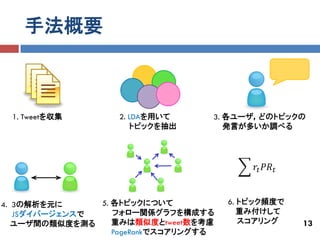
今回紹介した論文
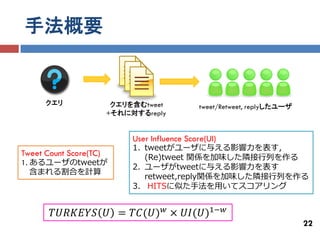
ある話題について影響力の高いユーザを推薦
Tomoya Noro, Fei Ru, Feng Xiao, Takehiro Tokuda
Twitter User Rank Using Keyword Search. 22nd
European Japanese Conference on Information
Modelling and Knowledge Bases, pp.48-65. 2012 Jun
実際の友達を推定して推薦(+ユーザの位置推定)
Sadilek, A.: Kautz, H.; and Bigham, J. P. 2012.
Finding your friends and following them to where
you are. In Proc. of the fifth ACM int’l conference on
Web search and data mining.
slide : http://www.slideshare.net/nokuno/finding-your-
friends-and-following-them-to-where-you-are-
wsdm2012
39






![Twitterとは
Twitter
SNSの一種
リアルタイムで情報の収集・発信・共有・コミュニケー
ションを行うマイクロブログサービス
特徴
1 tweetは140字以内
登録ユーザ数は5億人以上 (2012年7月) [2]
1日のtweet数は3億4000万以上 (2012年3月) [1]
情報インフラとしての役割
[1] http://jp.techcrunch.com/archives/20120321six-year-old-twitter-now-has-140m-active-users-sending-340m-tweets-per-day/
[2] http://jp.techcrunch.com/archives/20120730analyst-twitter-passed-500m-users-in-june-2012-140m-of-them-in-us- 5
jakarta-biggest-tweeting-city/](https://image.slidesharecdn.com/tokyowebmining-121026081253-phpapp01/85/Twitter-User-Recommendation-5-320.jpg)


























![手法の参考文献
LDA
[Blei+2003] Latent Dirichlet allocation, JMLR
latent Dirichlet allocation - 機械学習の「朱鷺の杜Wiki」
LDA入門
JSダイバージェンス
Jensen-Shannonダイバージェンス - 機械学習の「朱鷺の杜
Wiki」
PageRank, HITS
Google PageRankの数理 ―最強検索エンジンのランキング
手法を求めて―
Googleページランクの数理1【アイマス教養講座】 40](https://image.slidesharecdn.com/tokyowebmining-121026081253-phpapp01/85/Twitter-User-Recommendation-40-320.jpg)



![[WWW Conference 2011]Information Credibility on Twitter](https://cdn.slidesharecdn.com/ss_thumbnails/2011-www-informationcredibilityontwitter-110511095843-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























