








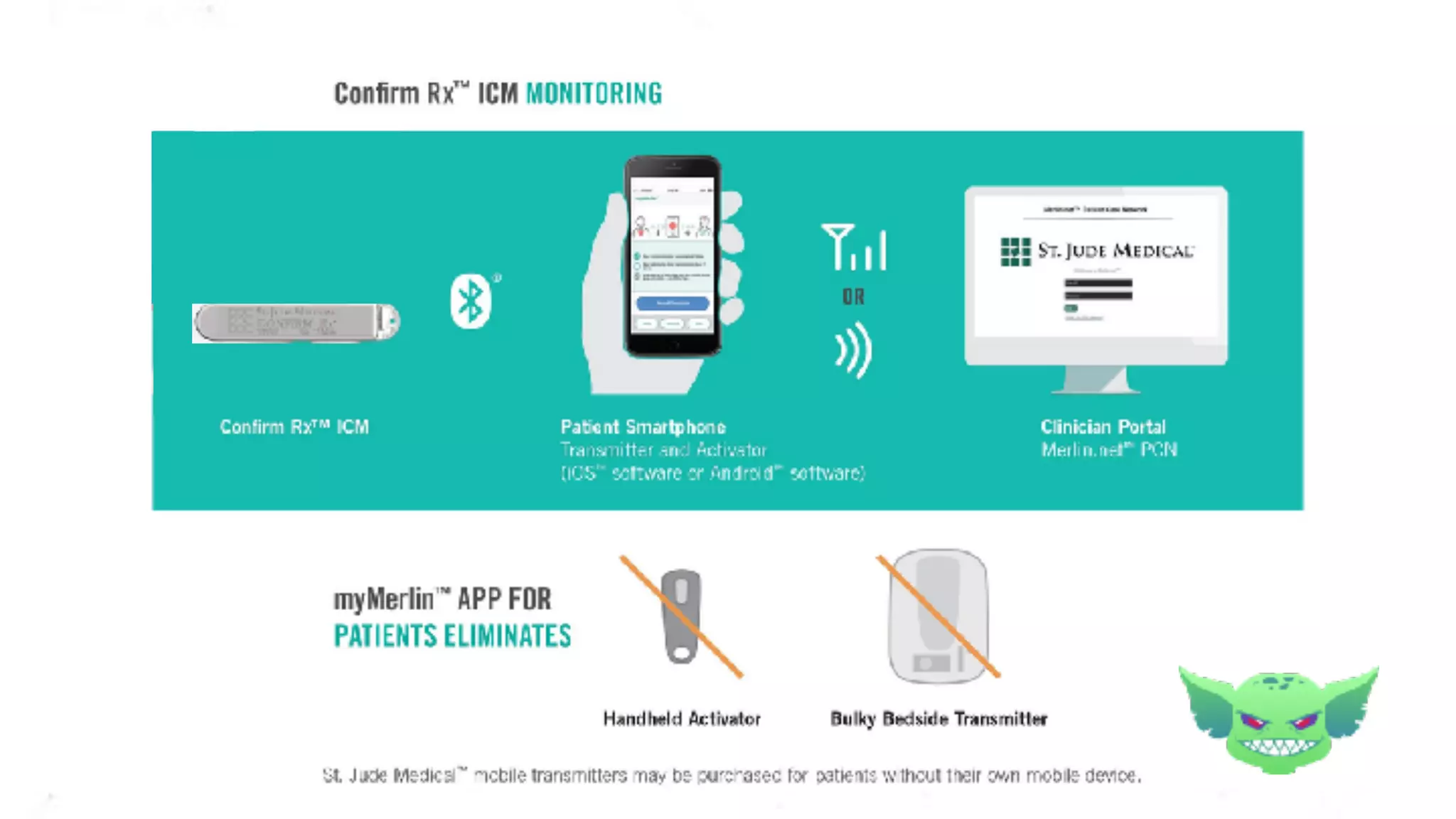









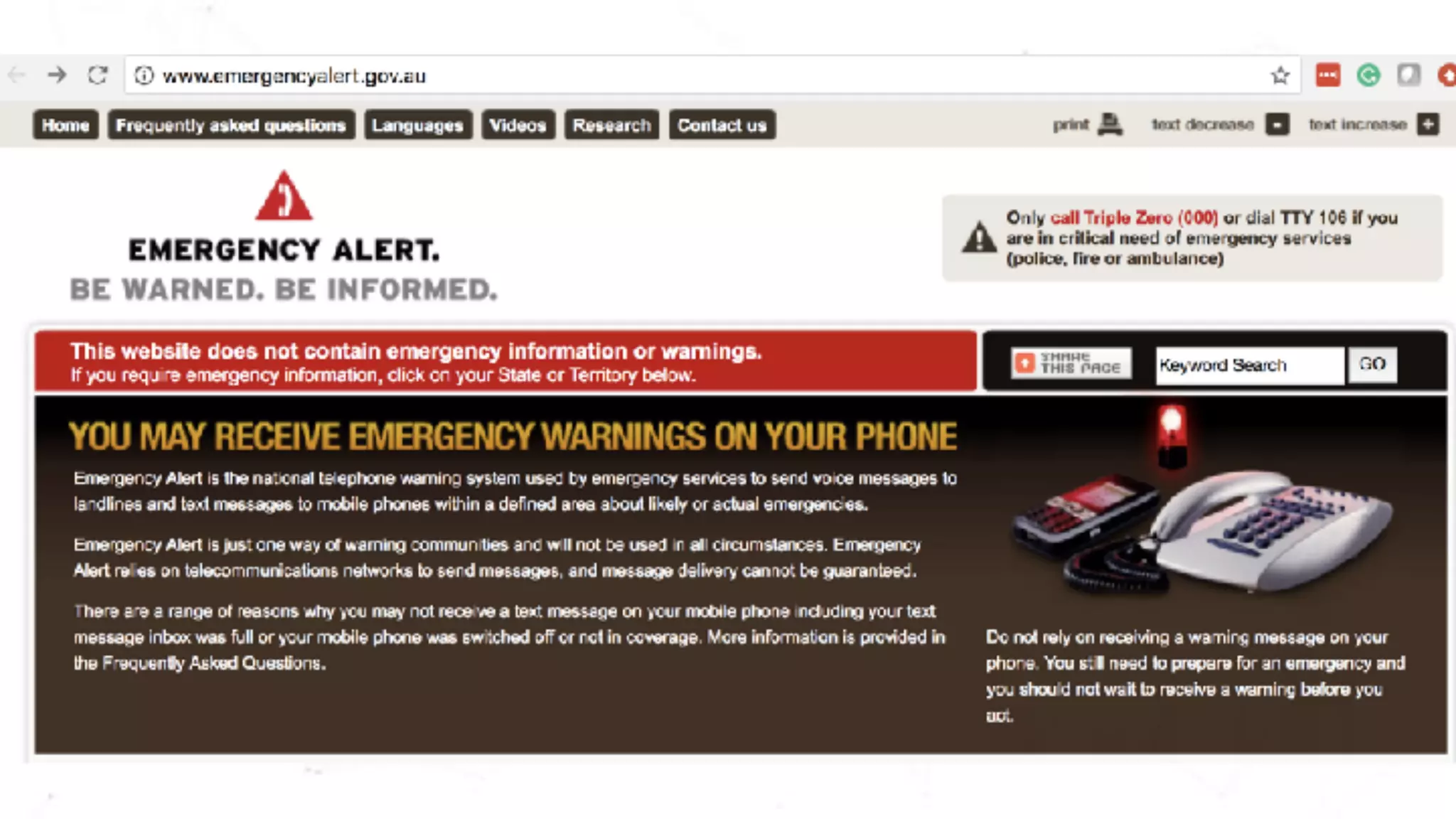






















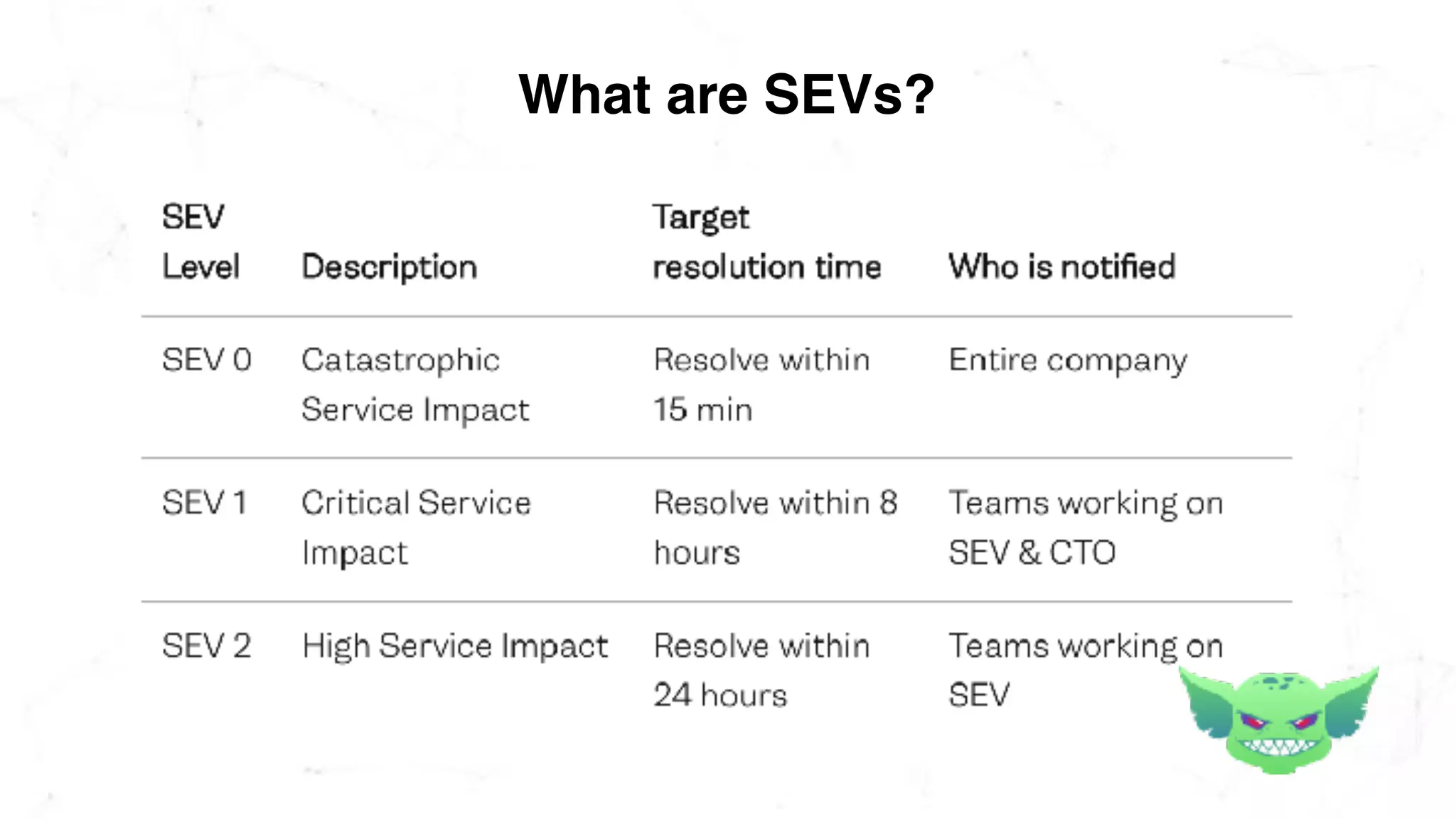
