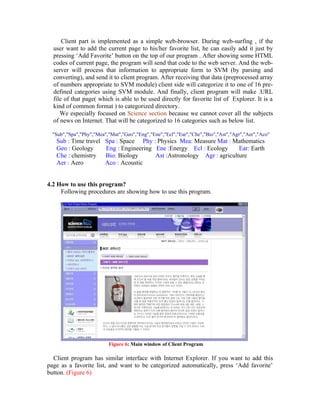
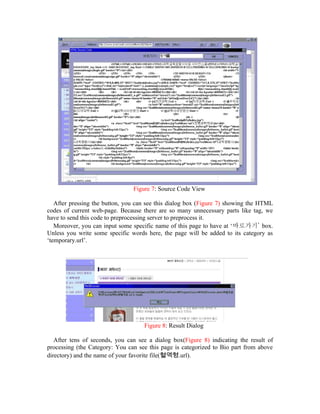
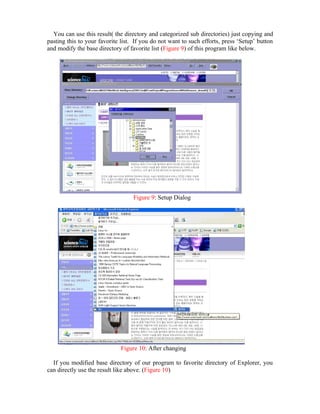
This document describes a web page categorization application that uses support vector machines (SVM) for text categorization. The application extracts text from web pages, parses it to extract noun terms, creates document vectors, and trains an SVM classifier on labeled training data to categorize new pages. The system was implemented with a client-server structure where the client is a web browser that sends page text to the server for processing and categorization. The SVM classifier was trained on over 7,500 labeled pages and achieved an accuracy of over 70% on a test set. The application allows users to easily add pages to categorized favorites lists within their browser.
















































![[CLPE] Novidades do Asp.net 4](https://cdn.slidesharecdn.com/ss_thumbnails/novidadesdoasp-net4-100420113033-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














































