




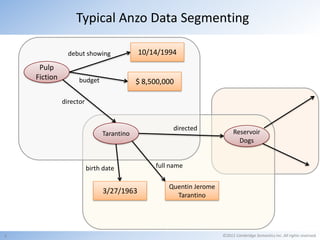






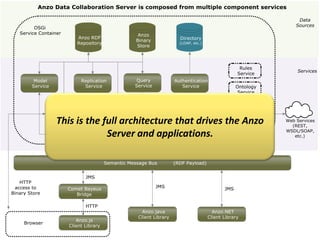
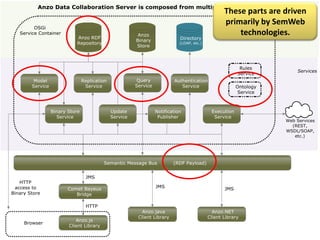
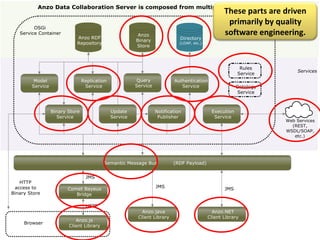



Cambridge Semantics, founded in 2007, develops the Anzo platform, a semantic web middleware primarily for Fortune 500 companies, utilizing named graphs for data segmenting. The document discusses the benefits and challenges of managing large amounts of data through named graphs, including metadata overhead and the accessibility of graphs via SPARQL queries. It also highlights the capability of Anzo to expose data as linked data and the need for industry standards related to linked data sources and SPARQL endpoints.


























































































