_1_introduction-to-xml](https://cdn.slidesharecdn.com/ss_thumbnails/xmltheory2005ngohaianh-140302210326-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
