Recommended
PDF
分散ストレージソフトウェアCeph・アーキテクチャー概要
PPTX
PPTX
PDF
PPTX
PDF
Ceph: Open Source Storage Software Optimizations on Intel® Architecture for C...
PDF
【de:code 2020】 そのロジック、IoT Edge で動きます - Azure IoT Edge 開発 Deep Dive
PDF
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
PDF
45分で理解する SQL Serverでできることできないこと
PDF
PPT
PDF
PDF
PDF
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
PDF
せっかくのOSSなんだし、ソースコード読むよね? 〜Apache Kafkaを例にしたOSSソースコードリーディングの基本〜 (Open Source C...
PDF
そんなトランザクションマネージャで大丈夫か?
PDF
昨今のストレージ選定のポイントとCephStorageの特徴
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
PDF
[PGConf.ASIA 2018]Deep Dive on Amazon Aurora with PostgreSQL Compatibility
PDF
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
PPTX
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
PDF
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
PDF
Ceph Day Tokyo - Bit-Isle's 3 years footprint with Ceph
PPTX
Ceph Day Tokyo - Bring Ceph to Enterprise
More Related Content
PDF
分散ストレージソフトウェアCeph・アーキテクチャー概要
PPTX
PPTX
PDF
PPTX
PDF
Ceph: Open Source Storage Software Optimizations on Intel® Architecture for C...
PDF
【de:code 2020】 そのロジック、IoT Edge で動きます - Azure IoT Edge 開発 Deep Dive
PDF
What's hot
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
PDF
45分で理解する SQL Serverでできることできないこと
PDF
PPT
PDF
PDF
PDF
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
PDF
せっかくのOSSなんだし、ソースコード読むよね? 〜Apache Kafkaを例にしたOSSソースコードリーディングの基本〜 (Open Source C...
PDF
そんなトランザクションマネージャで大丈夫か?
PDF
昨今のストレージ選定のポイントとCephStorageの特徴
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
PDF
[PGConf.ASIA 2018]Deep Dive on Amazon Aurora with PostgreSQL Compatibility
PDF
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
PPTX
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
PDF
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
Viewers also liked
PDF
Ceph Day Tokyo - Bit-Isle's 3 years footprint with Ceph
PPTX
Ceph Day Tokyo - Bring Ceph to Enterprise
PPTX
Ceph Day Tokyo - Delivering cost effective, high performance Ceph cluster
PPTX
Ceph Day Tokyo - Ceph Community Update
PDF
Ceph Day Tokyo -- Ceph on All-Flash Storage
PDF
Ceph Day Tokyo - Ceph on ARM: Scaleable and Efficient
PDF
Ceph Day San Jose - From Zero to Ceph in One Minute
PPTX
Ceph Day San Jose - Ceph at Salesforce
PDF
Ceph Day San Jose - HA NAS with CephFS
PPTX
Ceph Day San Jose - Red Hat Storage Acceleration Utlizing Flash Technology
PDF
Ceph Day San Jose - All-Flahs Ceph on NUMA-Balanced Server
PPTX
Ceph Day San Jose - Enable Fast Big Data Analytics on Ceph with Alluxio
PPTX
Ceph Day San Jose - Ceph in a Post-Cloud World
PPTX
Ceph Day Seoul - AFCeph: SKT Scale Out Storage Ceph
PDF
Ceph Day Seoul - Delivering Cost Effective, High Performance Ceph cluster
PPTX
Ceph Day Seoul - Ceph on All-Flash Storage
PPTX
Ceph Day Seoul - Community Update
PDF
Ceph Day San Jose - Object Storage for Big Data
PPTX
Ceph Day Taipei - Ceph Tiering with High Performance Architecture
PDF
Ceph Day Shanghai - Ceph Performance Tools
Similar to Ceph Day Tokyo - High Performance Layered Architecture
PDF
PDF
[日本仮想化技術] 2014/6/5 OpenStack最新情報セミナー資料
PDF
OSSラボ様講演 OpenStack最新情報セミナー 2014年6月
PPTX
DeNA private cloud のその後 - OpenStack最新情報セミナー(2017年3月)
PDF
PDF
How to use Ceph RBD as CloudStack Primary Storage
PDF
PDF
Hadoop operation chaper 4
PDF
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
PDF
MapR アーキテクチャ概要 - MapR CTO Meetup 2013/11/12
PDF
ソフトウェア・デファインドが再定義するストレージ -- OpenStackデファクト標準ストレージCeph - OpenStack最新情報セミナー 201...
