The document discusses the development and significance of knowledge graphs (KGs) in managing and interpreting vast amounts of data, emphasizing their collaborative construction and the importance of context for improved machine learning performance. It contrasts closed and open KGs with examples such as Microsoft, Google, and Wikidata, highlighting the structural and ontological differences between them, as well as issues related to data quality and linking. The conclusion emphasizes the need for better tools for KG creation and maintenance, along with improved integration and discovery methods.

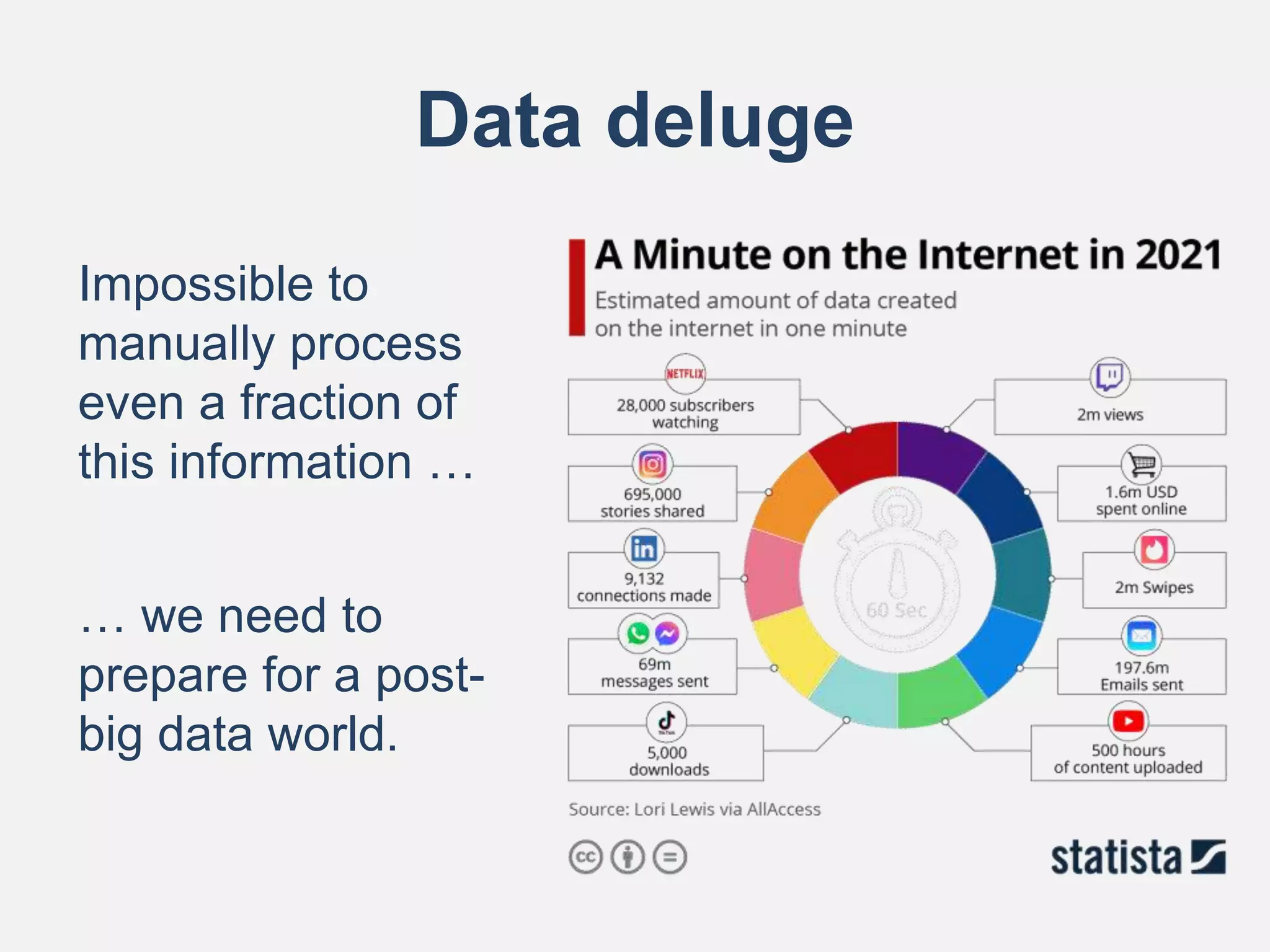



![Knowledge Graphs (KGs)
• Performance and explainability of ML
improves when data is given a context
– a Knowledge Graph increases the informative value
of the collected data that is given to the model
Knowledge Graphs [Paulheim 2017]
– describe real-world entities and their interrelations
– define possible classes and relations of entities in a
schema (ontology)
– allow for interrelating arbitrary entities with each
other](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-6-2048.jpg)
![Knowledge Graphs (KGs)
• Knowledge graphs are (generally) created collaboratively by many
users
