**"Machine Learning Life Cycle - Training, Testing, Cross Validation"**:
---
**Drift Description:**
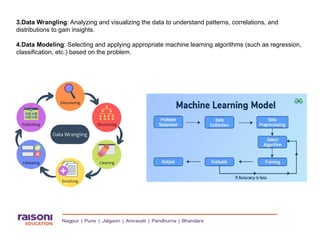
The Machine Learning life cycle outlines the stages through which an ML project passes, from data collection to model deployment. A key part involves splitting data into **training**, **testing**, and using **cross-validation** to evaluate model performance.
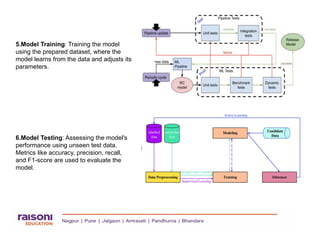
- **Training**: The model learns patterns from the training dataset.
- **Testing**: The trained model is evaluated on unseen test data to measure accuracy and generalization.
- **Cross Validation**: The data is split into multiple parts to train and test repeatedly, ensuring a more reliable model evaluation.
This life cycle ensures the model is accurate, efficient, and ready for real-world use.
---
Would you also like a quick **slide-by-slide suggestion** for your PowerPoint? 🚀
(Example: Title Slide, What is ML Life Cycle?, Training Phase, Testing Phase, Cross Validation, Summary)