Downloaded 78 times




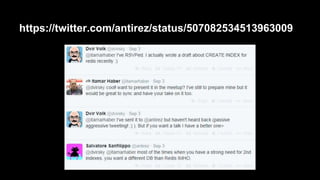


















![[This Slide has No Title]
NULL means no value and Redis is all about
values.
When needed, arbitrarily decide on a value for
NULLs (e.g. "<null>") and handle it
appropriately in code.](https://image.slidesharecdn.com/20140922redistlv-redisindices-140922123815-phpapp01/85/Redis-Indices-RedisTLV-25-320.jpg)







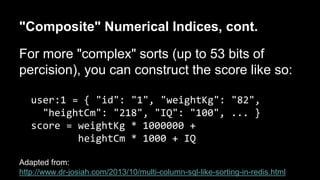










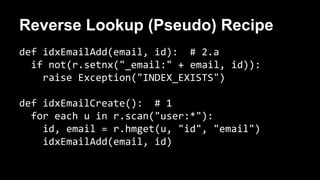
The document discusses the concept of creating indices in Redis to improve data retrieval efficiency, particularly focusing on the implementation of a reverse lookup index based on unique values like email addresses. It explains various indexing strategies, such as using lists, hashes, or sets for handling non-unique values, and covers performance considerations and memory optimization. Additionally, it touches on the complexities of index consistency and atomicity in the context of Redis's non-relational architecture.



























































































