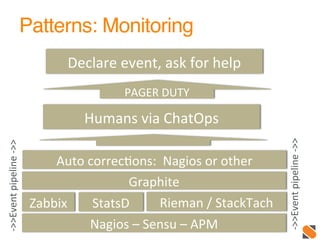
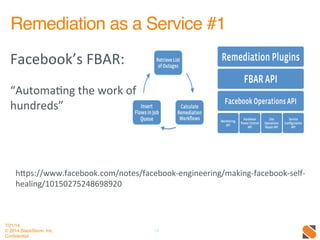
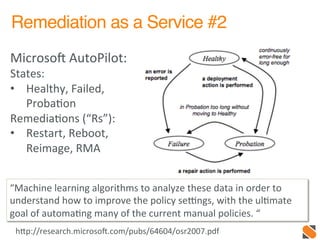
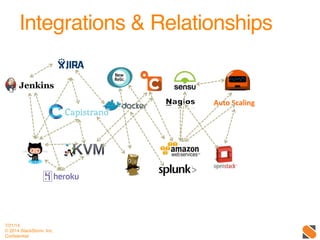
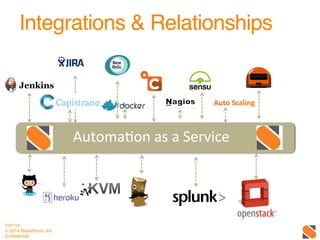
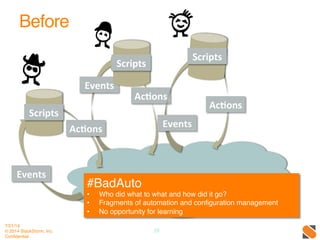
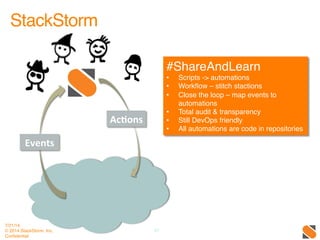
The document discusses operational patterns and automation tools for DevOps. It covers monitoring patterns such as treating monitoring as a service and addressing pager fatigue. Remediation patterns discussed include automating responses to alerts like Facebook's FBAR system. Common tools mentioned are New Relic, Splunk, Puppet, Chef, Ansible and Salt. Best practices for automation include keeping things simple, separating concerns, and providing context to humans when they are required to intervene. ChatOps and using chat interfaces for operations are also discussed.












































![[OpenInfra Days Korea 2018] (Track 2) Neutron LBaaS 어디까지 왔니? - Octavia 소개](https://cdn.slidesharecdn.com/ss_thumbnails/26octavia-180704054917-thumbnail.jpg?width=640&height=640&fit=bounds)



























