• Information can be added in a relatively arbitrary manner as
structural constraints are few
Closed KGs (~2019) [Noy et al., 2019]
Microsoft ~2bn entities, ~55bn facts
Google ~1bn entities, ~70bn assertions
Facebook ~50m entities, ~500m assertions
eBay ~1bn triples
IBM ~100m entities, 5bn relationships
Open KGs (April 2021)
DBpedia ~4.58m entities, ~9.25GB
Yago4 ~50m entities, ~18.4GB
Wikidata ~93m entities, ~99GB](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-7-2048.jpg)
![Schema in KGs
Ontologies as schemas in KGs
An ontology is an “explicit specification of a conceptualization consisting of a set of
objects, and the describable relationships among them”
[Gruber, 1993]
Components of an Ontology
• Classes: abstract groups (sets) of objects that are defined by properties that all its
members share (e.g., Person, Organisation, Event)
• Attributes: characteristics or parameters that objects (and classes) can have (e.g.,
data of birth, longitude, latitude, timestamp)
• Relationships: ways in which classes and individuals can be related to one another
(e.g., role, attributed to, observed by)
• Individuals: Concrete objects that are inherent to the domain of discourse, such as
specific people, organisations or abstract individuals such as numbers (e.g., g, π)](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-9-2048.jpg)
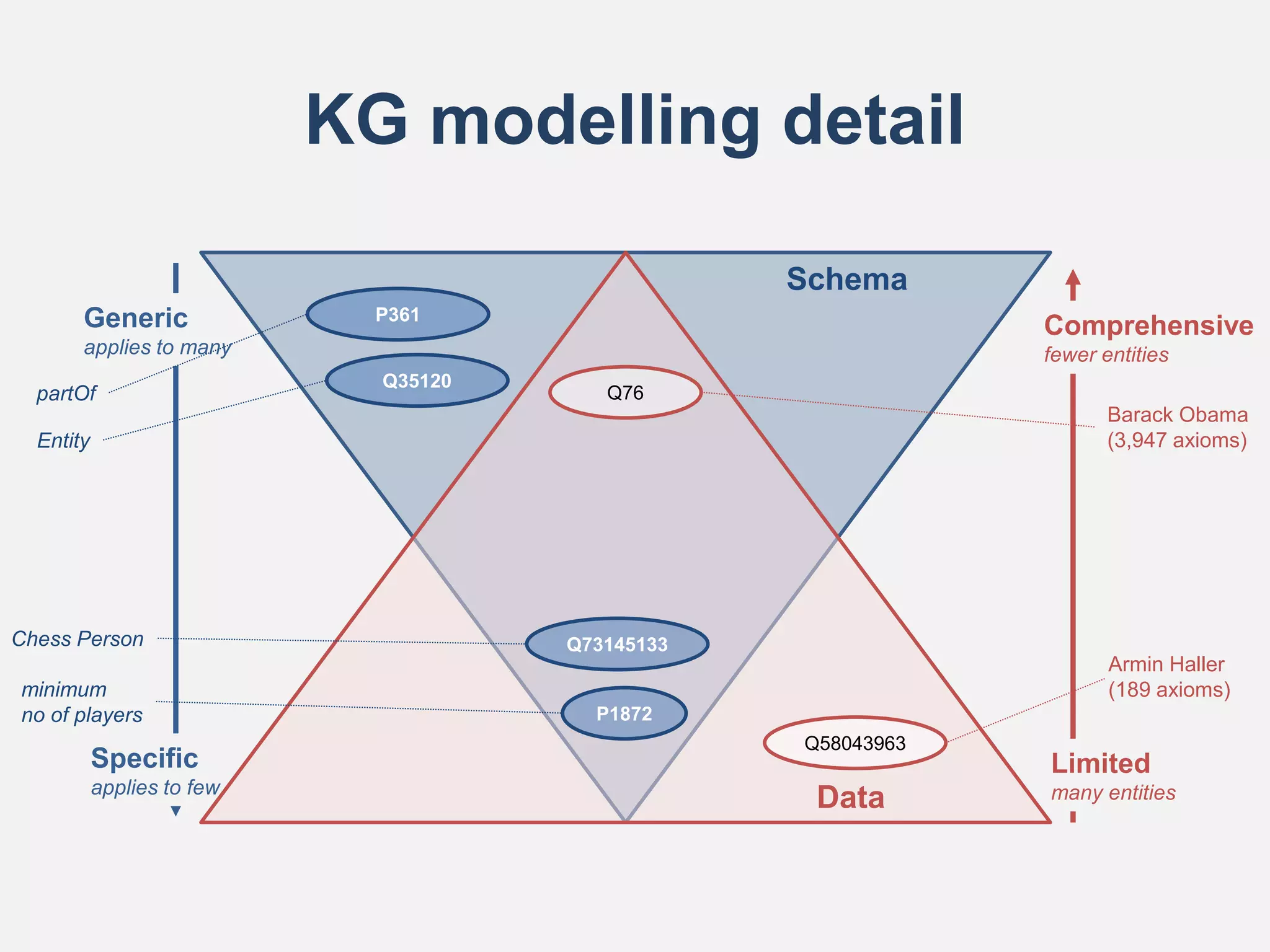
![Types of Schemas (Ontologies)
Level
of
Abstraction
Most
General
Most
Specific
Reusability
Highest
Lowest
Upper
Ontologies
Mid-Level Ontologies
Domain Ontologies
Use-Case Ontologies
e.g., CyC,
SUMO,
DOLCE, BFO,
CYC
e.g., PROV-O,
FOAF, ORG,
SOSA/SSN,
AGRIF
e.g., GO,
ChEBI,
DO,
BTO
[Haller & Polleres, 2020a]](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-11-2048.jpg)
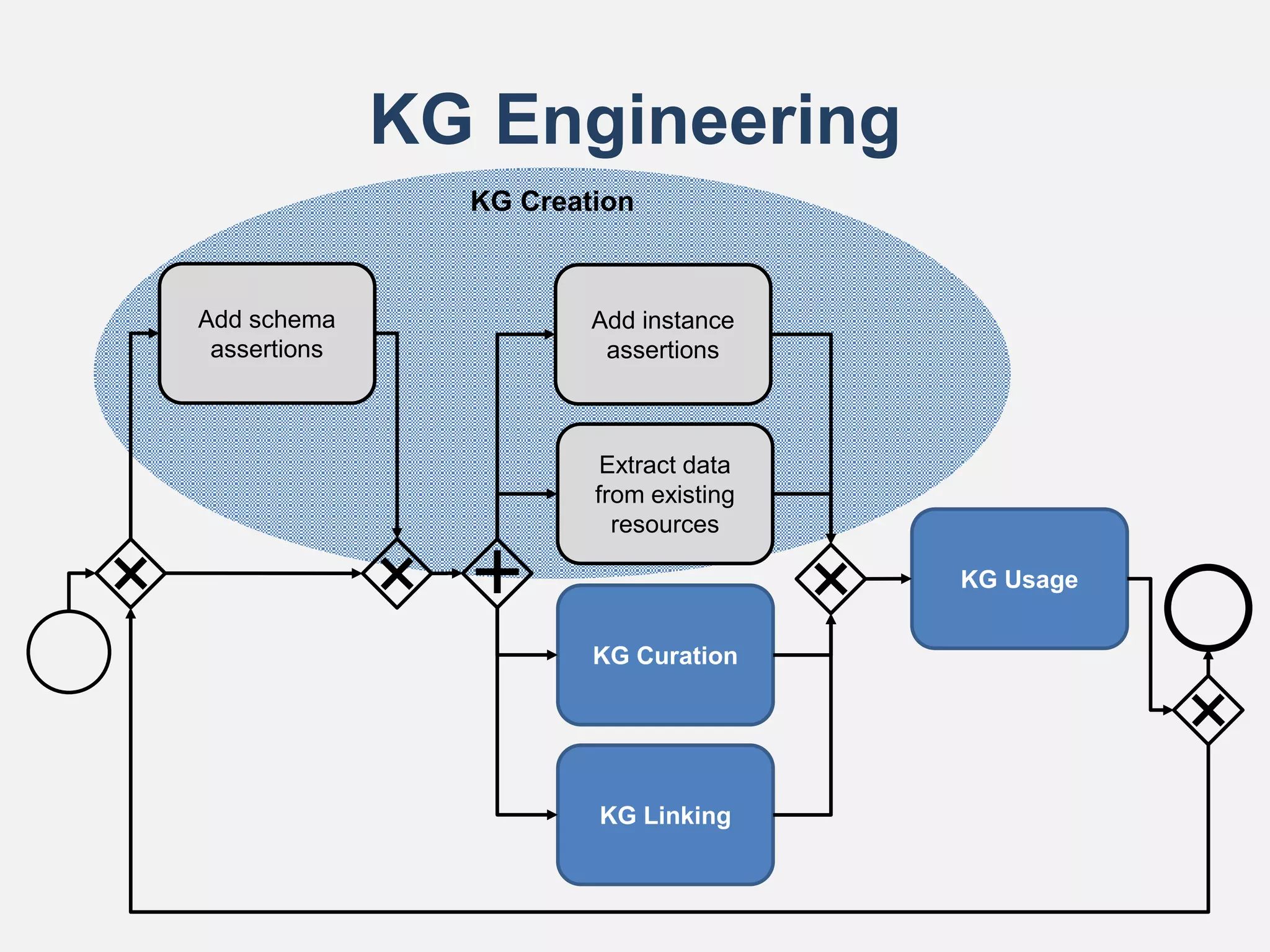
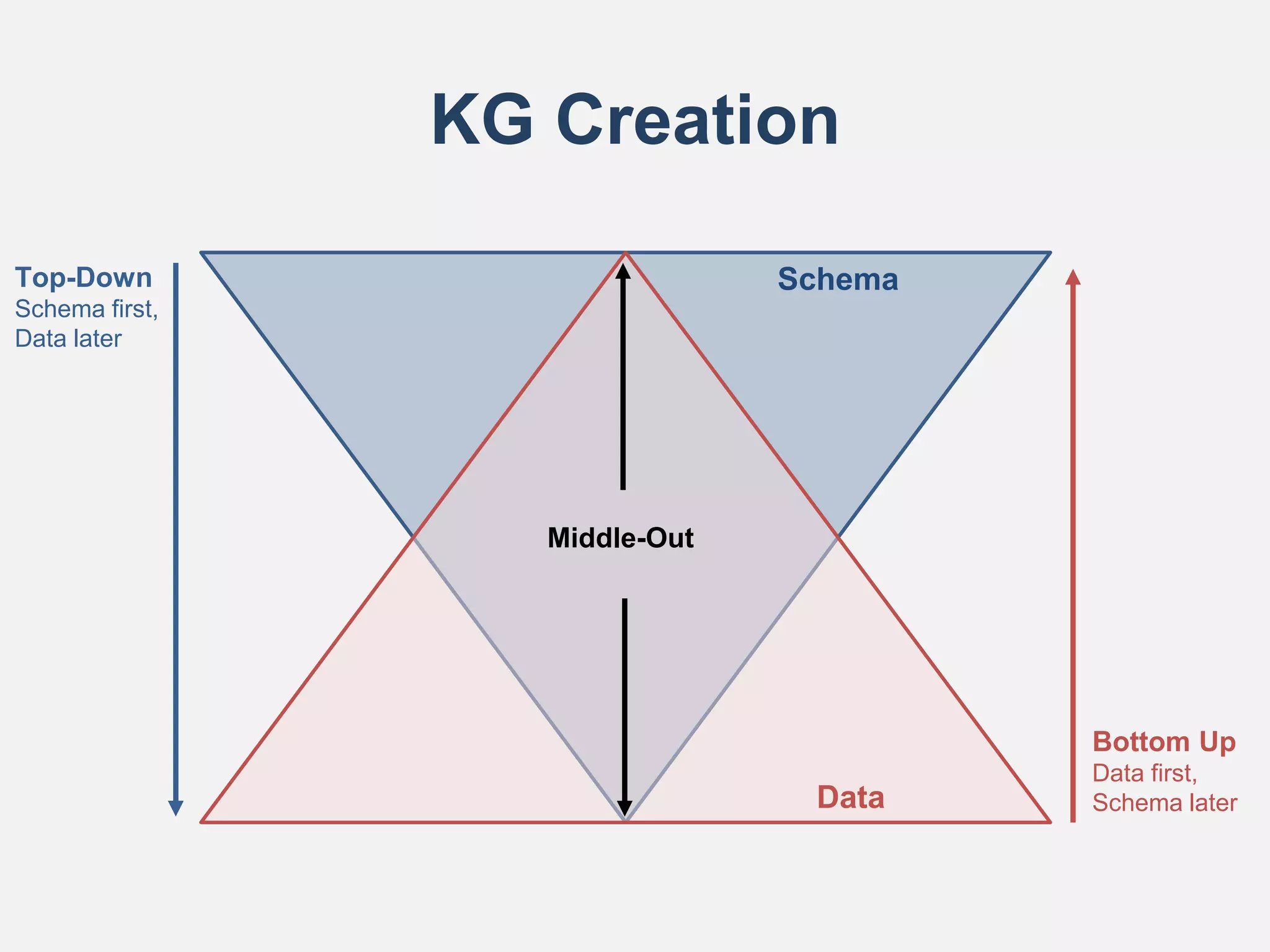
![KG Creation (cont’d)
Bottom-Up KG Creation
• Schema is not defined, and data is added organically and manually using tools such as:
– OntoWiki [Frischmuth et al., 2015]
– Semantic MediaWiki [Krötzsch et al., 2006]
– Wikibase
– Schímatos [Wright et al., 2020]
Top-Down KG Creation
• Schema is created upfront, existing data mapped to schema using languages/tools such as:
– R2RML
– SPARQL Generate [Lefrançois et al., 2017]
– SHACL Rules
– TARQL
– Metadata Extractor & Loader (MEL) [Méndez et al., 2021]
– JSON to RDF Mappings (J2RM) [Méndez et al., 2020]
Middle-Out KG Creation [Sure et al., 2004]
• Schema is partly defined upfront based on use cases, with mappings added later when data
