Download to read offline



![Existing Clustering Methods
4
Enc Dec
Clustering the latent code
Autoencoder-based methods (e.g., DCN, VaDE, DGG)
DCN [1]
Closer in the latent space of the AE
The latent should only capture semantic information from the input
[1] Towards k-means-friendly spaces: Simultaneous deep learning and clustering, Yang et al., ICML 2017](https://image.slidesharecdn.com/clusteringbymaximizingmutualinformationacrossviews-211204093431/75/Clustering-by-Maximizing-Mutual-Information-Across-Views-4-2048.jpg)
![Existing Clustering Methods (cont.)
5
IIC [1]
Methods that only use the cluster-assignment probability (e.g., IIC, PICA)
Problem: May not capture enough useful
information from data => over-clustering is
often required.
[1] Invariant Information Clustering for Unsupervised Image Classification and Segmentation, Ji et al., ICCV 2019](https://image.slidesharecdn.com/clusteringbymaximizingmutualinformationacrossviews-211204093431/75/Clustering-by-Maximizing-Mutual-Information-Across-Views-5-2048.jpg)


![The InfoNCE bound
• InfoNCE [1] is a lower bound of MI
• It is biased but has low variance
• Maximizing InfoNCE is equivalent to minimizing a contrastive loss:
8
[1] On Variational Bounds of Mutual Information, Poole et al., ICML 2019
