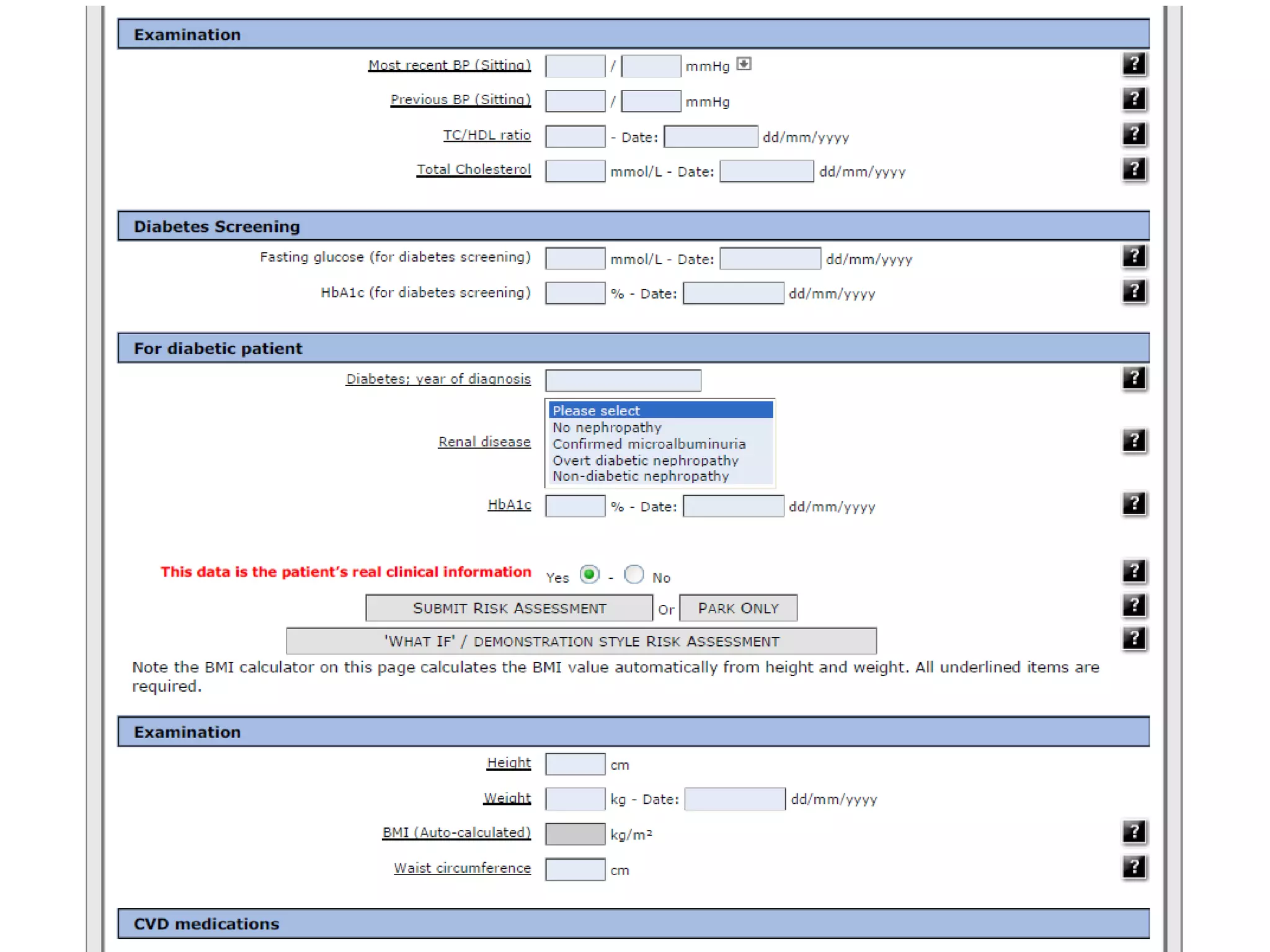
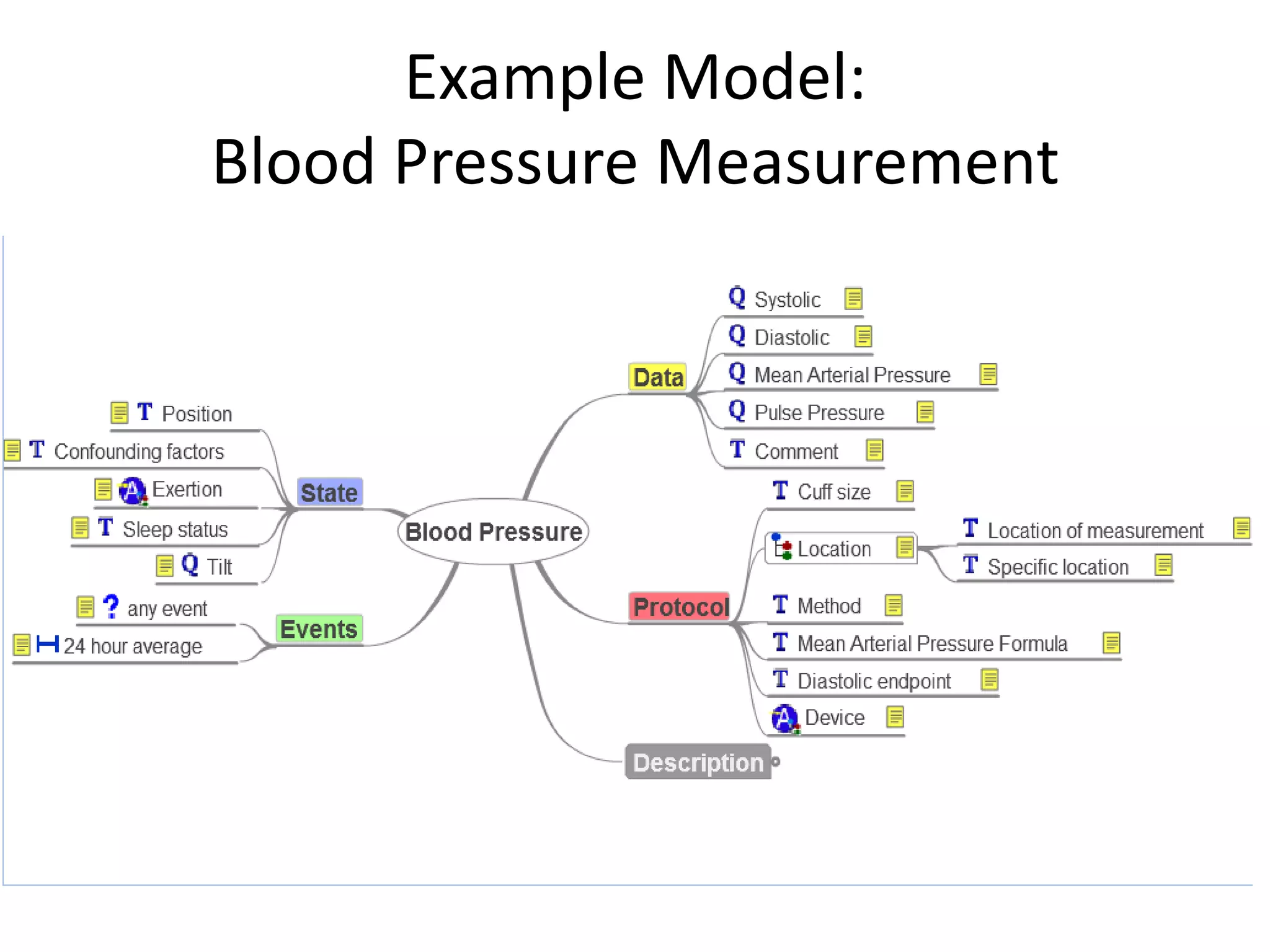
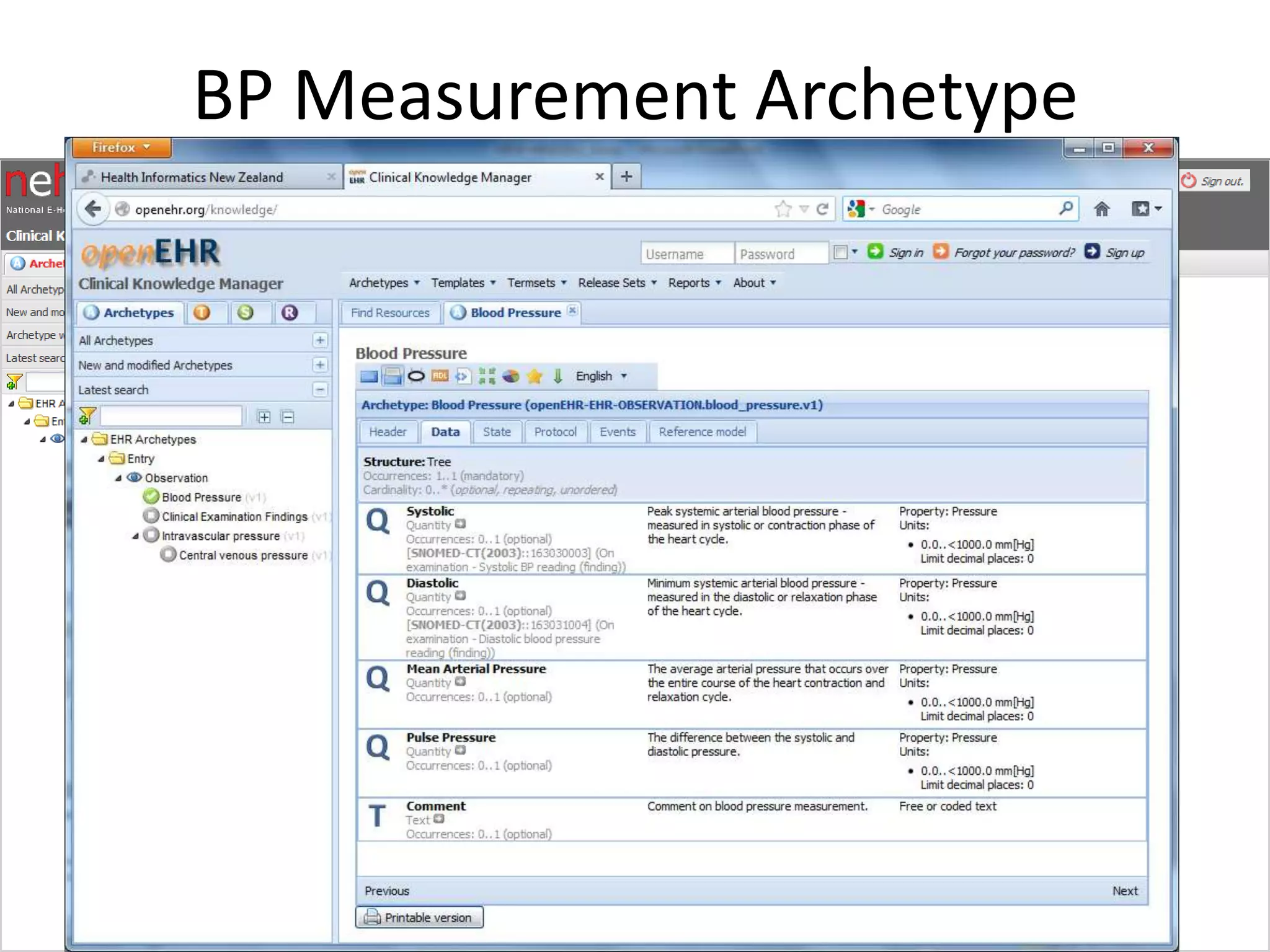