defines semantics](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-14-2048.jpg)


![KG Curation
Correctness
– Evaluation
Accessibility, Accuracy, Consistency, Conciseness, Trustability,
Dynamicity, Representationality [Zaveri et al., 2016]
– Correction
Evaluating data quality (SHACL, SheX)
• Syntactic errors
• Semantic errors
Completeness
– KG Completion [Paulheim, 2017]
Using structural information observed in triples
• Classification
• Probabilistic and Statistical Methods](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-17-2048.jpg)
![KG Linking
Internal vs. External links [Haller et al., 2020b]
– internal links, i.e., links between parts of one coherent KG, i.e., edges linking
nodes within the graph
• Link prediction techniques are used to learn those new links
– external links, i.e., links between different KGs, i.e., edges between nodes from
different graphs, or reusing edges from a different graph to link nodes in one KG
Linking Issues [Haller et al., 2020b]
• References to many inaccessible URIs (i.e., broken links) may render
a KG largely useless
• Changes in linked external KGs are out of control of the KG publisher](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-18-2048.jpg)
![KG Linking
• Ontology links [Haller et al., 2020b]
– class link
t:[dbo:Person, rdfs:subClassOf, foaf:Person]
– instance typing link
t:[dbr:Wolfgang_Amadeus_Mozart, rdf:type, foaf:Person]
– property link
t:[dbr:Wolfgang_Amadeus_Mozart, foaf:name, "Wolfgang
Amadeus Mozart"@en]
– instance role link
t:[dbr:Wolfgang_Amadeus_Mozart, foaf:knows, wd:Q51088]
(Antonio Salieri)
• Instance link
t:[dbr:Wolfgang_Amadeus_Mozart, owl:sameAs, wd:Q254]](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-19-2048.jpg)



![Conclusions
• Stronger focus on the KG contributors and end user needed
– Tools/methods needed for creating/maintaining KGs
– Tools/methods needed to support querying/analysing KG Schemas
• KGs need to be stronger interlinked, e.g., link prediction
techniques need to be deployed between KGs rather than just
on a single KG
• Improved NLP/NER-based learning techniques needed (distant
supervision) that build s-p-o relations from unstructured text [Mintz et
al., 2009]
• Permanent Distributed querying/replication of data/schema](https://image.slidesharecdn.com/knowledgegraphsontheweb-v0-211214044415/75/Knowledge-graphs-on-the-Web-23-2048.jpg)





















































![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)