is a “critic” measuring the similarity between and](https://image.slidesharecdn.com/clusteringbymaximizingmutualinformationacrossviews-211204093431/75/Clustering-by-Maximizing-Mutual-Information-Across-Views-8-2048.jpg)
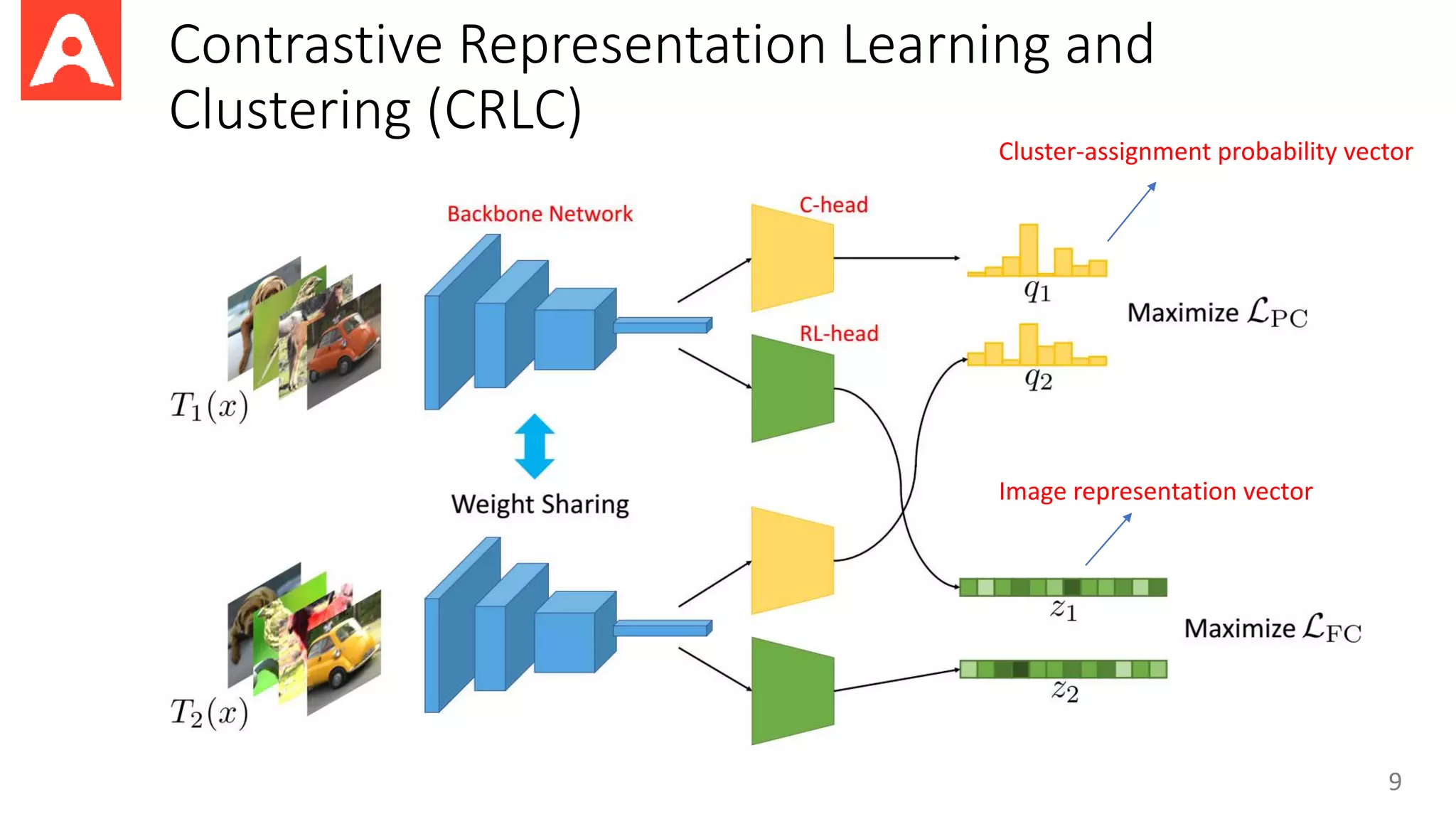



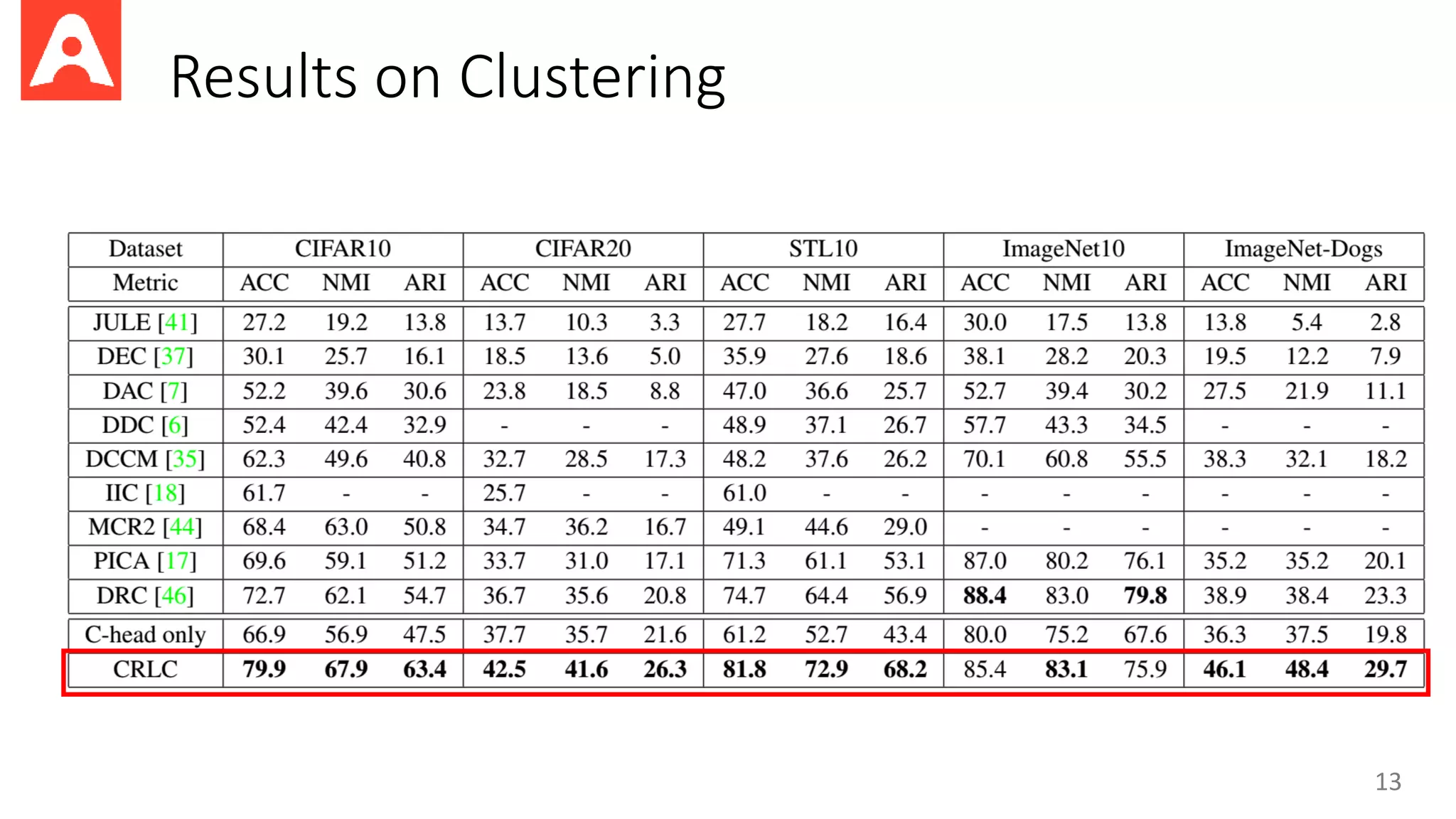
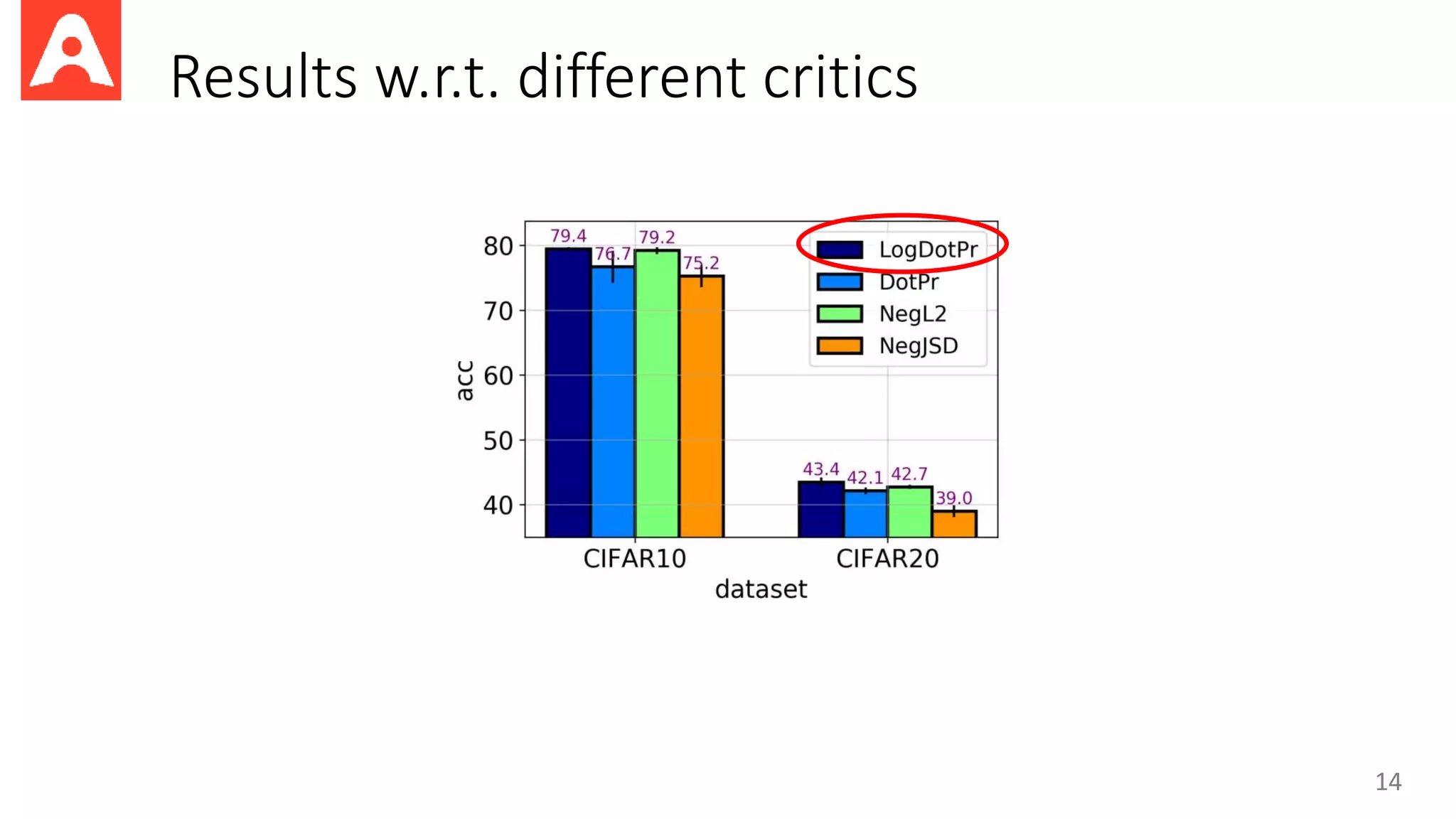
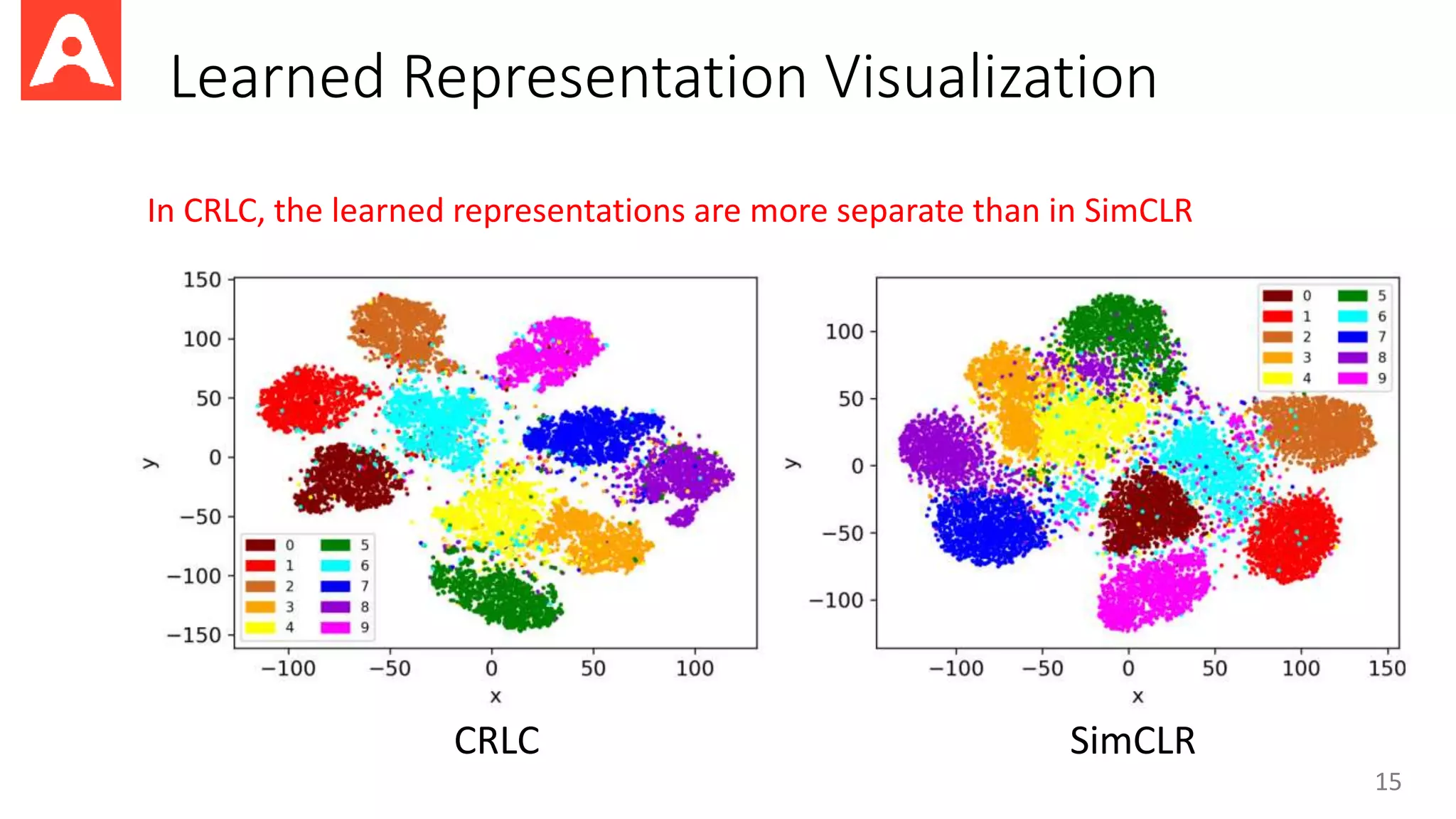
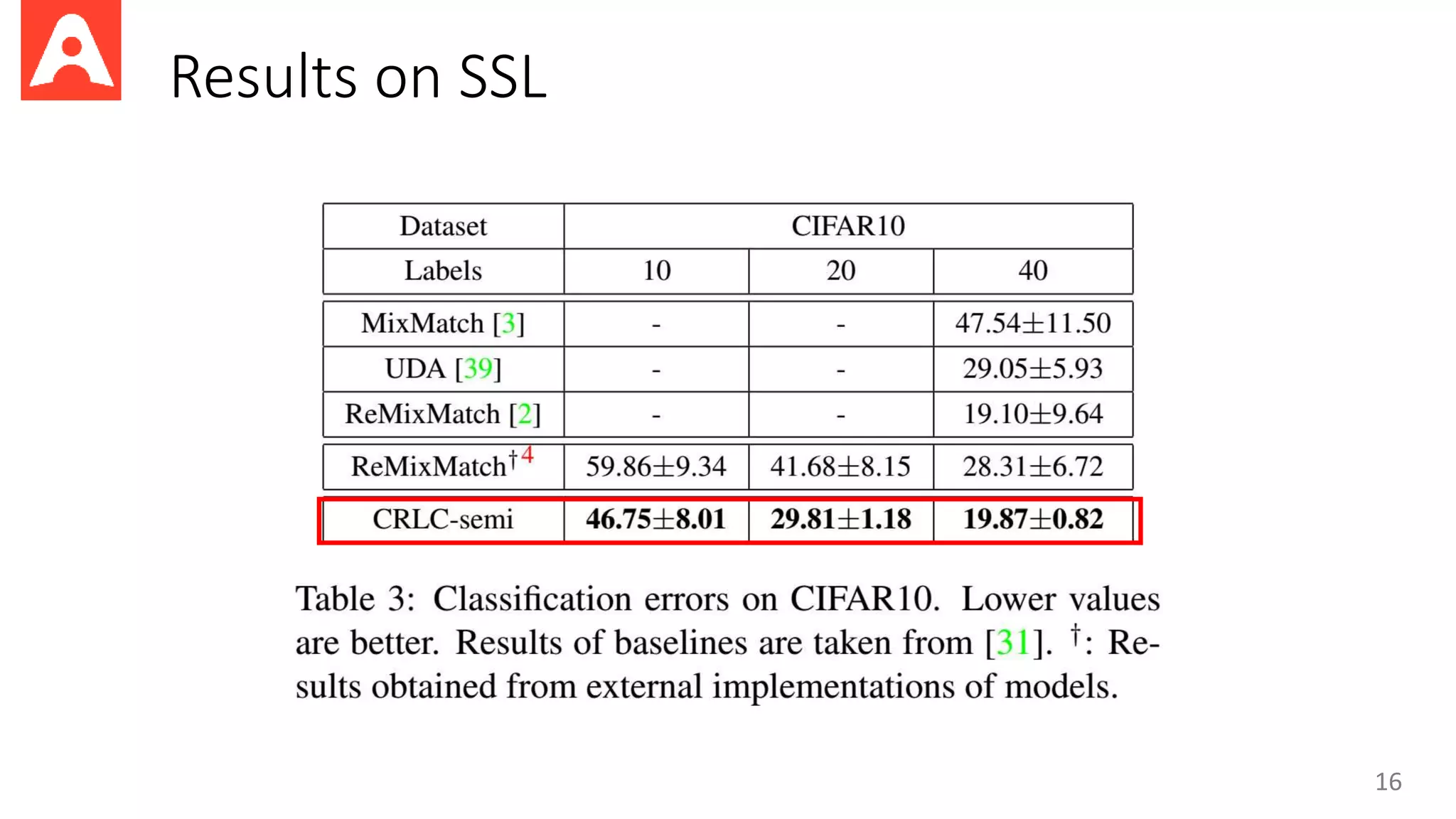