PPTX
【Tech-Circle #3 & OCDET #7 SDS勉強会】 Ceph on SoftLayer
PDF
Storage by Red Hat #rhcpday 2015
PPTX
PDF
20180423 OpenStackユーザー会 SDS
PDF
PCCC23:Pacific Teck Japan テーマ1「データがデータを生む時代に即したストレージソリューション」
PDF
Cloudera Manager4.0とNameNode-HAセミナー資料
PDF
Hadoop, NoSQL, GlusterFSの概要
PDF
Cephを用いたwordpressの構築[LT版]
Ceph Day Tokyo - High Performance Layered Architecture 1. 2. 3. 4. 5. 6. PG と Pools
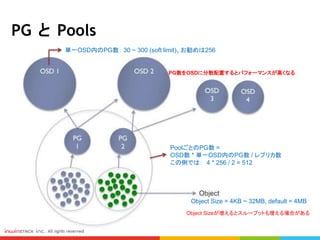
単一OSD内のPG数: 30 ~ 300 (soft limit)、お勧めは256
PoolごとのPG数 =
OSD数 * 単一OSD内のPG数 / レプリカ数
この例では: 4 * 256 / 2 = 512
Object Size = 4KB ~ 32MB, default = 4MB
Object Sizeが増えるとスループットも増える場合がある
PG数をOSDに分散配置するとパフォーマンスが高くなる
7. CRUSH Maps
CRUSH Map Parameter
1. Setting : 基本の設定(Settingを変更する必要
はめったにない)
2. Device: 物理Device List(全てのOSD Deviceを
リストし、IDとNameのマッピングを定義す
る)
3. Type: Bucket Typeを定義(Root~OSD)
4. Bucket: OSD Group 及び 階層化構造を定義
5. Rule : CRUSH rule (object chunkを定義)
8. 9. 10. 11. 12. CRUSH Maps
Rules
ruleset : rule_id
type : object chunkの種類 (レプリカ、 erasure)
min_size : レプリカ数がこの設定を下回る場合、PoolはこのRuleを選びません
max_size :レプリカ数がこの設定を上回る場合、PoolはこのRuleを選びません
step take :このRuleにマッピングするosd_treeのを設定
step chooseleaf : object chunkのレプリカのマッピング方法を設定。例えば、
“step chooseleaf firstn 0 type host” はHostでレプリカ数を設定(各Hostに配置され
たレプリカ数は1)
13. 14. 15. 16. 17. 18. 19. 20. パフォーマンス測定ツール
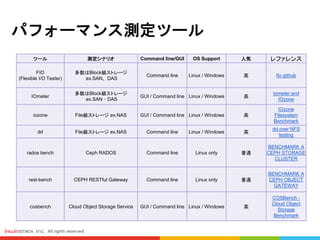
ツール 測定シナリオ Command line/GUI OS Support 人気 レファレンス
FIO
(Flexible I/O Tester)
多数はBlock級ストレージ
ex.SAN、DAS
Command line Linux / Windows 高 fio github
IOmeter
多数はBlock級ストレージ
ex.SAN、DAS
GUI / Command line Linux / Windows 高
Iometer and
IOzone
iozone File級ストレージ ex.NAS GUI / Command line Linux / Windows 高
IOzone
Filesystem
Benchmark
dd File級ストレージ ex.NAS Command line Linux / Windows 高
dd over NFS
testing
rados bench Ceph RADOS Command line Linux only 普通
BENCHMARK A
CEPH STORAGE
CLUSTER
rest-bench CEPH RESTful Gateway Command line Linux only 普通
BENCHMARK A
CEPH OBJECT
GATEWAY
cosbench Cloud Object Storage Service GUI / Command line Linux / Windows 高
COSBench -
Cloud Object
Storage
Benchmark
21. 22. 23. 24. 25. 26. Editor's Notes #3 crush mapを設定することで階層化を実現
階層化後のPerformance測定の結果
#5 こちらでCephの利点を簡単に説明します
Cephは分散ソフトウェアなので、単一障害点はないです
Open Sourceなのでベンダーロックインは一切なしです
汎用のサーバーを採用するので、コスト削減を達成します
大規模のスケールアウトができる。ノードの増設は何十台から何千台まで拡張できる
Object -> Dropboxに相当するUse Case
Block -> OpenStackとの連携、ファイルシステムとの統合
File -> CephFs instead of NFS
Cephの最新版Jewelがリリースされたら、 CephFsは安定
- Crush map allows customization, tiering, DR….
