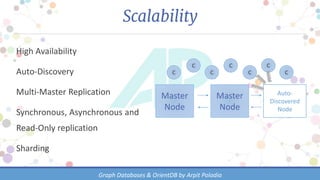
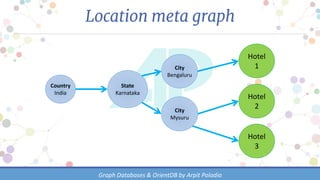
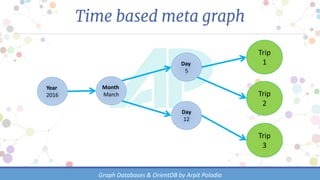
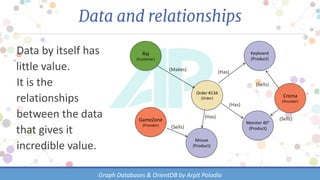
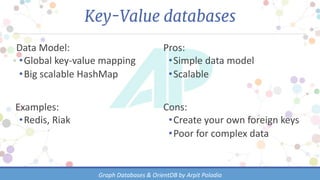
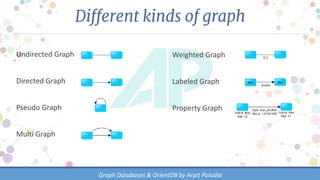
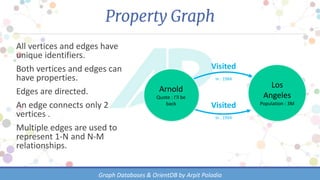
The document discusses various types of databases, focusing on graph databases and their advantages over traditional databases like key-value and document stores. It highlights the importance of relationships between data, the challenges of joins in conventional databases, and presents OrientDB as a powerful multi-model NoSQL database that efficiently manages relationships with index-free adjacency. Additionally, it emphasizes the scalability, flexibility, and ease of use of graph databases for connected data.
















![How does OrientDB manage relations?
out : [#14:1]
label : ‘Customer’
name : ‘Anderson’
RID = #13:1
RID = #14:1
RID = #13:2
in: [#14:1]
label = ‘Product’
name = ‘Red pill’
out: [#13:1]
in: [#13:2]
label : ‘Chooses’
Anderson
Chooses
Red pill
The RID is the
physical position
The RID of the edge
is stored as out
The RID of the edge
is stored as in
The RID of the vertices are
stored as out and in](https://image.slidesharecdn.com/graphdatabasesorientdb-170129184444/85/Graph-Databases-OrientDB-20-320.jpg)

![Schema hybrid
Schema-less mode : Schema is not mandatory.
• Relaxed model, collect heterogeneous documents all together.
Schema-full mode: Schema with constraints on fields and validation rules.
• Customer.age > 17
• Customer.address not null
• Customer.surname is mandatory
• Customer.email matches 'b[A-Z0-9._%+-]+@[A-Z0-9.-]+.[A-Z]{2,4}b'
Schema-mixed mode:
• Schema with mandatory and optional fields + constraints.](https://image.slidesharecdn.com/graphdatabasesorientdb-170129184444/85/Graph-Databases-OrientDB-22-320.jpg)