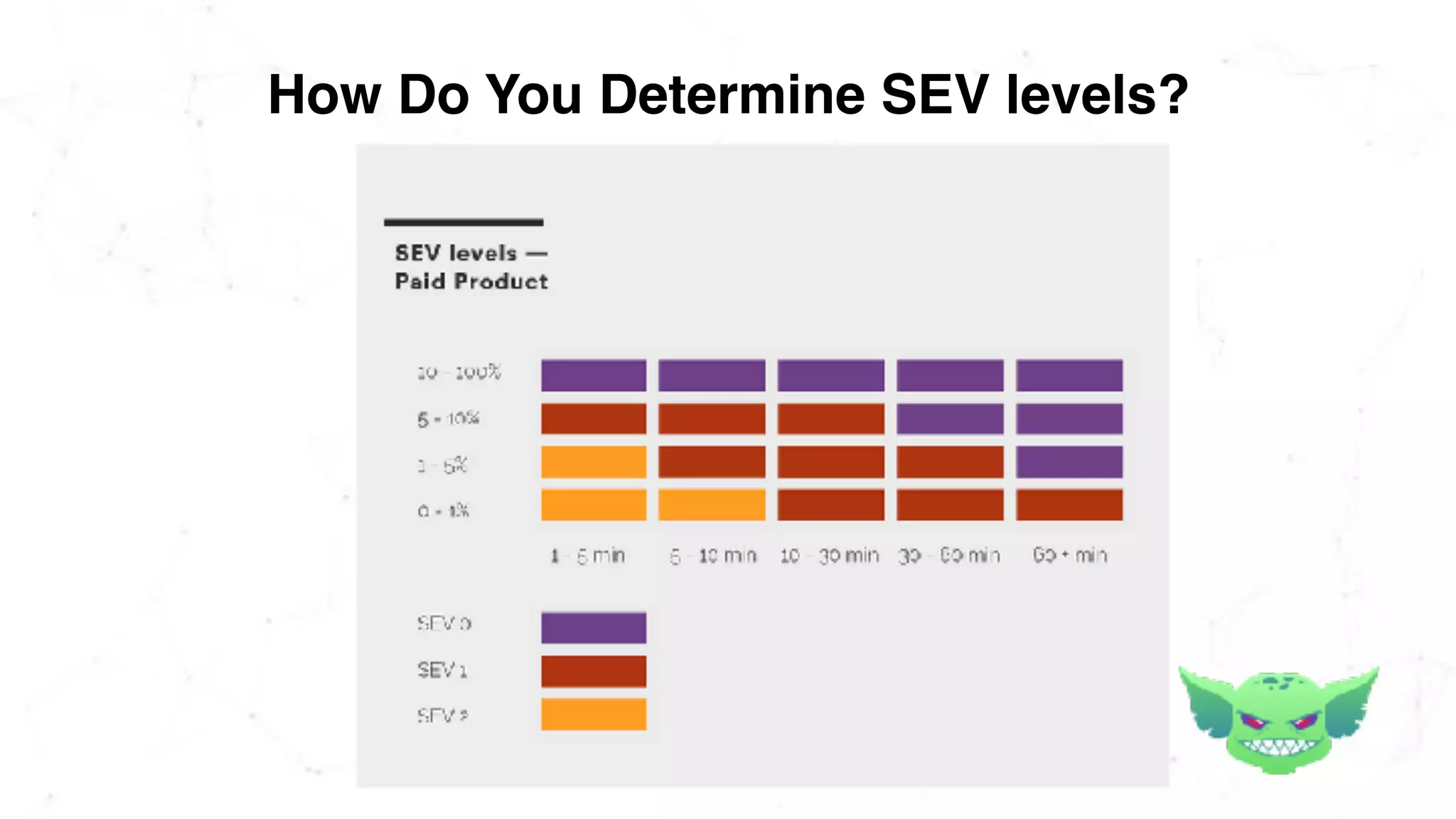

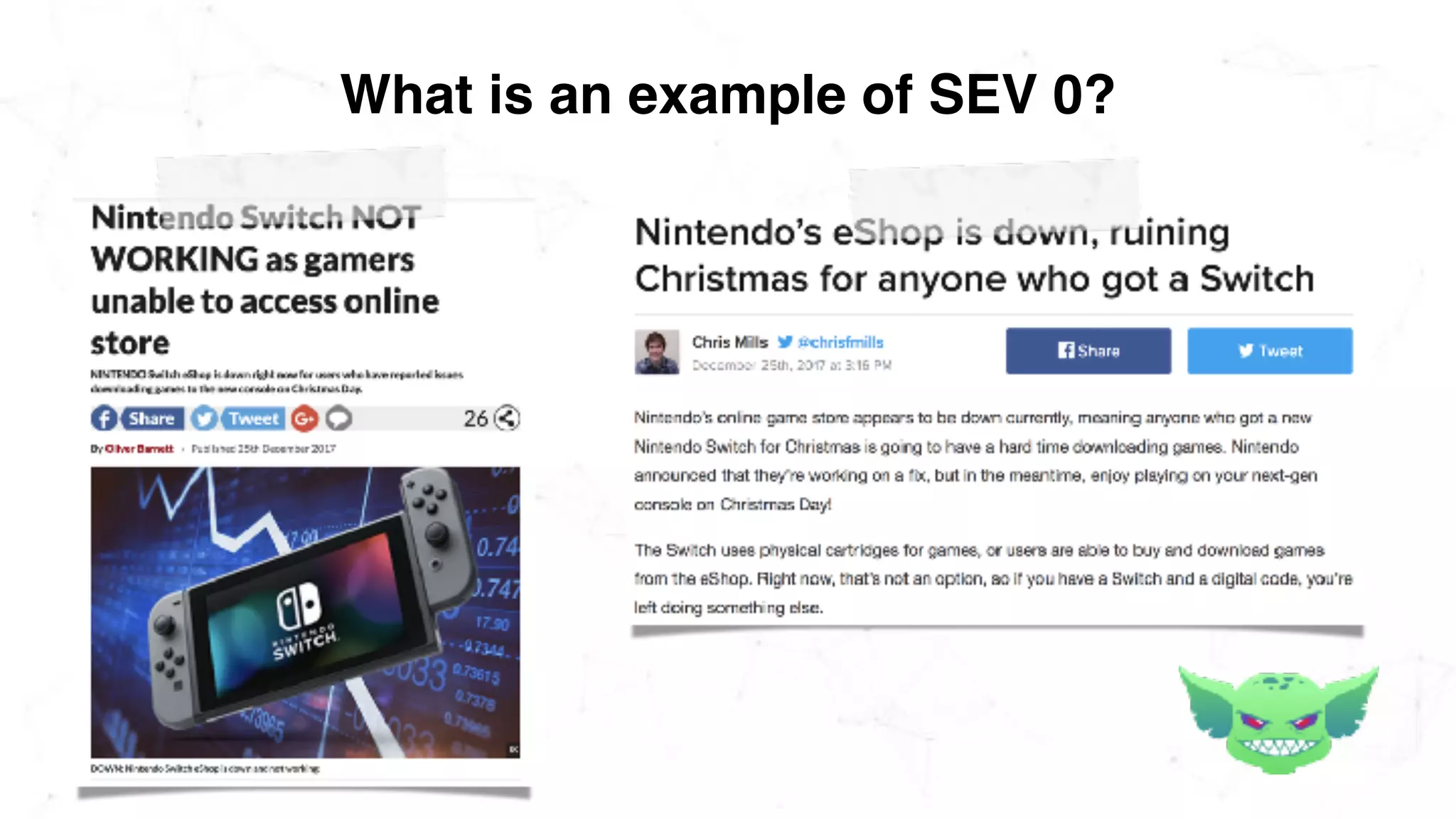









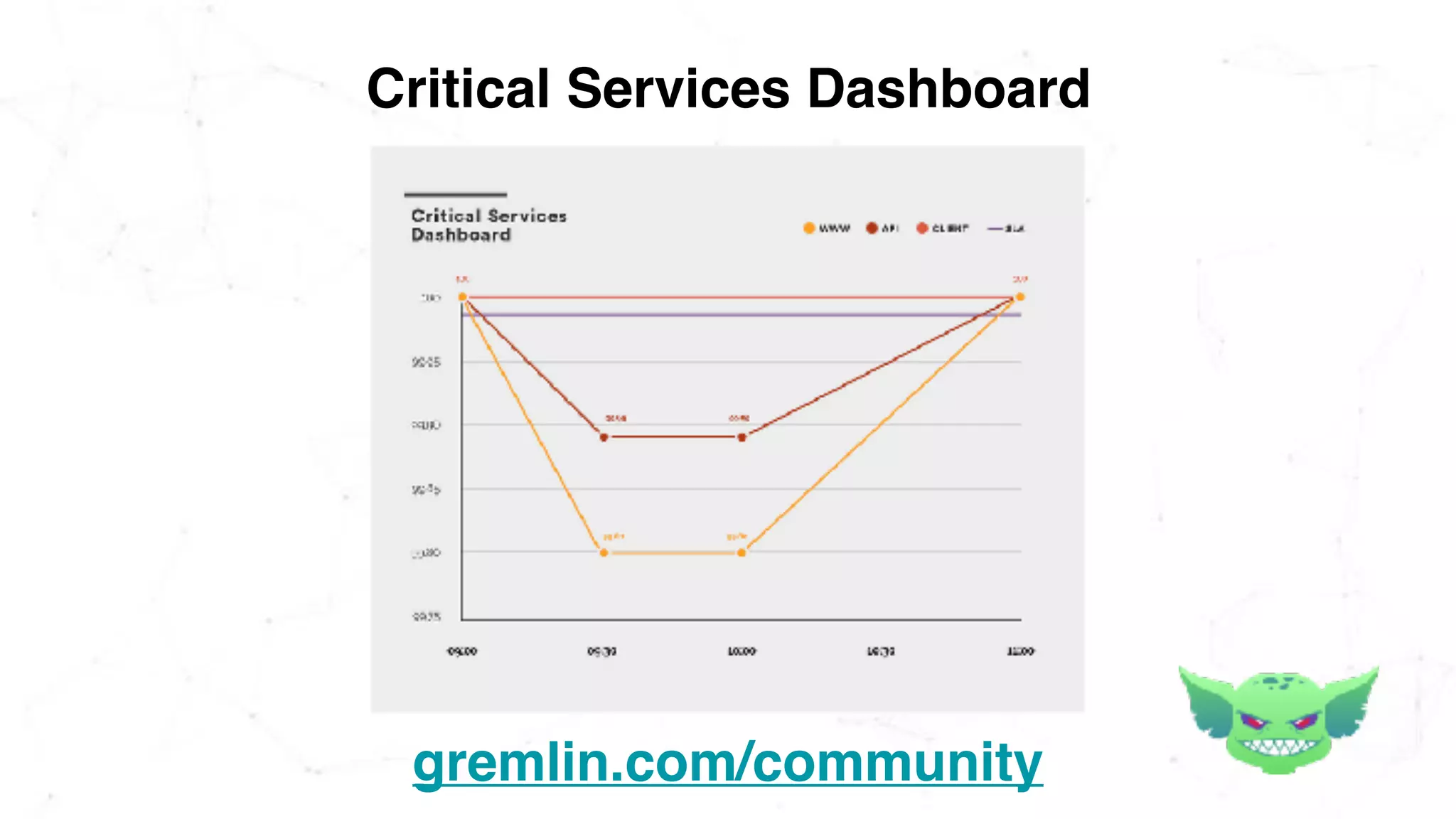







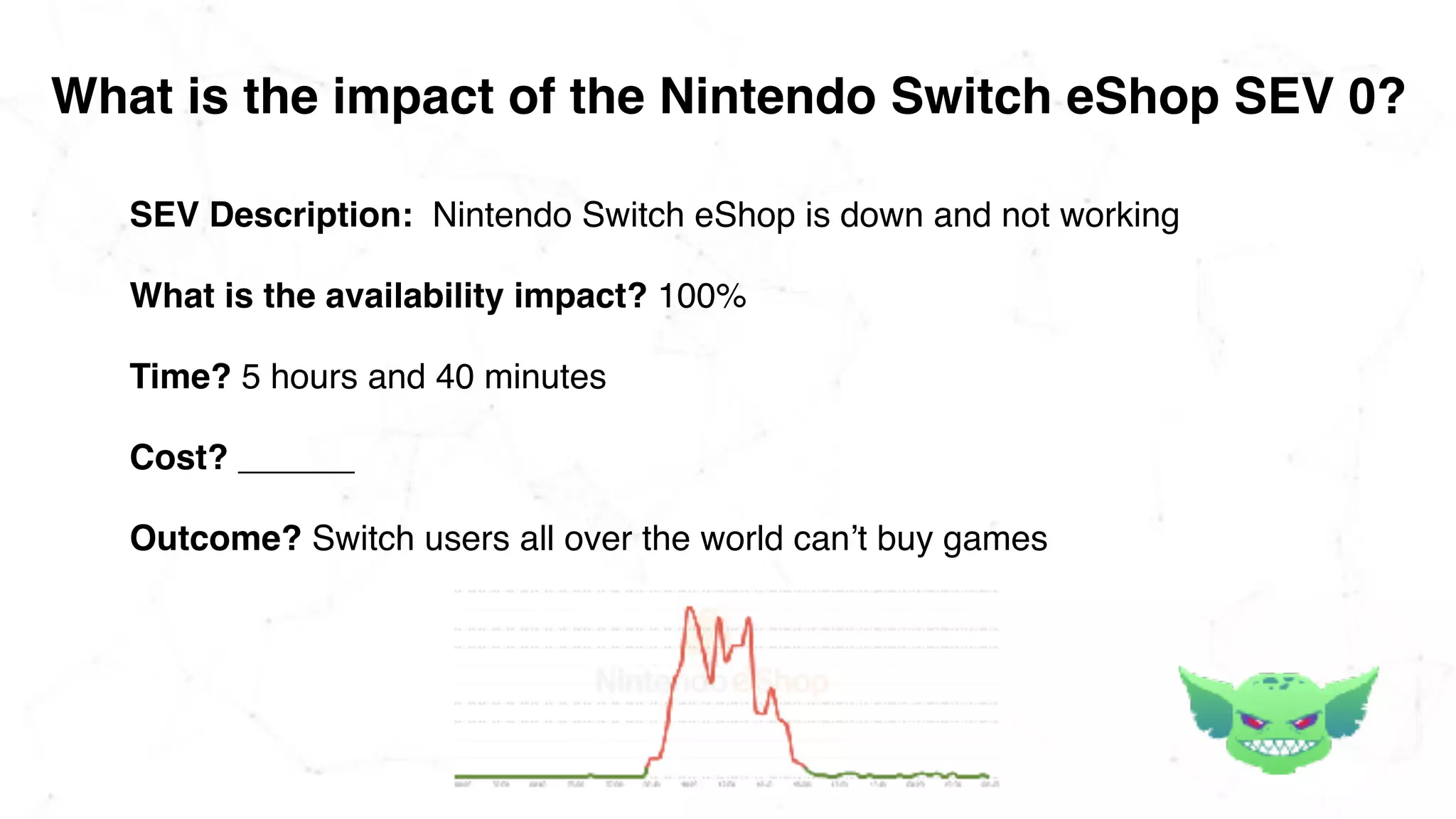