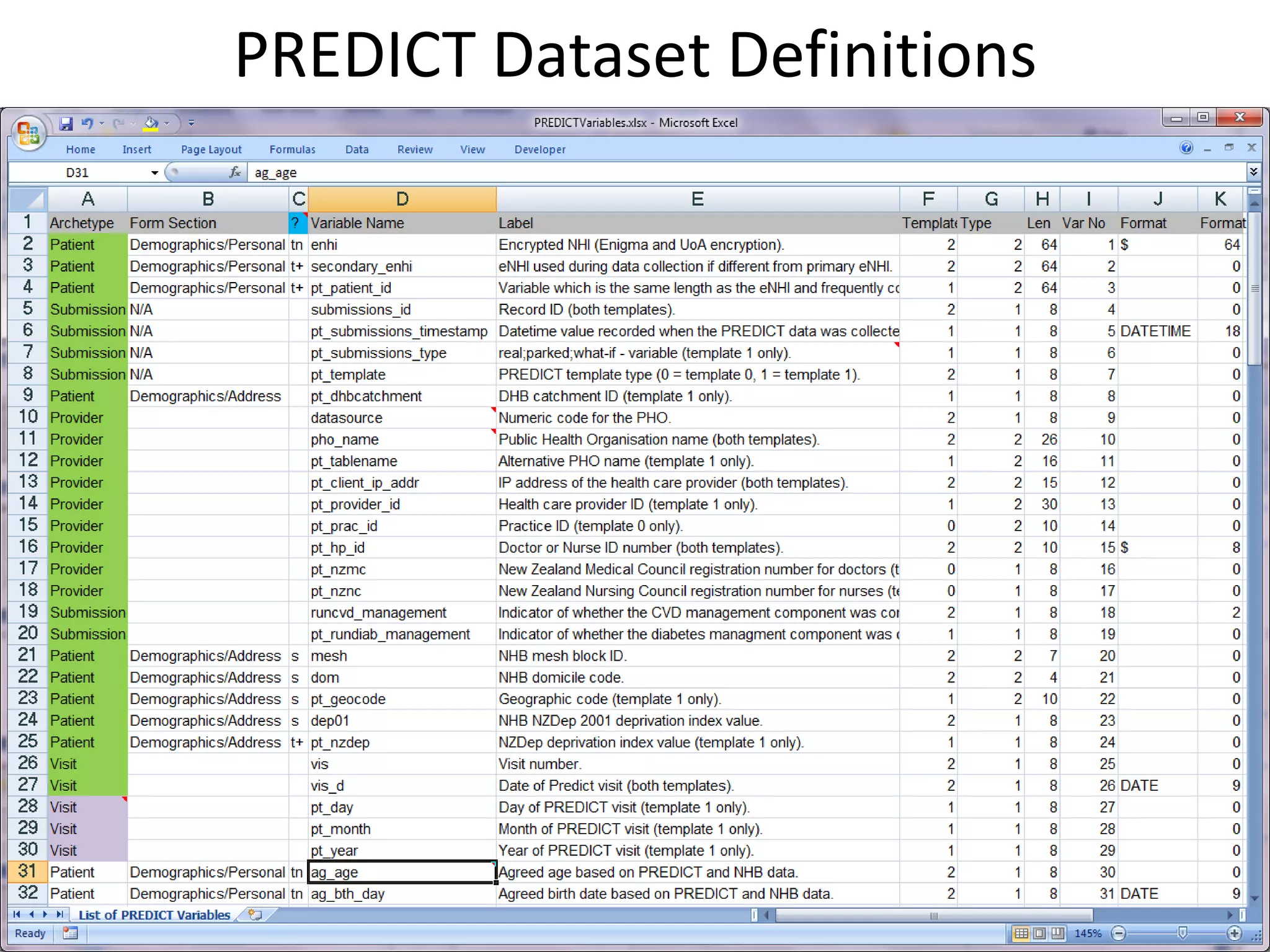
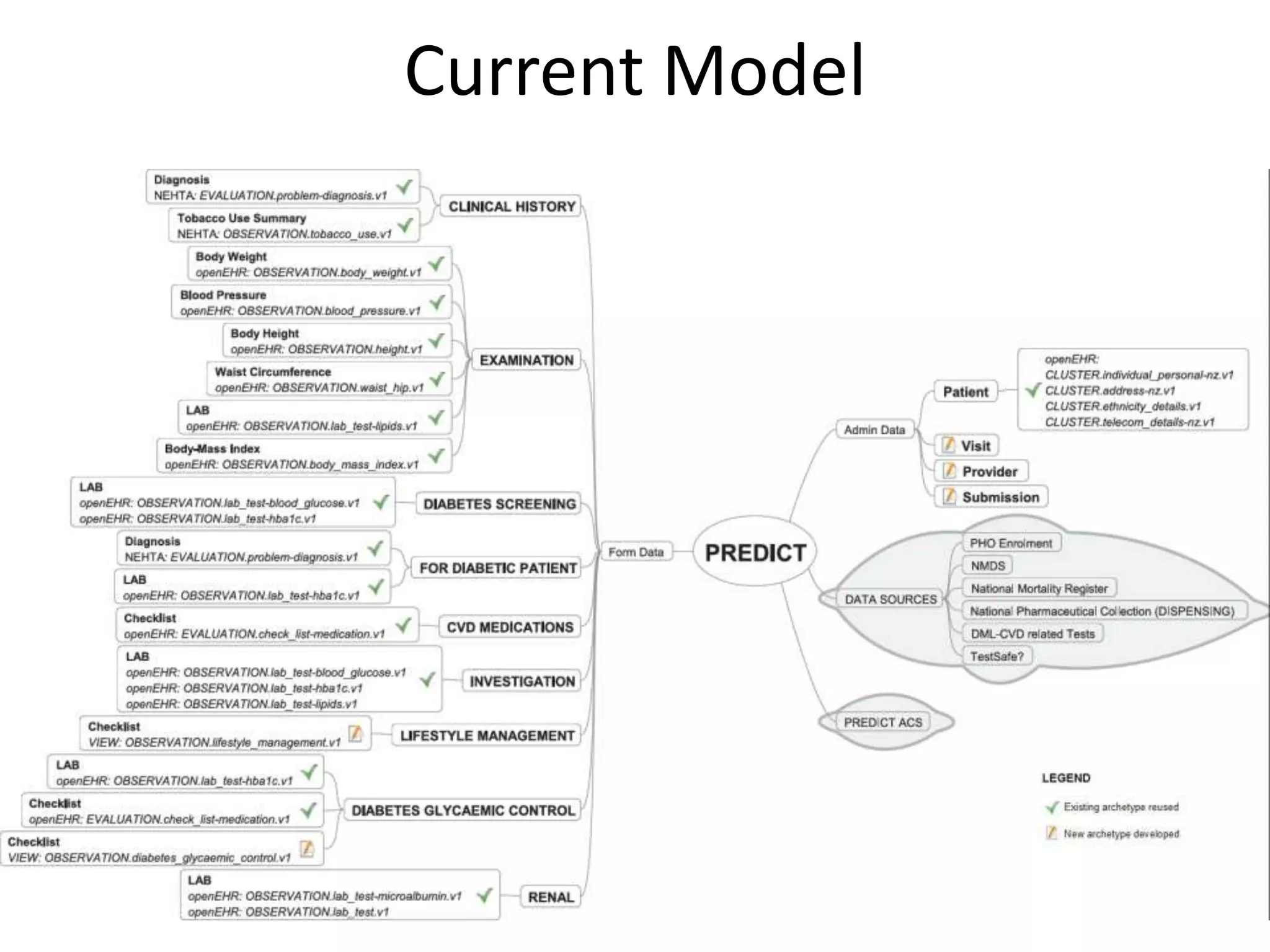
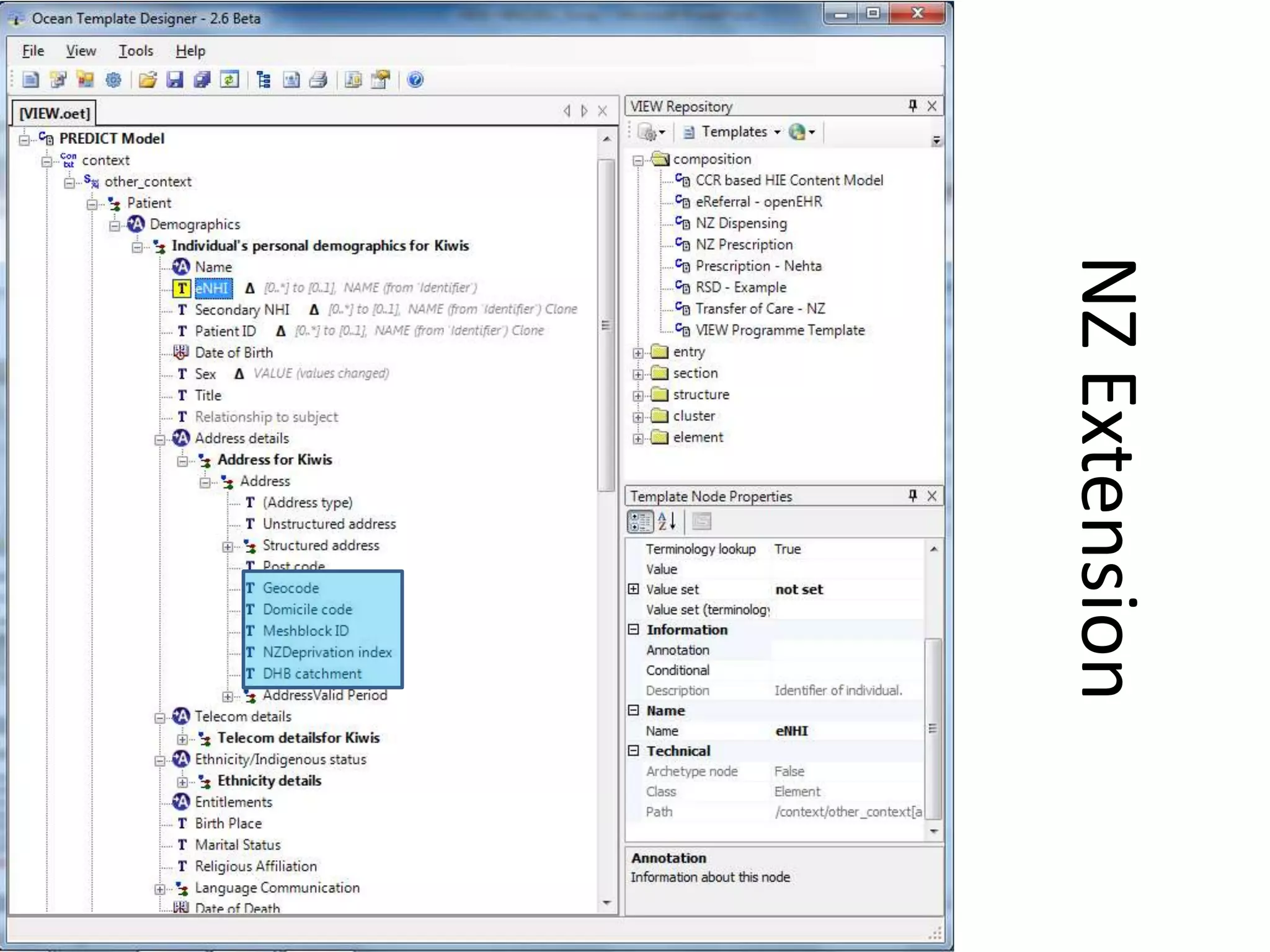
