Download as PDF, PPTX


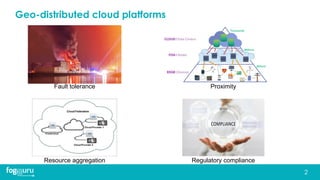

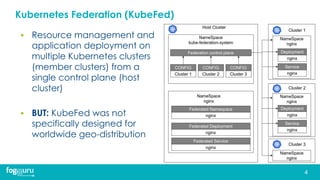

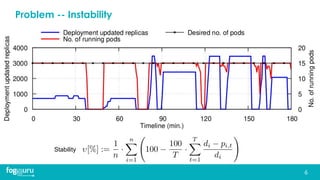
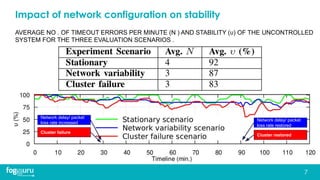
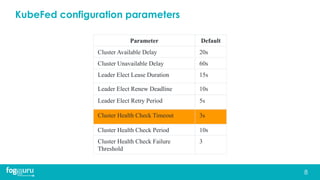
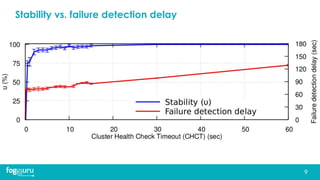
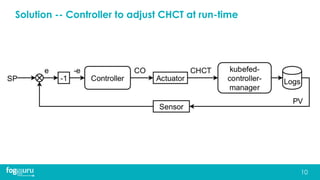
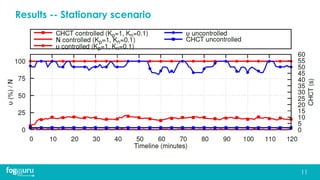
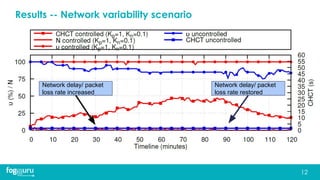
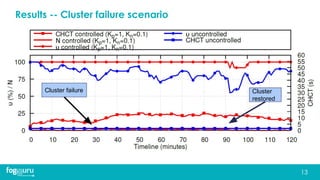

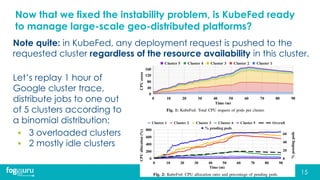

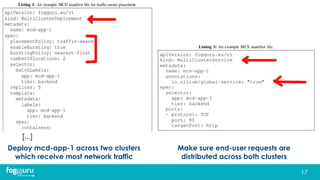





This document discusses research on improving the stability and resource management of geo-distributed Kubernetes federations. The researchers found that Kubernetes Federation (KubeFed) implementations exhibited instability due to poor network conditions and static configuration parameters. They developed a proportional controller to dynamically adjust health check timeouts and improve stability. They then addressed resource availability and network traffic awareness by developing mck8s, a platform that can deploy applications across clusters based on resource load and network traffic. Mck8s also allows bursting to public clouds when local clusters are overloaded and retracting those resources when possible. This improves resource management for geo-distributed multi-cluster Kubernetes environments.























































