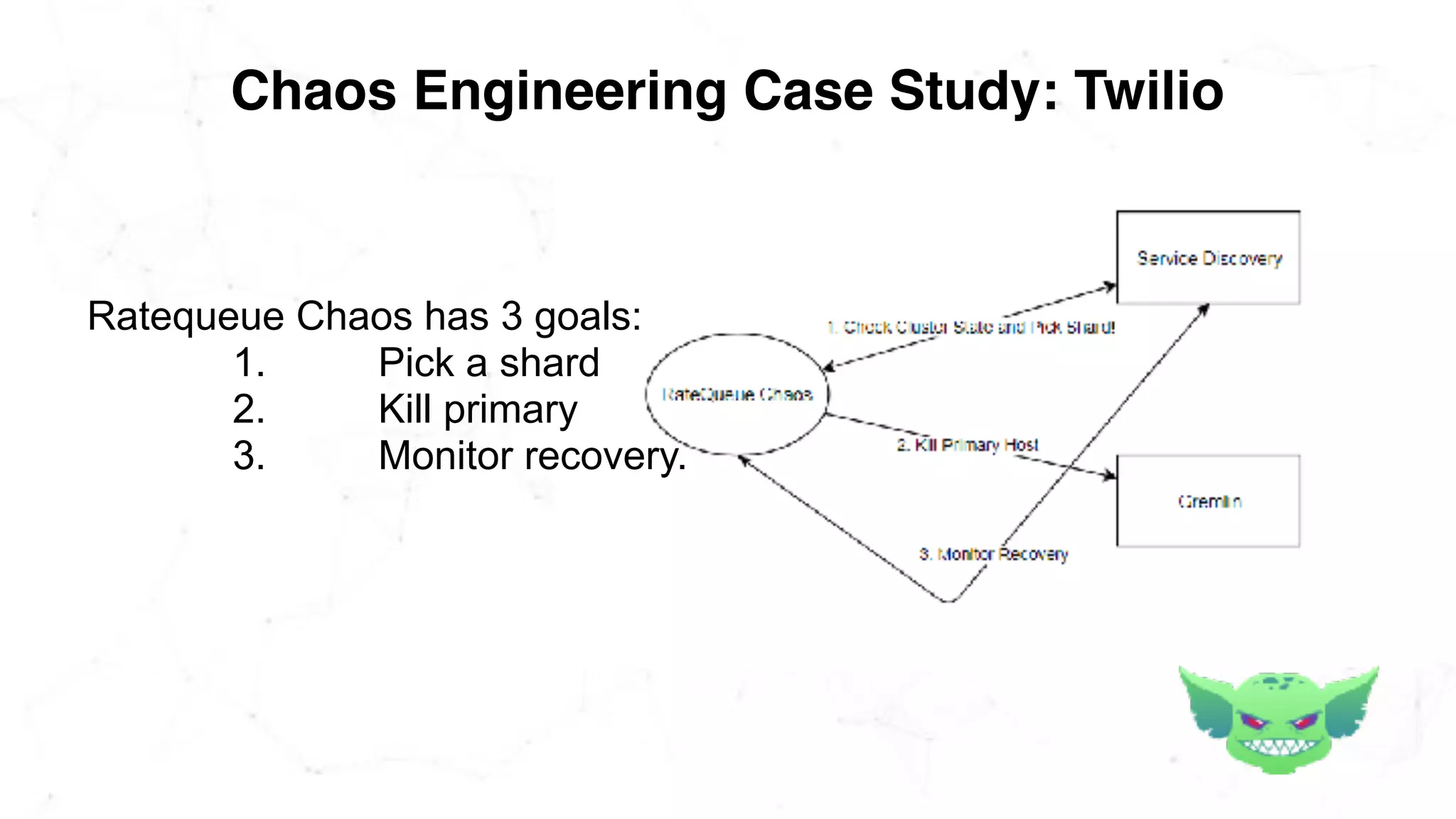







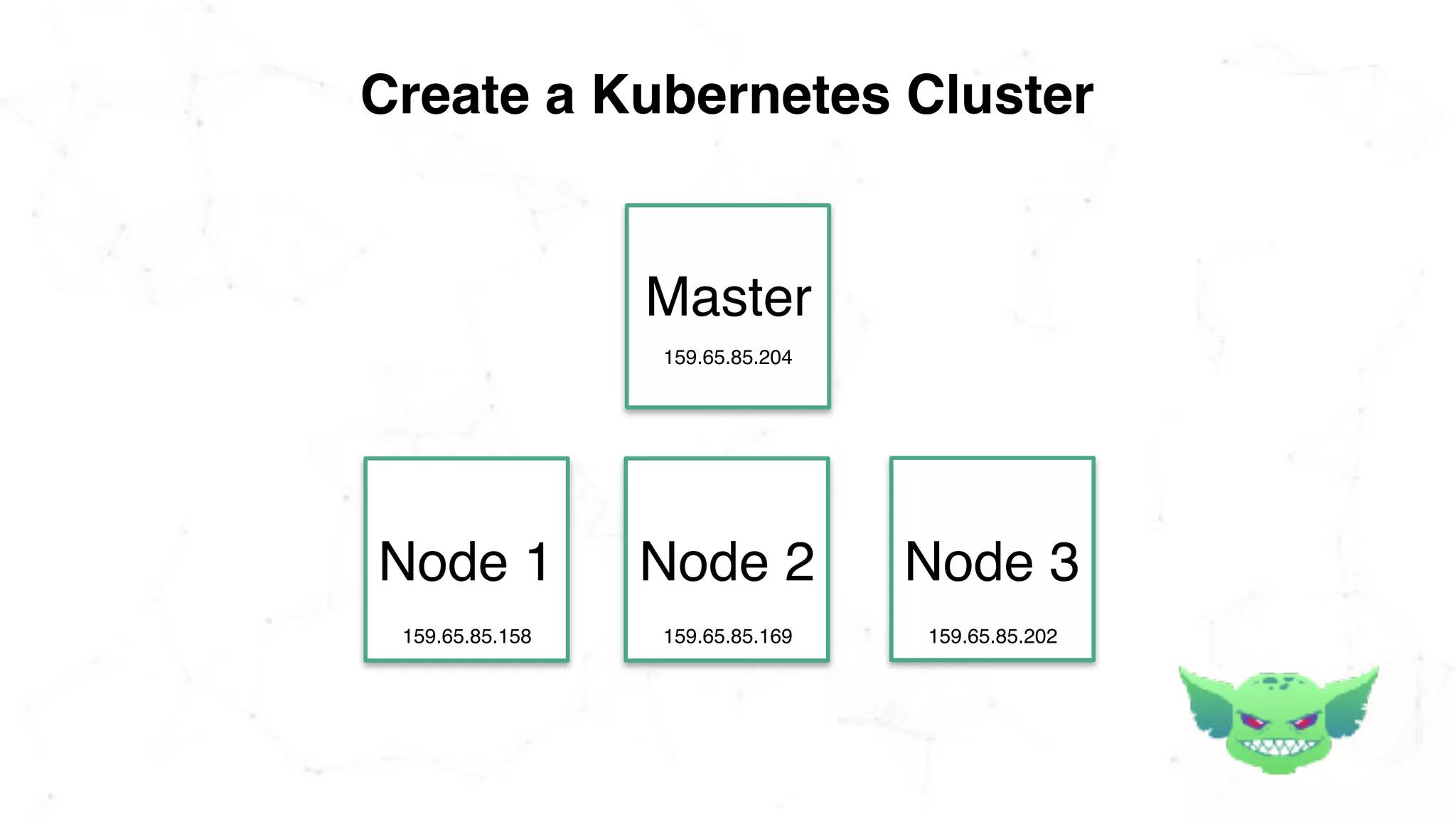



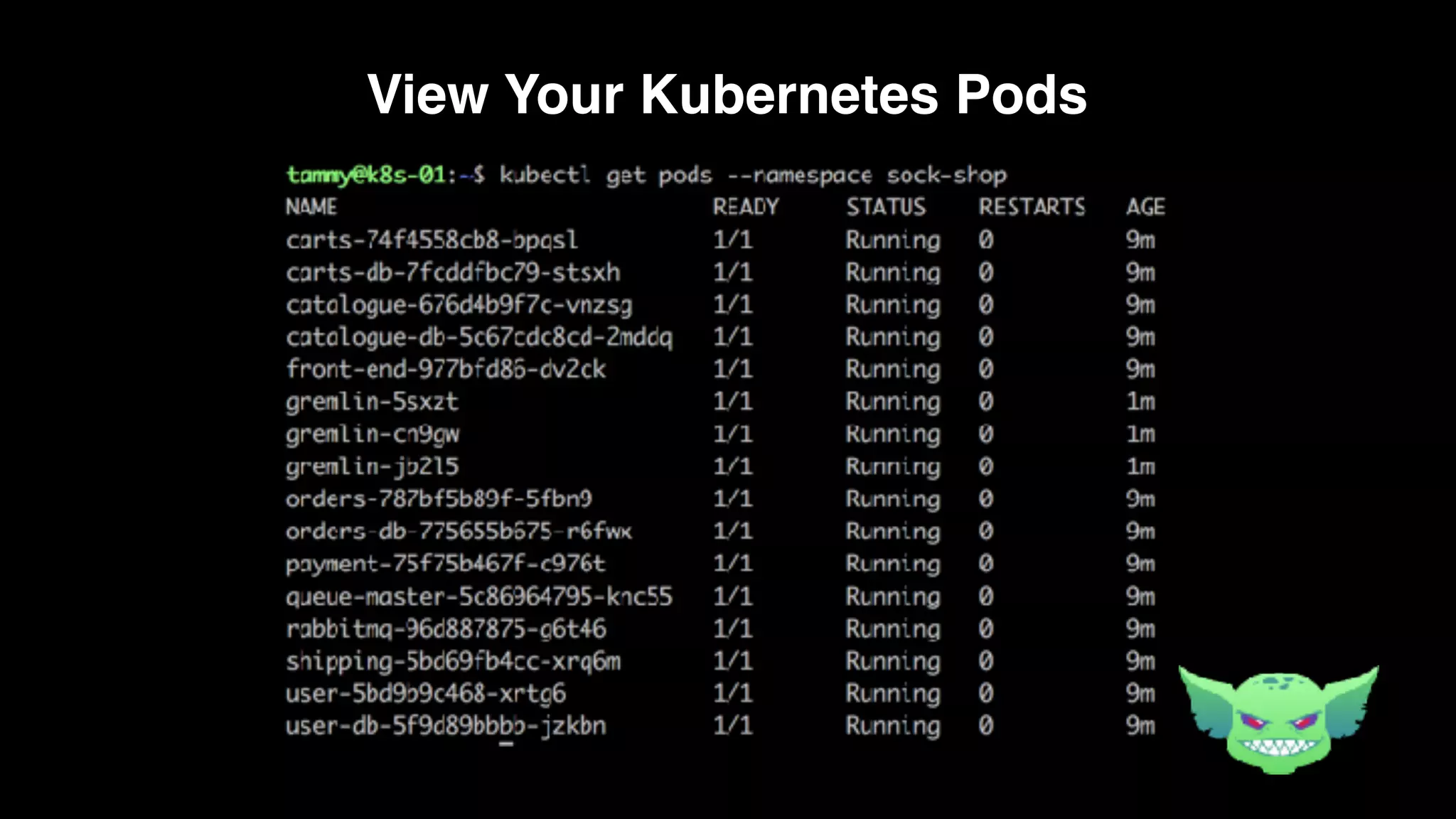
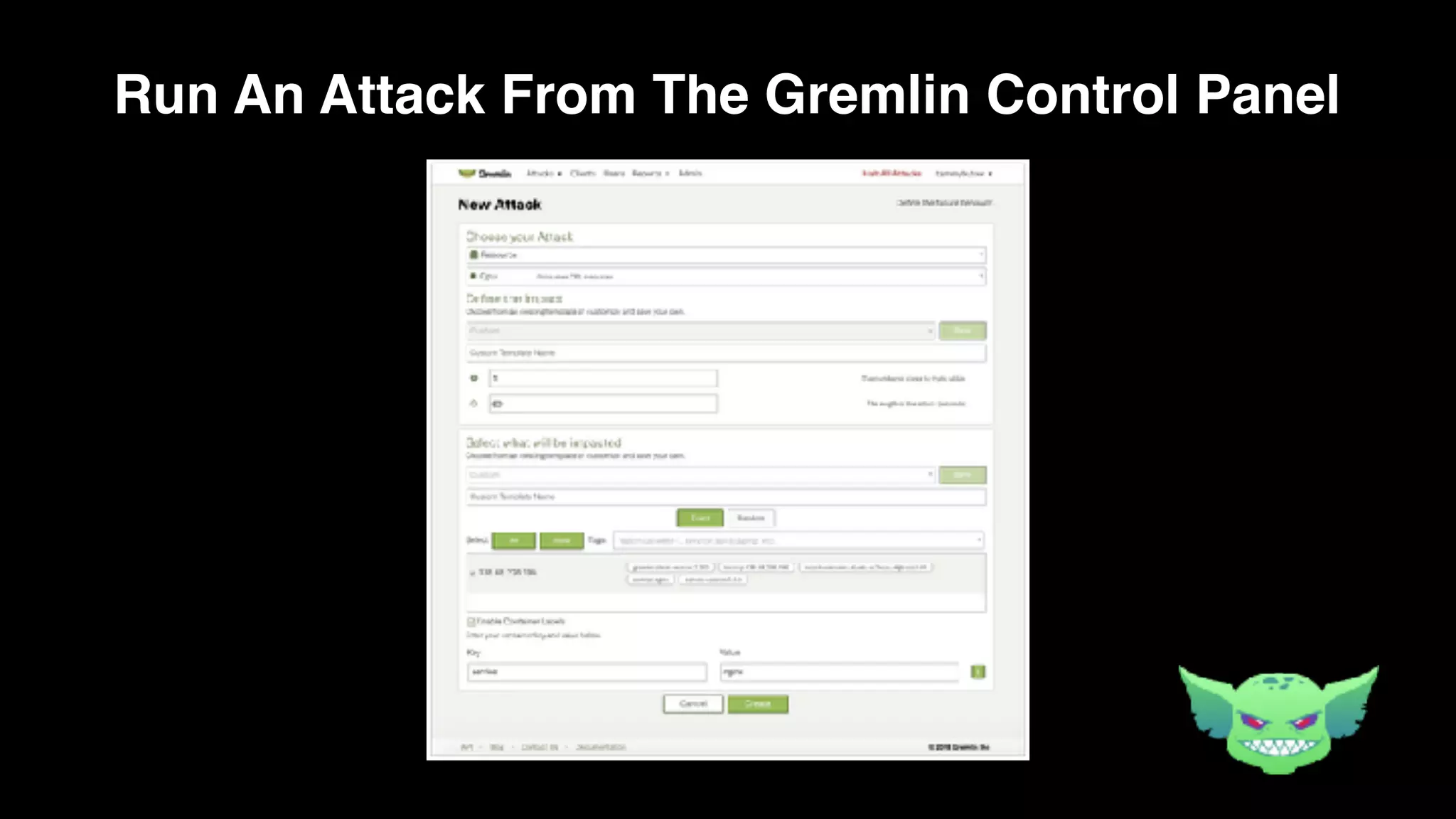
