
![@atseitlin
About Netflix
Netflix is the world’s
leading Internet
television network with
more than 36 million
members in 40
countries enjoying more
than one billion hours
of TV shows and movies
per month, including
original series[1]
[1] http://ir.netflix.com/](https://image.slidesharecdn.com/qconnewyork-resiliencythroughfailure-130615071714-phpapp01/85/Resiliency-through-failure-QConNY-2013-2-320.jpg)

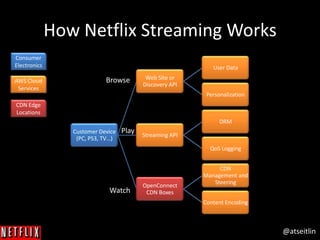






















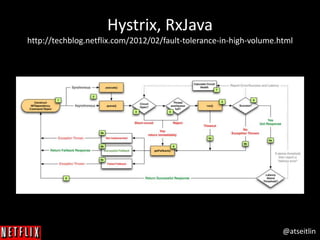









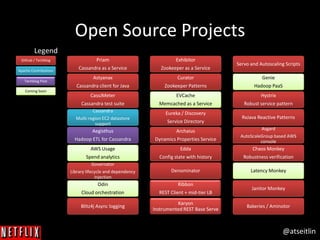






The document outlines Netflix's approach to achieving high availability in its cloud infrastructure by designing systems that can gracefully handle failures. It emphasizes the importance of proactively inducing failure through methods such as the Simian Army tools (e.g., Chaos Monkey) to validate system resiliency and improve operational robustness. The document also highlights a blameless culture that fosters learning from failures and the significance of deep system visibility to understand and resolve issues.























































































