Download as PDF, PPTX



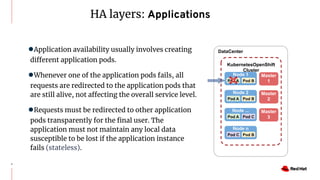
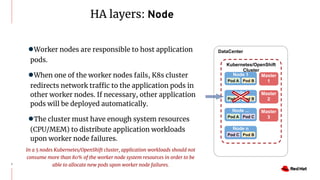
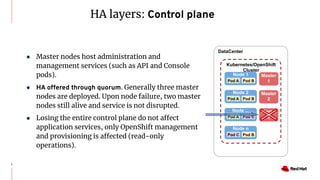


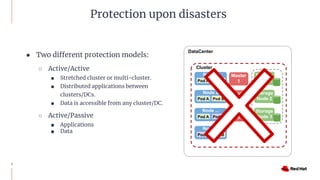


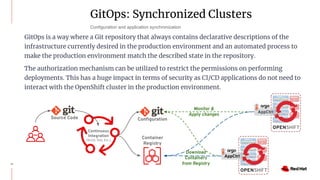







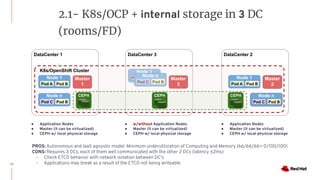
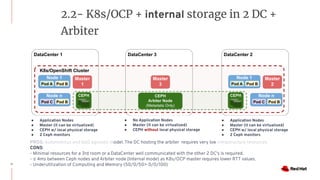
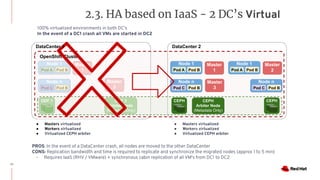






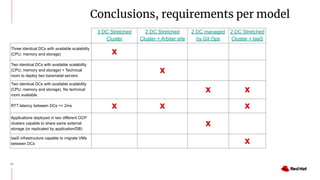
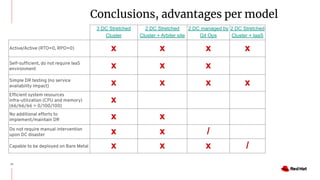


The document discusses various high availability and disaster recovery options for deploying Kubernetes clusters across multiple data centers. It begins by covering HA layers at the application, node, control plane, and data levels for a single cluster. It then examines options for multi-data center deployments including a GitOps approach with two synchronized clusters, a stretched cluster spanning three data centers, a stretched cluster with two data centers and an arbiter node, and a stretched cluster with DR provided by IaaS VM migration. Key criteria for choosing an option include the number of available data centers, latency between sites, and data access requirements for applications. A three site stretched cluster is typically the preferred model when feasible.























































