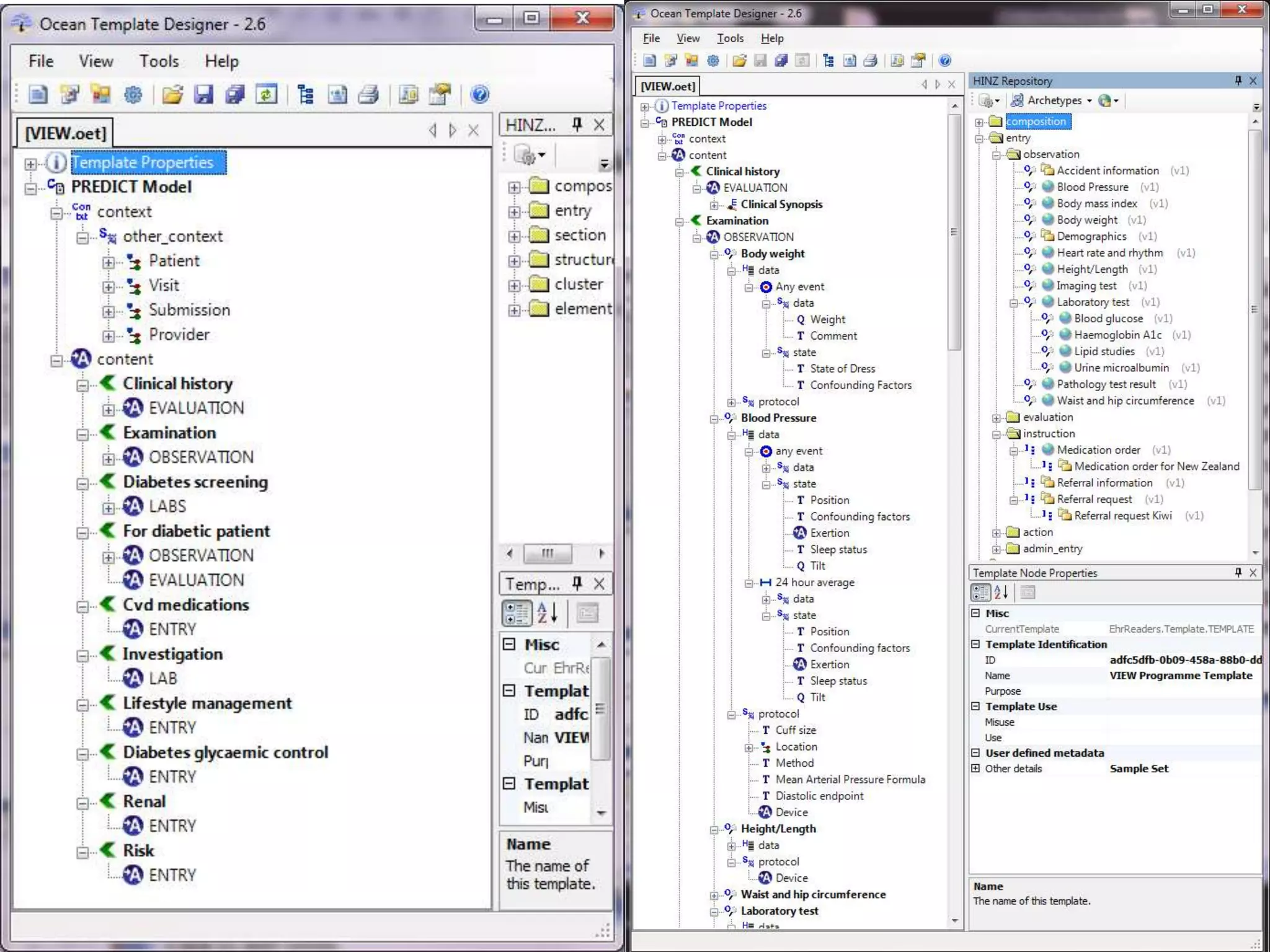
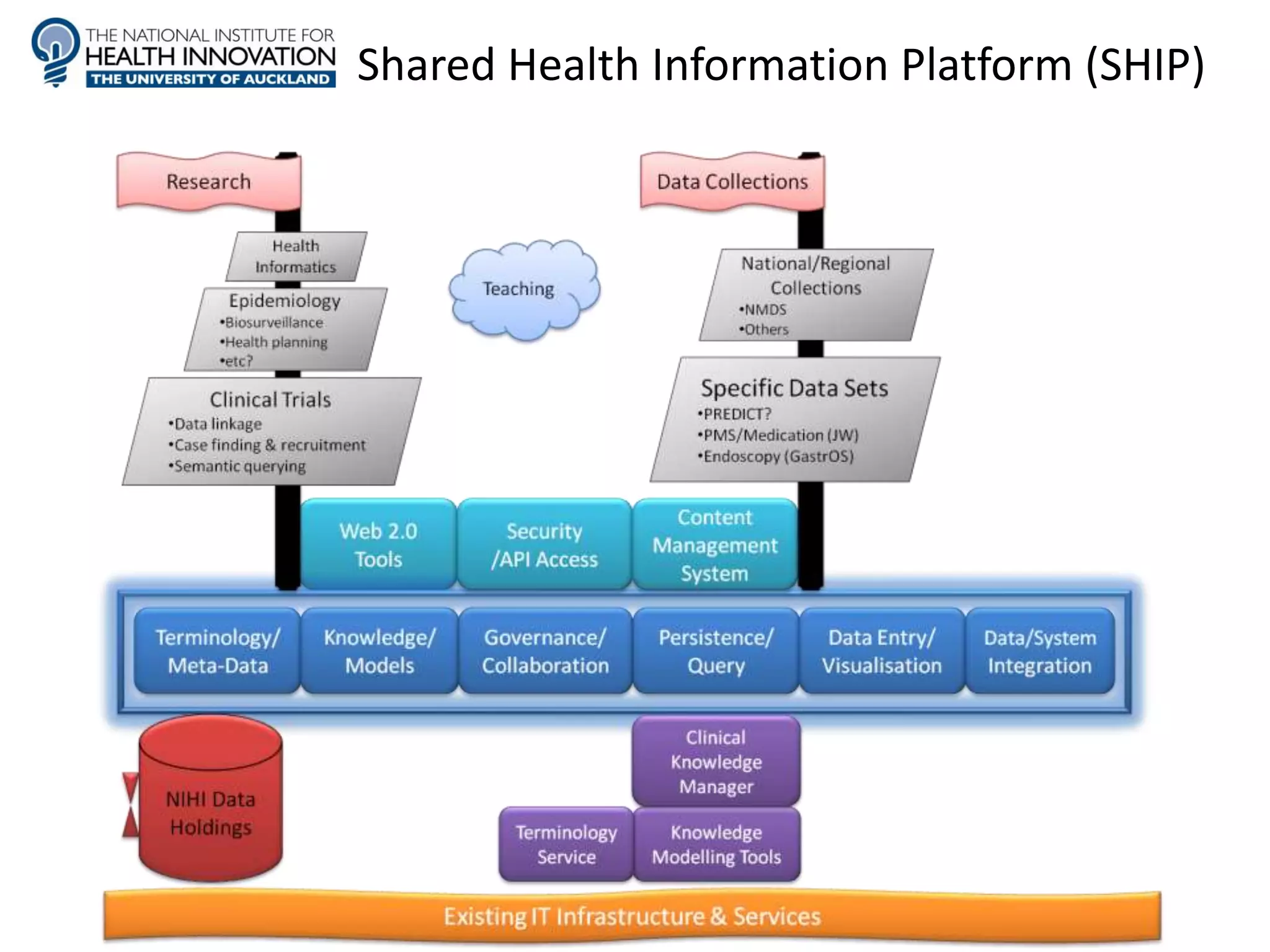
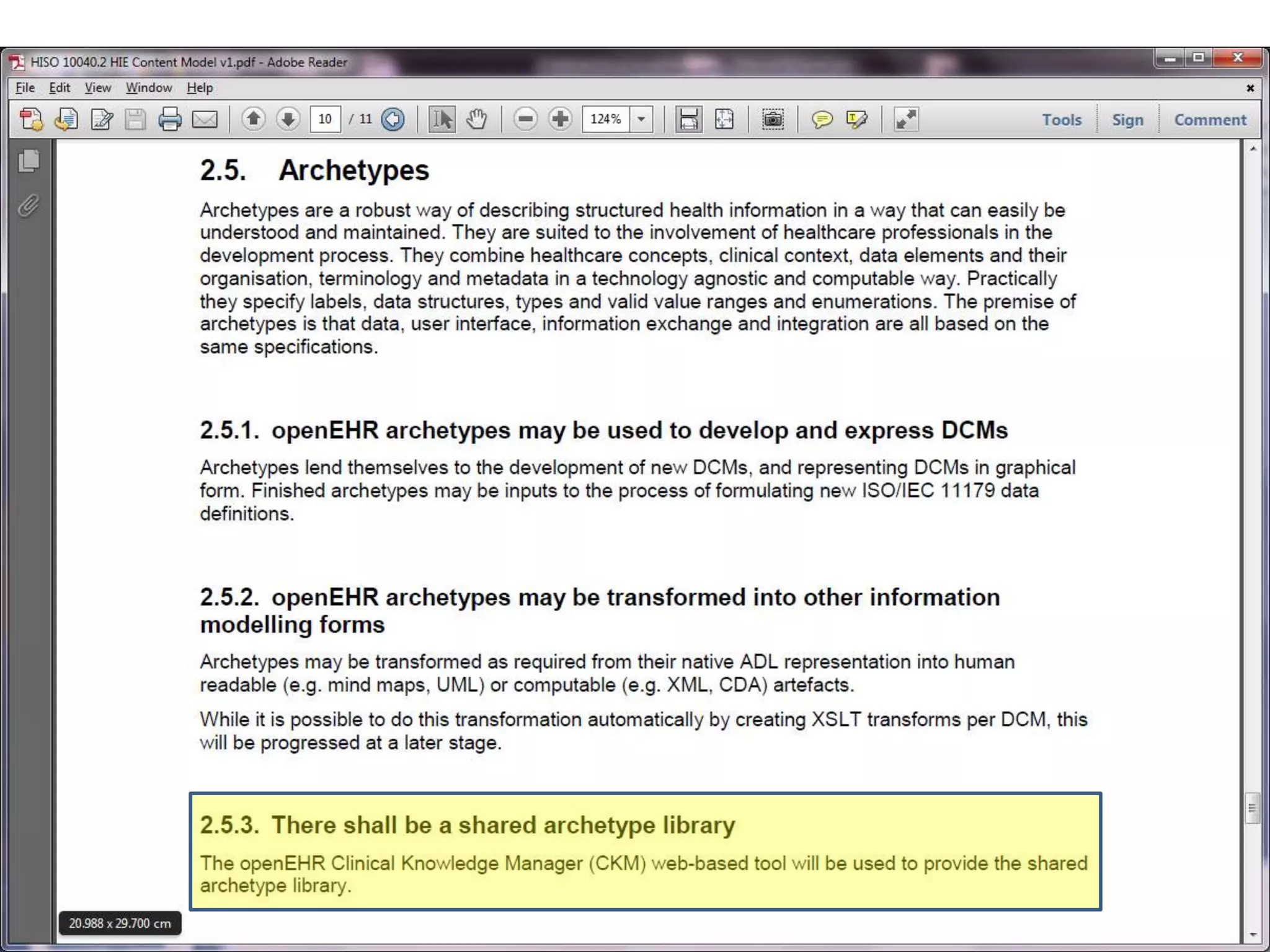
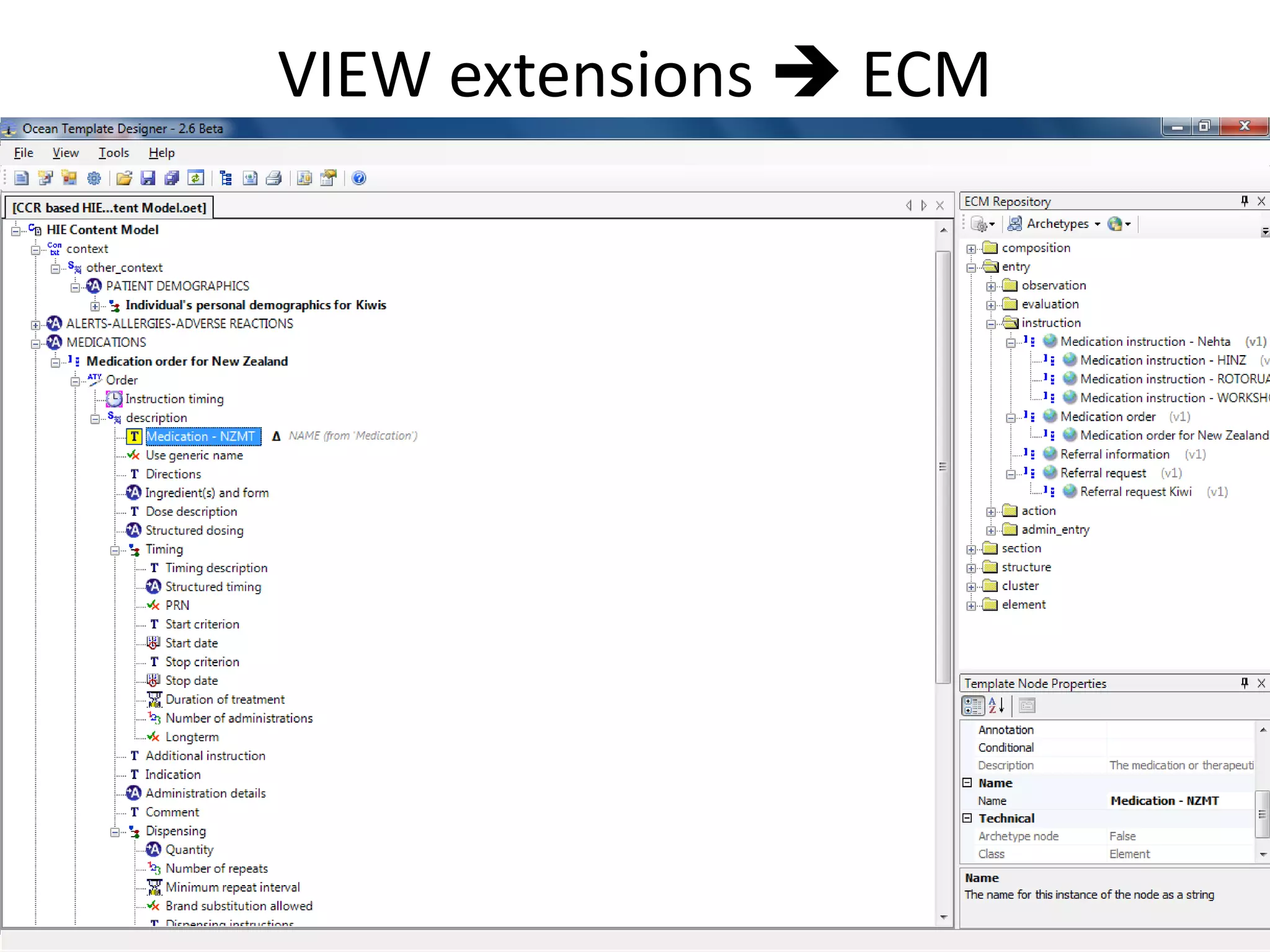
