Downloaded 14 times







![Notations
• Type of objects
– Let N be the number of objects in the dataset. (i.e.
users, documents, words, etc.)
• Ti is an object. i 1…N
• For simplify, object Ti has ni instances.
– Relation matrices
• Let M be the number of relations between objects.
ni nj is the relation matrix between objects T and T .
• Rij
i
j
– Similarity matrices
ni ni is the square and symmetrical
• Similarity matrix Si
matrix of Ti, where the values must be in [0,1].
7](https://image.slidesharecdn.com/co-clusteringofmulti-viewdatasets-131229073400-phpapp02/85/Co-clustering-of-multi-view-datasets-a-parallelizable-approach-7-320.jpg)
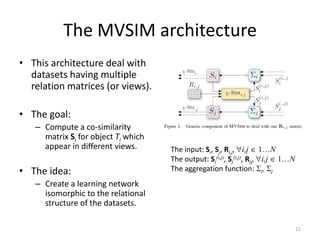
![The -SIM algorithm [SDM’10]
• Let R12 is a [documents/words] matrix and that
the task is to compute the similarity matrix S1
(documents) and S2 (words).
• The idea of -SIM is to capture the duality
between documents and words.
• This is achieved by simultaneously calculating
document-document similarities based on words,
and word-word similarities based on documents.
8](https://image.slidesharecdn.com/co-clusteringofmulti-viewdatasets-131229073400-phpapp02/85/Co-clustering-of-multi-view-datasets-a-parallelizable-approach-8-320.jpg)


![Aggregation Function
• Functions
i
have two important roles:
– Aggregate the multiple similarity matrices
produced by -SIM.
• F(Si(i,1), Si(i,2),..): merging function combining matrices.
– Ensure the convergence
• Use damping factor
[0,1] to balance the function
i
12](https://image.slidesharecdn.com/co-clusteringofmulti-viewdatasets-131229073400-phpapp02/85/Co-clustering-of-multi-view-datasets-a-parallelizable-approach-12-320.jpg)



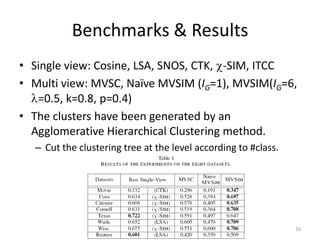

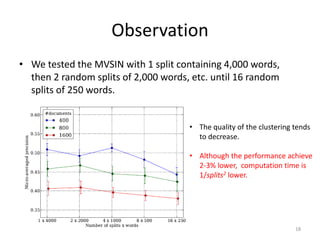
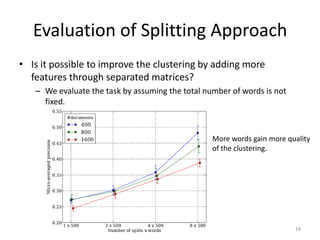


This document summarizes a research paper on co-clustering multi-view datasets using a parallelizable approach called MVSIM. MVSIM computes co-similarity matrices for related objects across multiple views or relation matrices. It creates a learning network matching the relational structure and aggregates the similarity matrices using a damping factor. Experiments show MVSIM outperforms single-view and other multi-view clustering methods on document and newsgroup datasets, and its performance decreases slightly but computation time reduces significantly when the data is split across more views.


















![[NeurIPS2020 (spotlight)] Generalization bound of globally optimal non convex...](https://cdn.slidesharecdn.com/ss_thumbnails/neurips2020spotlight-210331133014-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ICLR2021 (spotlight)] Benefit of deep learning with non-convex noisy gradien...](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2021-210331133549-thumbnail.jpg?width=640&height=640&fit=bounds)

























