Big Dataの分散ストレージの話といえば、CephをHadoop HDFSと比較する人が多いです。確かに、基本の機能は似てますけど(Replication、分散ストレージ、スケールアウトなど)、CephはBlock、Object、FileのProtocolをサポートしています。
HDFSはFileしかサポートしてないです。
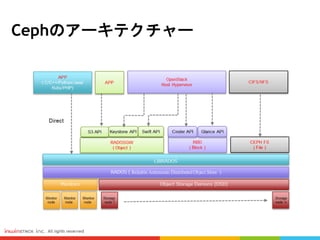
それに、CephはCrush Mapを利用しています。Crush Mapの設定でDRアーキテクチャー、三つのレプリカ数まで三つのクラスタ内に複製できる、っていう設定は可能になりますので、HDFSの場合はできないです。 #6 こちらはCephのアーキテクチャーです
下のほうはCeph MonitorとOSDが配置されてます
(高可用性のため3台のモニターノードが必要)
(OSDノード - ここでデータを格納する。使用者のニーズに応じて、OSDノードを増設すれば拡張できます)
RADOSはCephの中核(ちゅうかく)で, データをオブジェクトとして分散管理する仕組みです
上のほうはLIBRADOSというAPIで、ここにてアプリケーションを直接に連携することが可能です
LIBRADOSの上にはRADOSGW、RBD、CephFS
3種類のプロトコルを提供してます
-RADOWSGWは、S3とOpenStack APIに対応します
-RBDは、CinderとGlance APIに対応します。OpenStackと連携する場合は一番採用されてます。
-CephFSは、NFS/CIFSに対応します。Jewelがリリースされてから安定してきました。もともとNFS/CIFSと連携する時はRBDを採用
#7 CRUSH MAPを紹介する前に、まずPGとPoolという重要な概念を話したいと思います
データはオブジェクトとしてPGやPoolに分散して格納されます
各オブジェクトのSizeは設定できますが、普段は4KB ~ 32MBまでという範囲です。Defaultは4MB。
状況によってObject Sizeが増えるとスループットも増える場合があります
PGはPoolごとに入っています。高いパフォーマンスを確保するために、PGはできる限りOSD(HardDisk)に分散配置します。
PoolごとのPG数の算出するには、こちらの公式になります
OSDごとのPG数は Soft Limit(制限の範囲)があります。普段は256をお勧めします
続きまして、Cephで利用したCRUSHマップというアルゴリズムを話したいと思います #8 基本的にCephの中核(RADOS)はCRUSHマップというアルゴリズムで構成されてます。
CRUSHマップの設定により色々な機能ができます。そして良いパフォーマンスも達成します
CRUSHマップについて、五つのパラメータを利用しています:Setting、Device、Type、Bucket、Rules
Device: 物理Device、例えばハードディスク
Type:Root、Host、OSDのLocationまですべて表示します
Typeは色々なUse Caseに応じて設定が変わります
Typeの設定はRuleで変更します
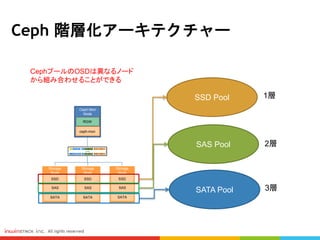
Bucket: Tiering Structureの設定、OSD Groupの定義
続きまして、どういうふうにCRUSHマップの設定でTieringを達成するかを説明します #9 こちらはDefaultのOSD Treeです
Root=Cluster
3Hosts In this Ceph Cluster
OSDノードが三つありまして、ノード毎にOSDハードディスクが6台(三台のSATAと三台のSSD)があります
つまり、各OSDノードにSATA PoolとSSD Poolが入っています #10 CRUSHマップのDefault Settingです。
普段は変える必要ないです。 #11 こちらはDeviceリストとそれぞれのMappingされてるOSDです
Define how 3 replicas are distributed
こちらはTypeリスト #12 Bucketの設定です
ここでbucket 定義内のOSDの重み付け(weight)を設定できます #13 CRUSHルールには重要なパラメータが六つあります:
まずは、Rule IDはRulesetで設定します