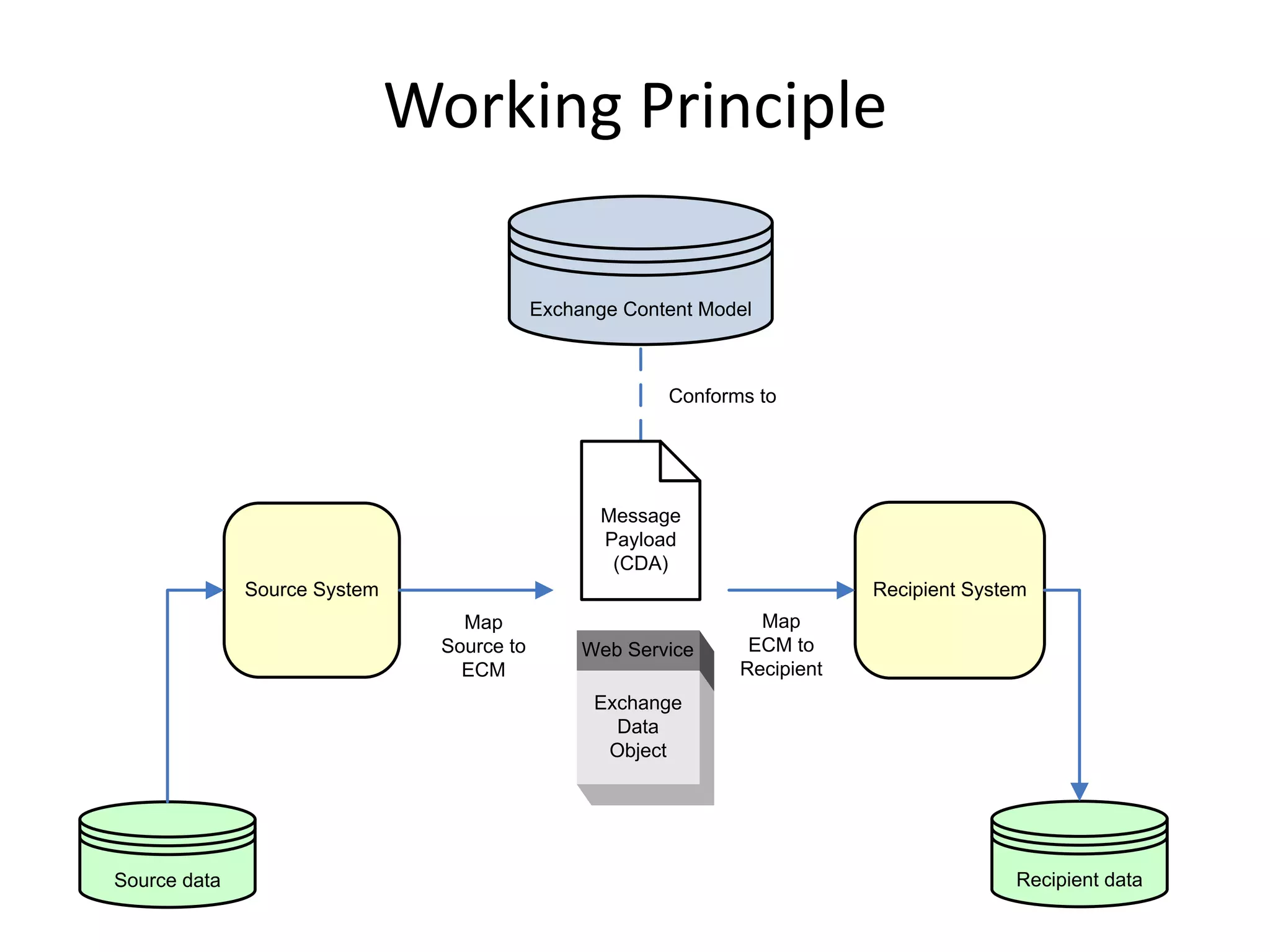
The document discusses the development of a content model for view datasets utilizing archetypes, aiming to enhance risk prediction models and create a variation atlas of cardiovascular diseases in New Zealand. It outlines objectives such as defining a canonical information model and establishing a research data repository that integrates existing datasets while ensuring backward compatibility. The content model, based on archetypes, facilitates interoperability, real-time data access, and efficient research data sharing, addressing challenges related to data silos and loss of clinical context.