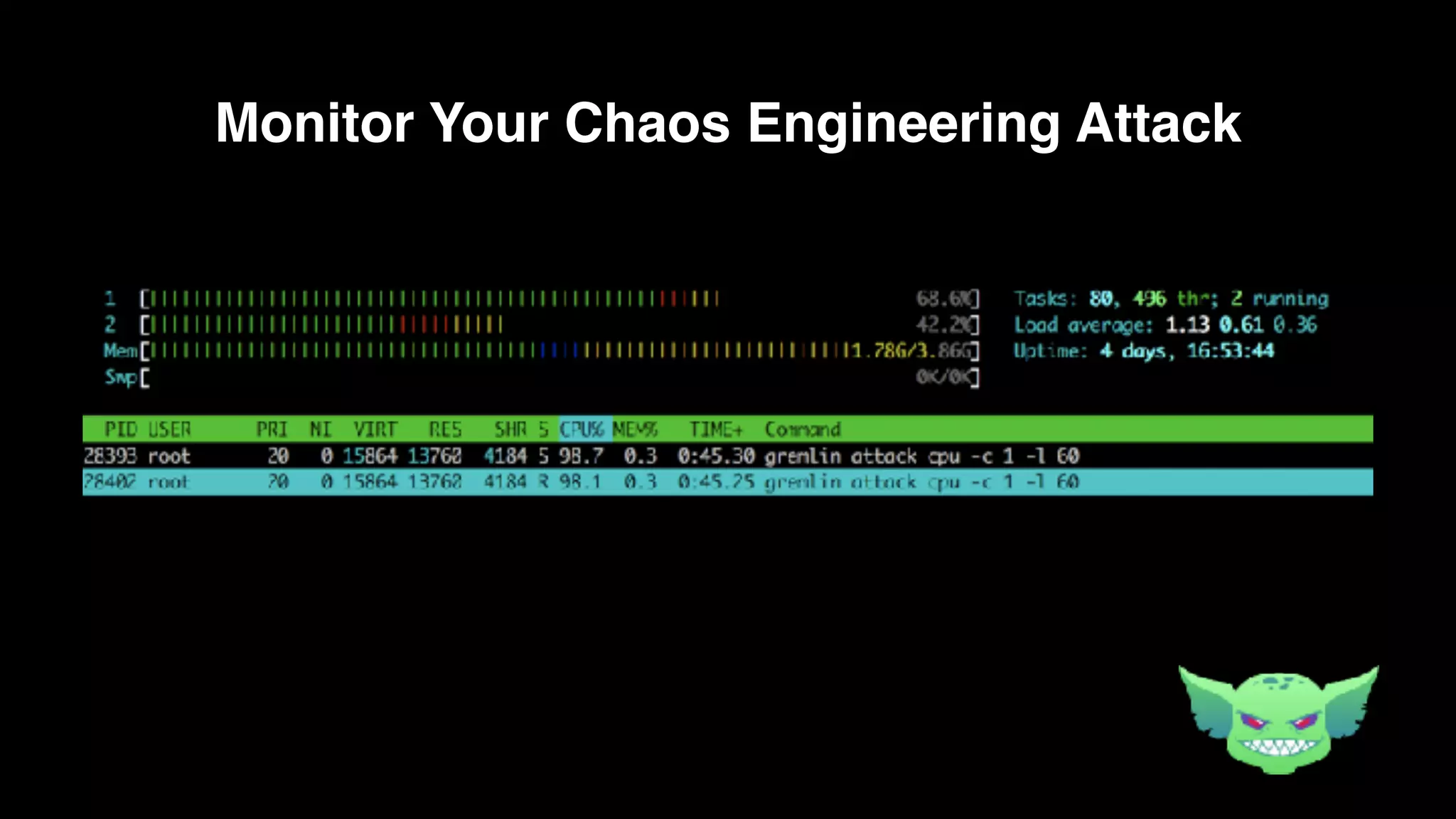

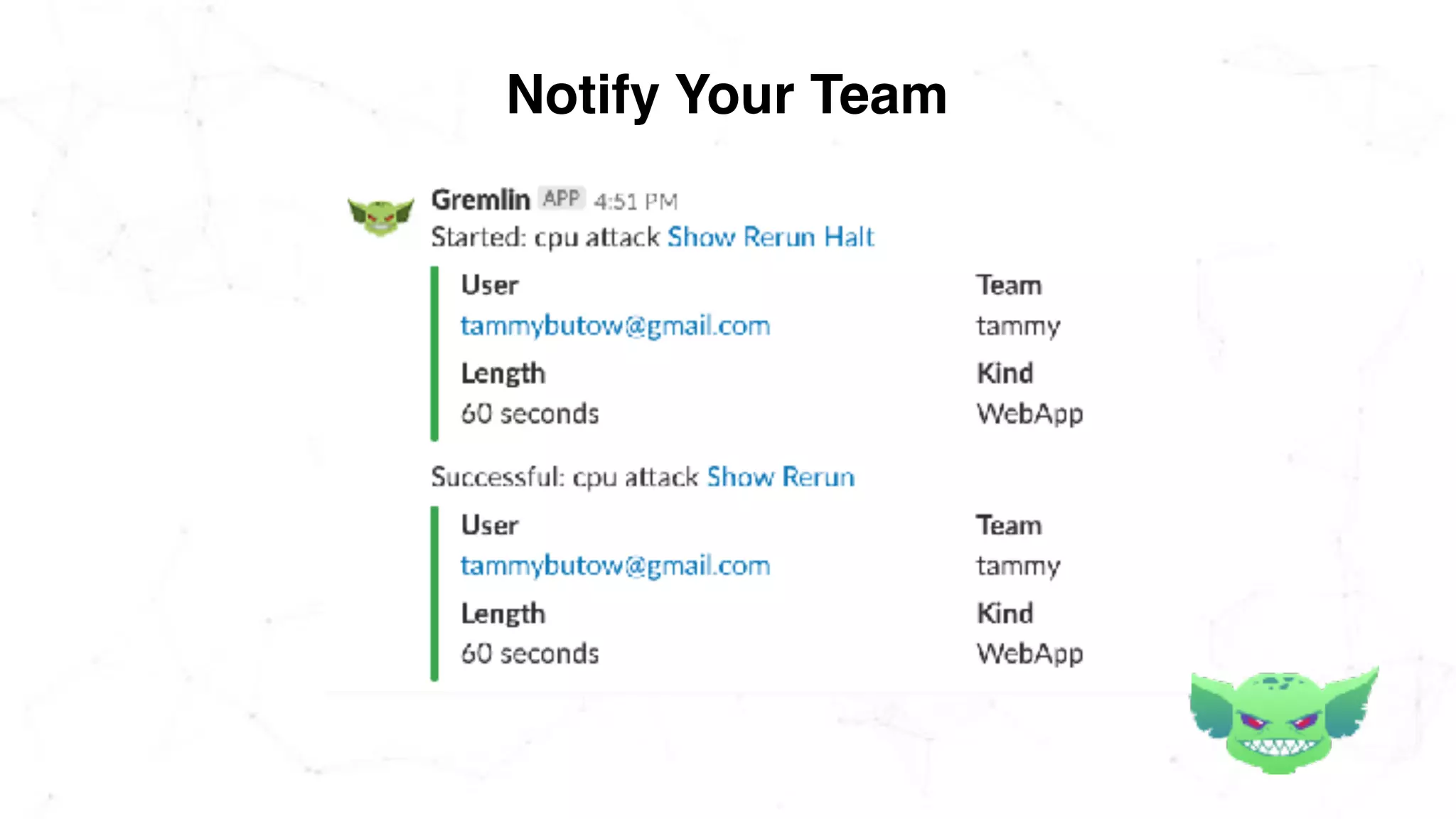

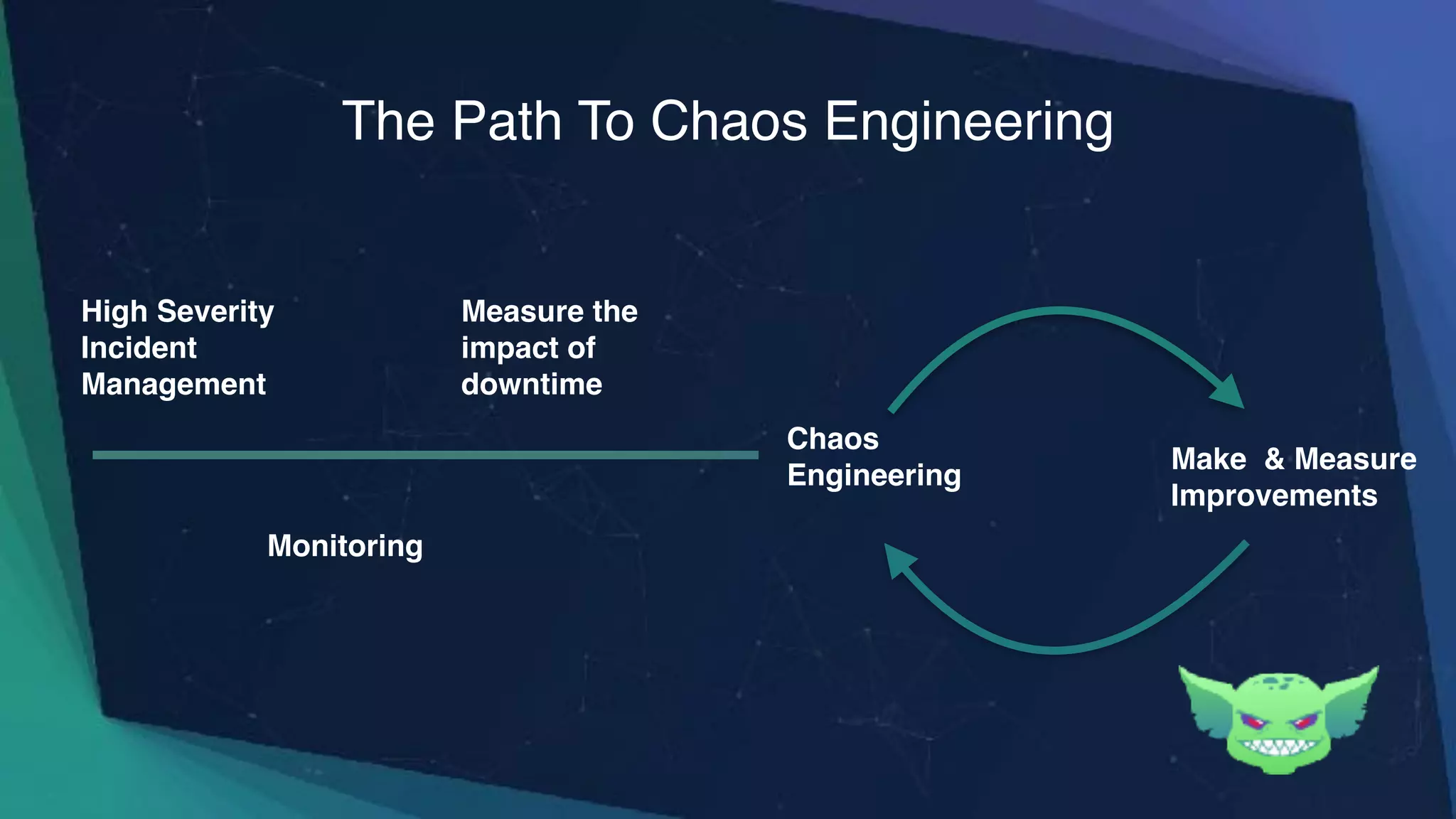