Typeはオブジェクトチャンクの種類を定義します。ユースケース シナリオによって、レプリカ或いはErasureコードを設定できます
min size と max sizeはPoolがこのRuleを選ぶかという判定基準になります
step take はこのRuleにマッピングするosd_treeを設定
step chooseleaf はobject chunkのレプリカのマッピング方法を設定。この場合レプリカ数はHostで設定(Hostごとに配置されたレプリカ数は1)
#14 設定後のOSD Treeの状態です
二つのPoolにに分けています。
SSD PoolとSata Pool #15 ceph OSD crush rule list というCommandでも現在のRulesetを確認できます
ceph osd dump というCommandでPool Listを表示します #17 ストレージ階層化とは、複数種類のHarddiskを使って階層を作り、データの特性に応じてそれぞれのストレージ階層に振り分けられる
メリット:効率的にデータのストレージを管理する
Cost
Databaseのように性能を必要とするDataはSSDのような高性能のHarddiskに格納
VM、ApplicationなどはSASに格納
Snapshot、Backupのように容量が重要なDataはSATA Poolに格納
基本的にHarddiskの台数はポイントです
一台のSSDは4台のSATAより性能が低い
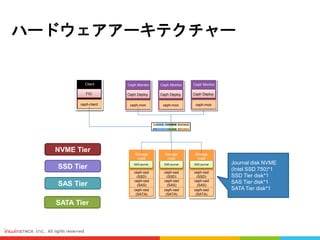
Cephという分散システムでは、OSD数とかHost数が多ければ多いほど、性能が良くなる #18 Performanceのテストは4種類のHarddiskに測定を行います。 #20 FIO、IOMETER、DD 一番よく使われてます #21 人気あるツールはLinuxとWindows両方サポートしています
普段の場合はFIOが一番使われてます
単一のHardDriveに測定を行う場合はDDを利用することが多い
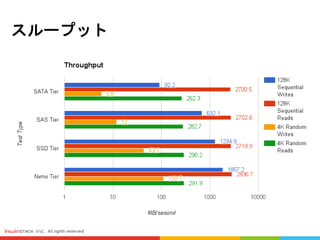
RadosGWとかObjectを測定する時はRadosBench、Rest-Bench、CosBenchを採用します #24 4種類のHarddrive(SATA、SAS、SSD、NVME SSD)に対してスループットの測定を実行しました
測定条件は128Kブロックサイズと4Kブロックサイズの読み書きがテストされます
測定結果によると、NVMEの書き込みパフォーマンスが一番良い、そしてSSD、SAS、SATA
しかし、読み込みの部分は大抵同じです
128Kのスループットはずっと4Kより良いと評価されました
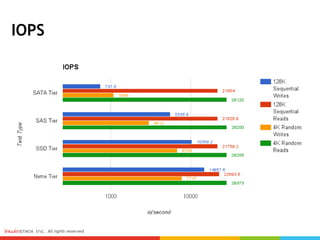
#25 IOPSについても一緒ですが、書き込みの場合はNVMEがダントツ一位です。
読み込みの場合もあんまり変わらなくて、測定結果は大抵一緒です #26 階層化管理を通して、









































![[PGConf.ASIA 2018]Deep Dive on Amazon Aurora with PostgreSQL Compatibility](https://cdn.slidesharecdn.com/ss_thumbnails/20181212pgconfasiaaurorapostgresql-181212055637-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[日本仮想化技術] 2014/6/5 OpenStack最新情報セミナー資料](https://cdn.slidesharecdn.com/ss_thumbnails/140605openstackcephbenchmark-140605203155-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















![Cephを用いたwordpressの構築[LT版]](https://cdn.slidesharecdn.com/ss_thumbnails/cephwordpresslt-170619022947-thumbnail.jpg?width=640&height=640&fit=bounds)