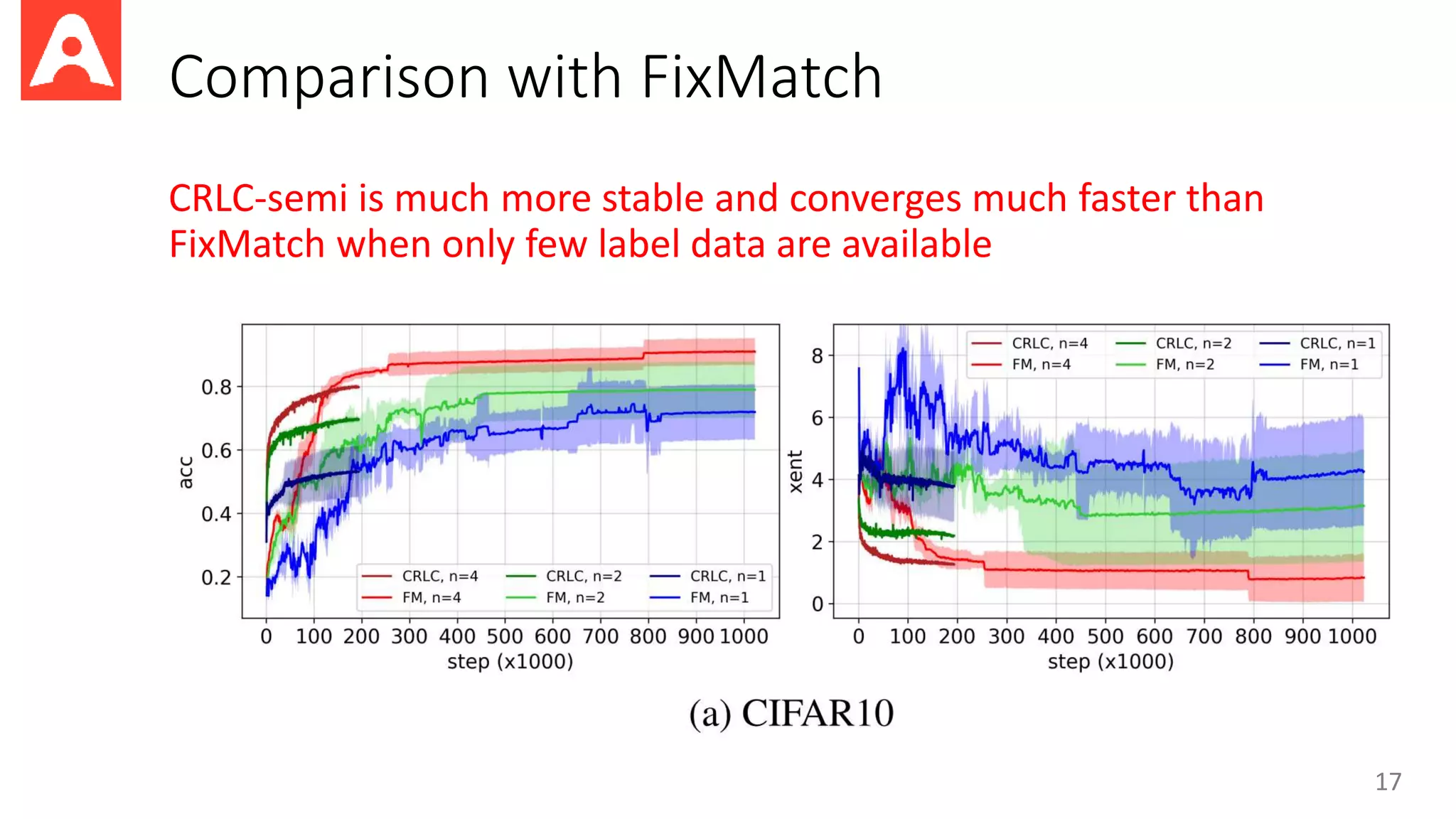


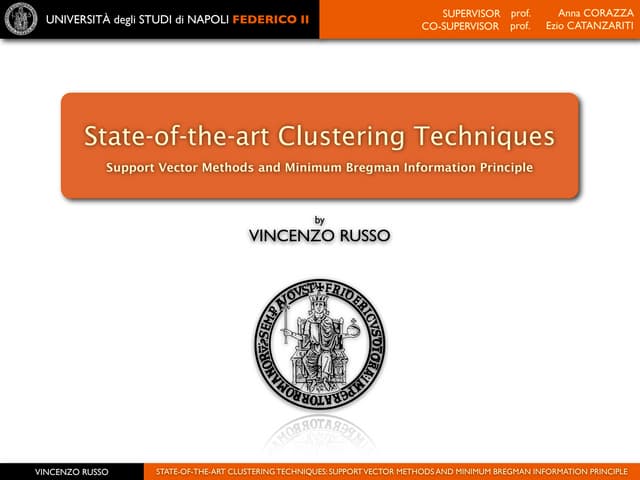
This document proposes a new method called Contrastive Representation Learning for Clustering (CRLC) that applies the principle of maximizing mutual information across views to learn cluster-level and instance-level semantics for unsupervised image clustering. CRLC trains an encoder to map images to a representation space by maximizing the agreement between the image representation and a cluster-assignment probability vector, using either cosine similarity or log-of-dot-product as the critic. This training loss functions to minimize a contrastive loss and learn discriminative representations. Experimental results show CRLC learns more separated representations than baselines and achieves better clustering and semi-supervised learning performance.