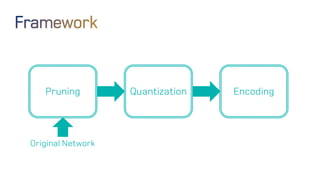
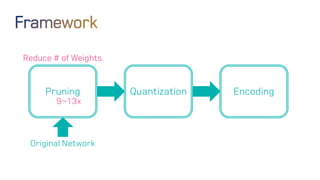
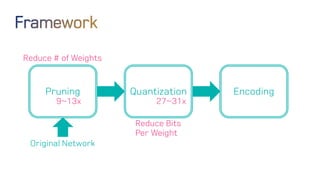
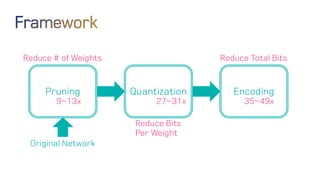
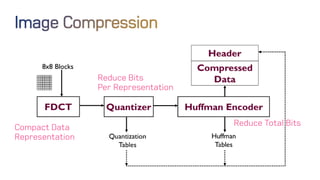
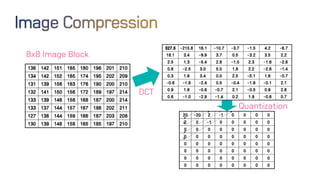
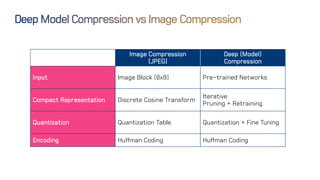
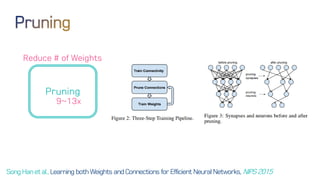
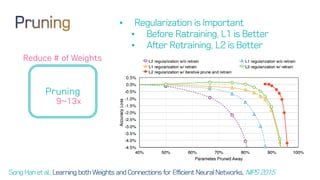
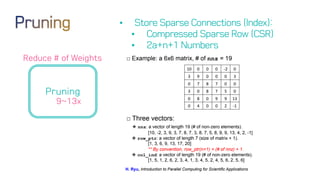
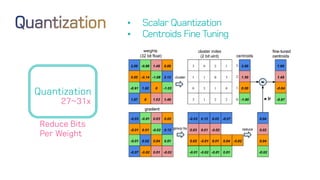
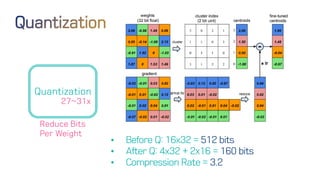
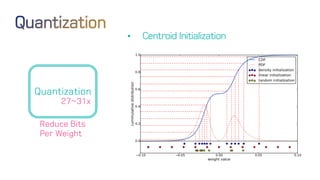
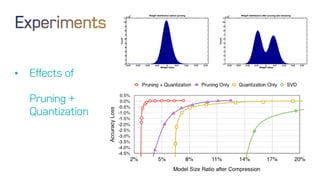
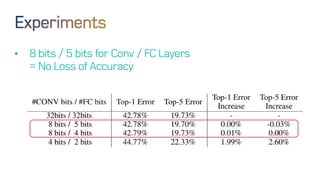
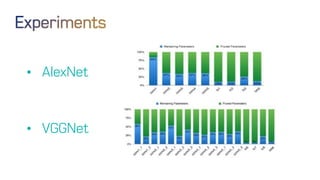
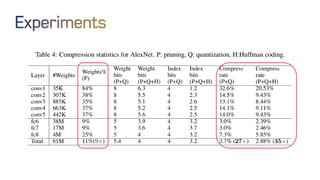
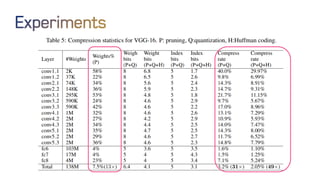
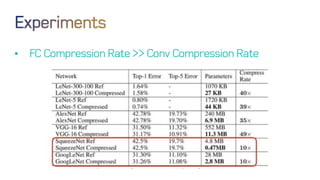
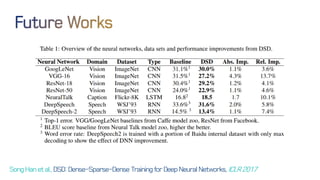
The document discusses neural network optimization techniques including pruning and quantization to reduce the number of weights and overall bits in models like AlexNet and VGG-16. It highlights research by Song Han et al. on methods like deep compression and efficient inference engines, achieving significant reductions in model size and energy consumption. The findings suggest that regularization techniques and specific quantization strategies play crucial roles in maintaining model accuracy while optimizing performance.