Downloaded 12 times












![the Python Requests library
import requests
import json
worldbank_url =
"http://api.worldbank.org/countries/all/indicators/SP.RUR.TOTL.ZS?date=2000:20
15&format=json"
r = requests.get(worldbank_url)
jsondata = json.loads(r.text)
print(jsondata[1])](https://image.slidesharecdn.com/session03acquiringdata-160510160212/75/Session-03-acquiring-data-19-2048.jpg)



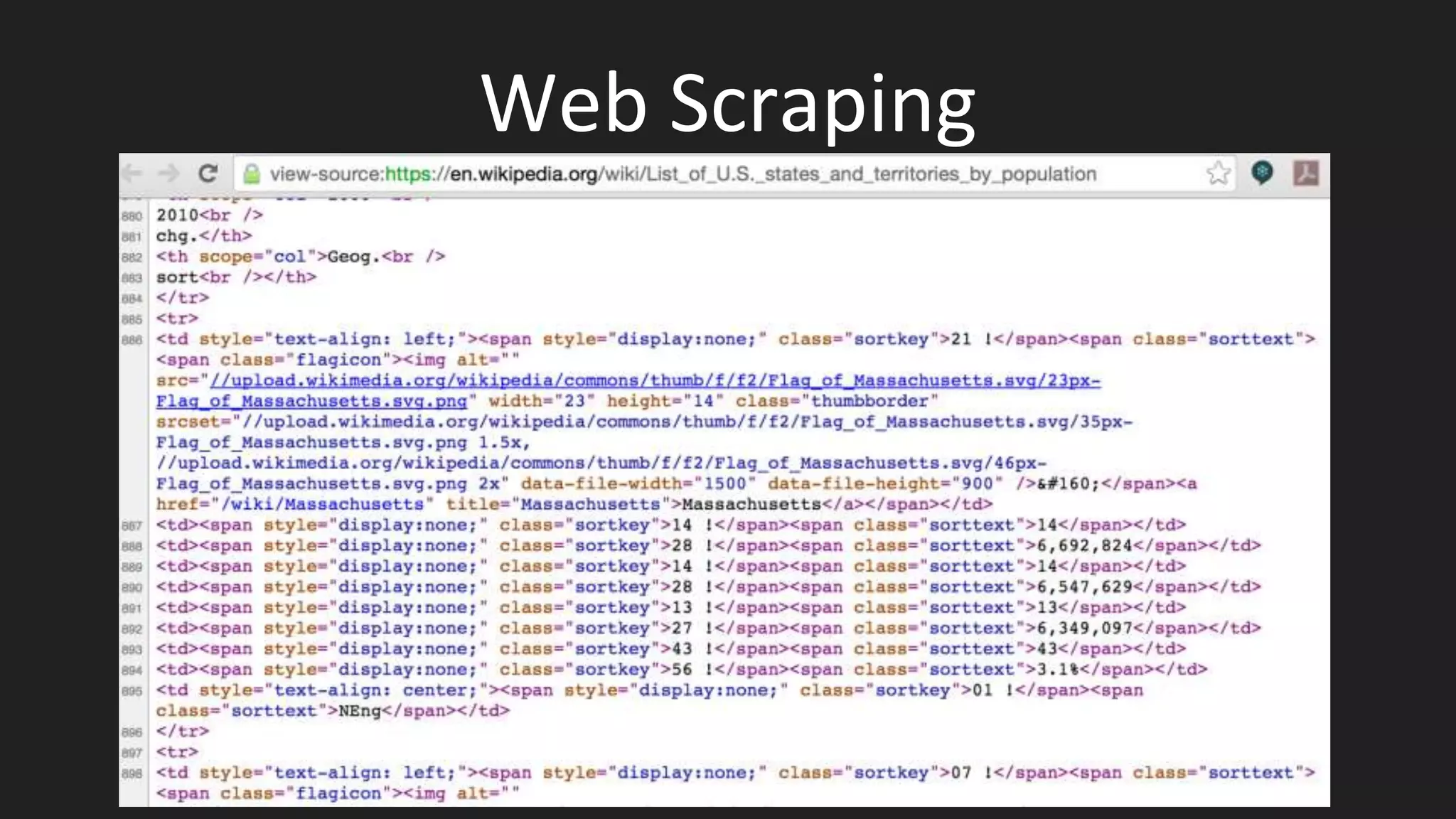



![Unpicking HTML with Python
url =
"https://en.wikipedia.org/wiki/List_of_U.S._states_and_territories_by_population”
import requests
from bs4 import BeautifulSoup
html = requests.get(url)
bsObj = BeautifulSoup(html.text)
tables = bsObj.find_all('table’)
tables[0].find("th")](https://image.slidesharecdn.com/session03acquiringdata-160510160212/75/Session-03-acquiring-data-32-2048.jpg)