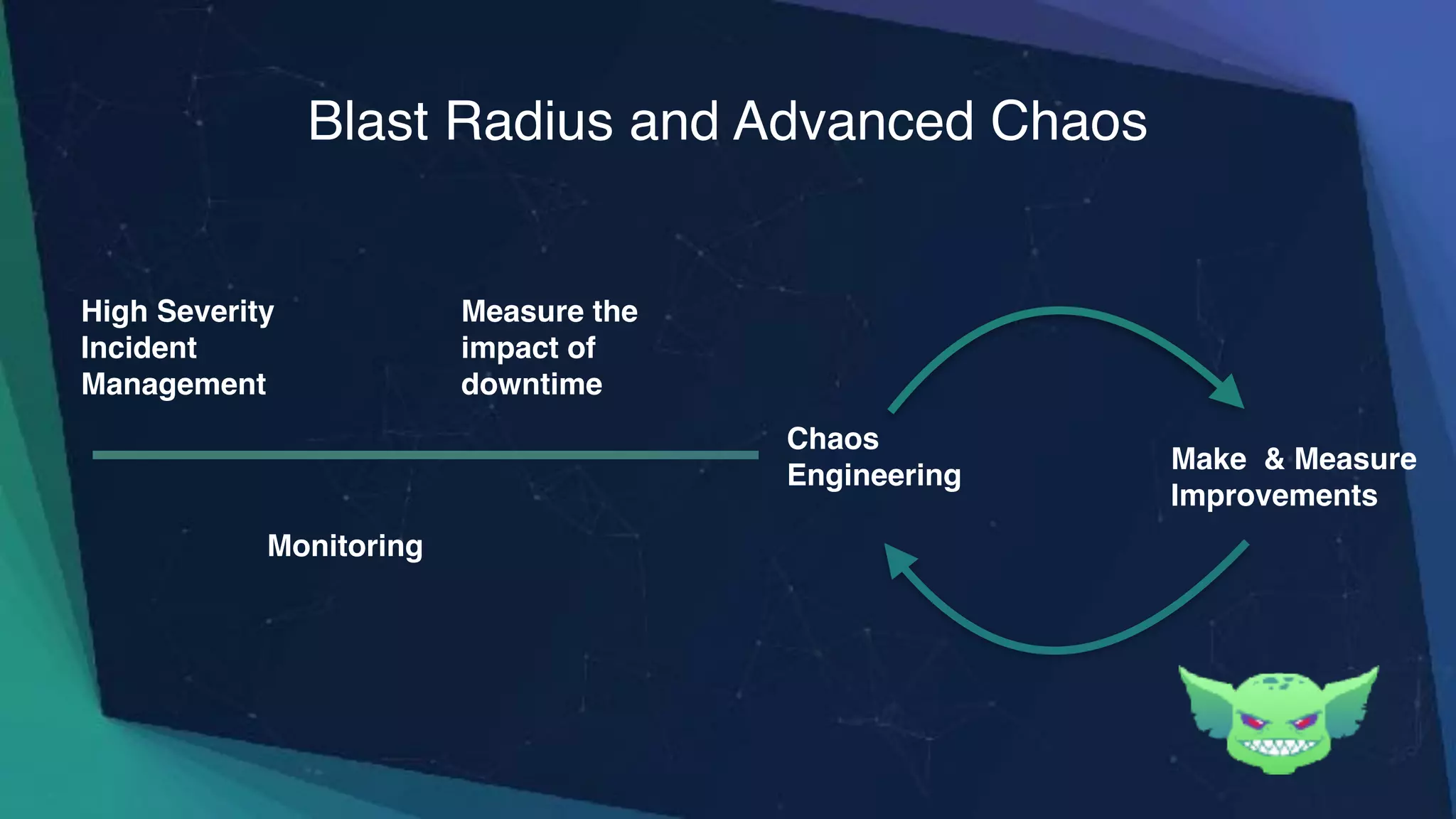









The document discusses the importance of chaos engineering in creating resilient systems that can maintain service despite failures. It outlines the prerequisites for implementing chaos engineering, such as high severity incident management and effective monitoring, and highlights the need for resilience across various industries including healthcare, finance, education, and environmental technology. The document emphasizes that chaos engineering involves planned experiments to expose weaknesses in systems, ultimately leading to more robust and reliable technology.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















