Download to read offline




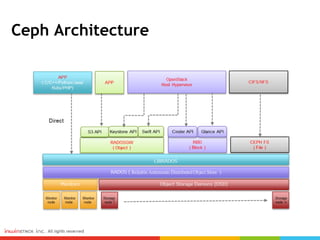
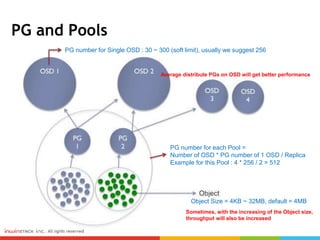









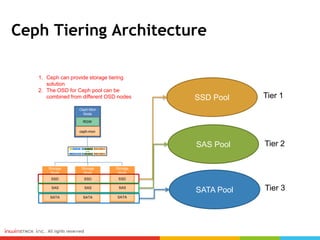
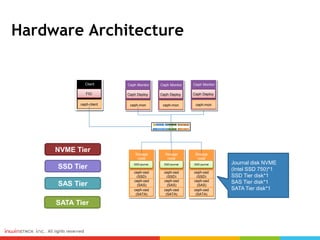


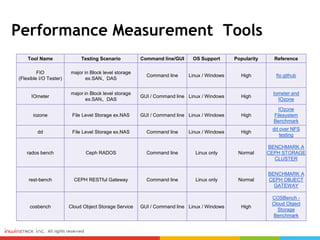


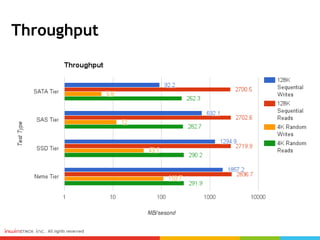
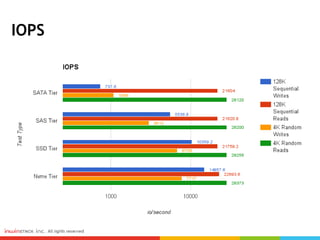


Ceph can provide storage tiering with different performance levels. It allows combining SSDs, SAS, and SATA disks from multiple nodes into pools to provide tiered storage. Performance testing showed that for reads, Ceph provided good performance across all tiers, while for writes Nvme disks had the best performance compared to SSD, SAS, and SATA disks. FIO, IOmeter, and IOzone were some of the tools used to measure throughput and IOPS.
















































