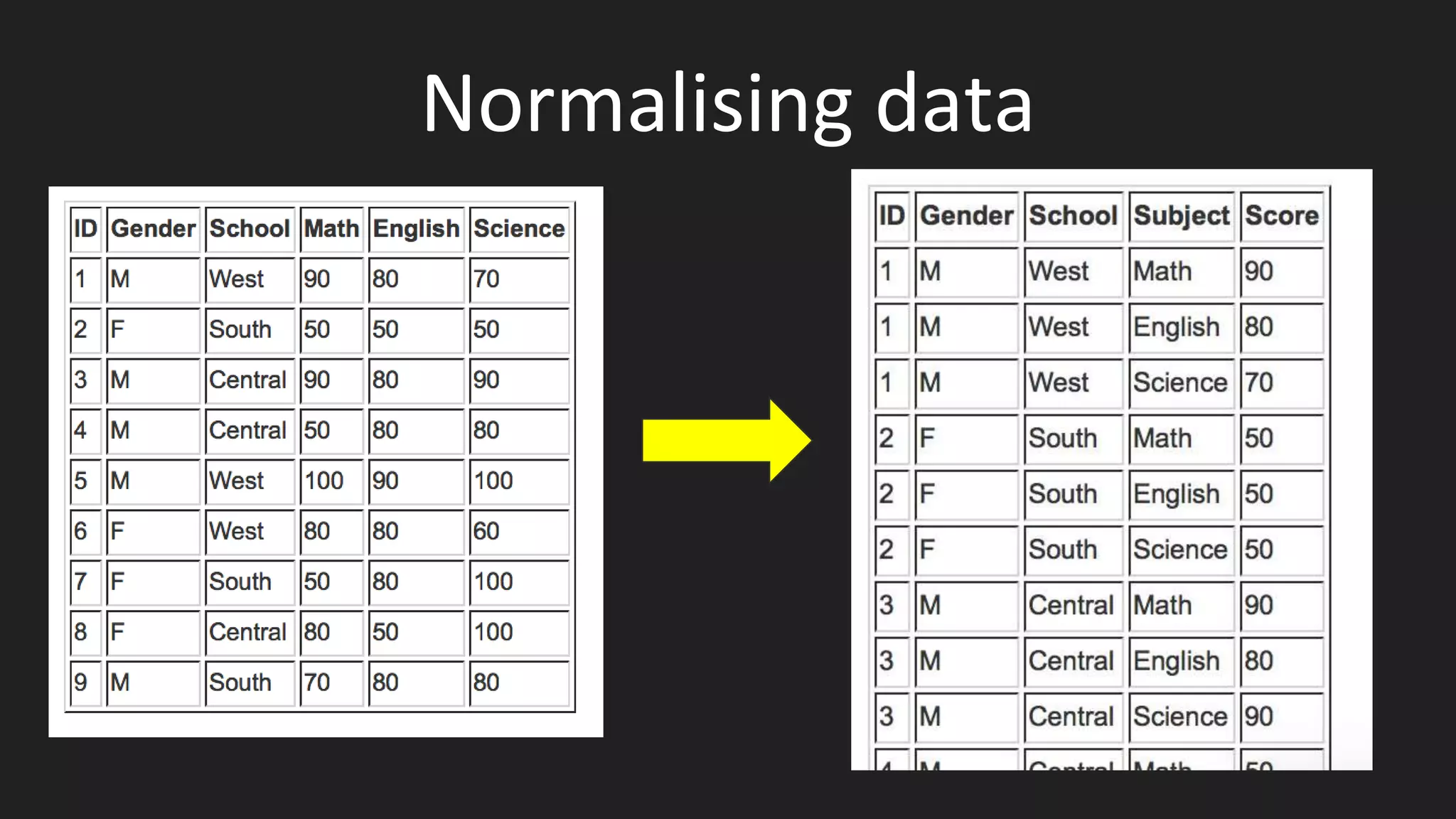





The document covers various techniques for acquiring and preparing data for data science, including data sources such as files, APIs, and web scraping. It details different data file types like CSV, JSON, and XML, and emphasizes the importance of assessing the relevance and quality of data. Additionally, it highlights tools for scraping PDFs and web data, and outlines best practices for normalization and collaborative work in data projects.























































































