Download as PDF, PPTX



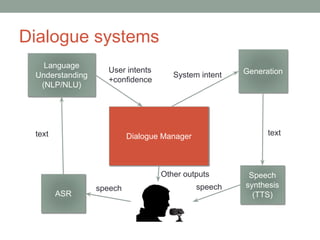
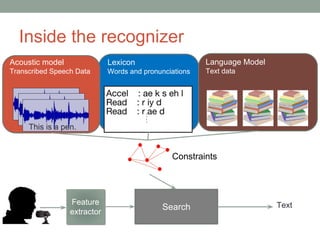
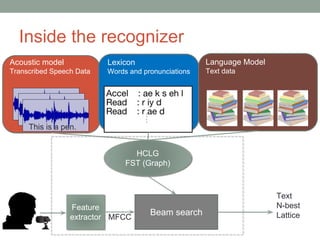
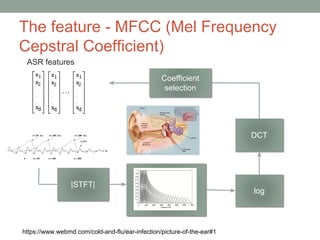
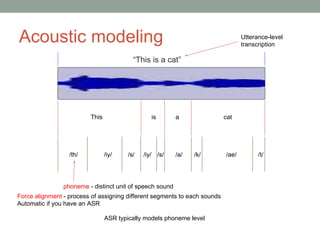

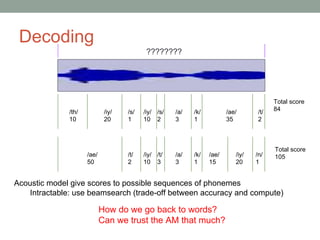


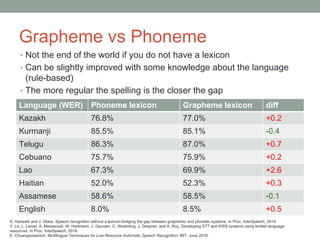



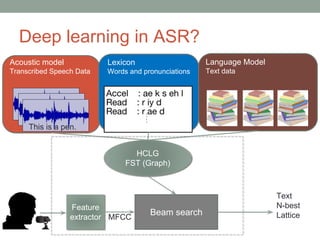
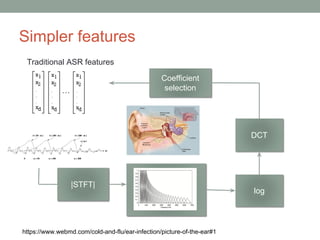



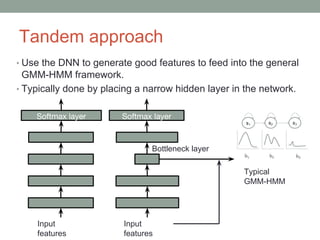

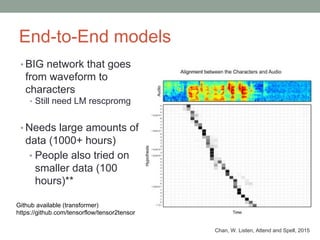
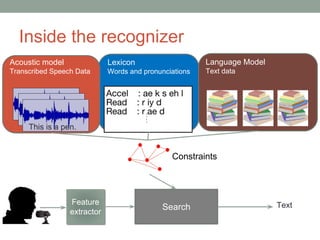
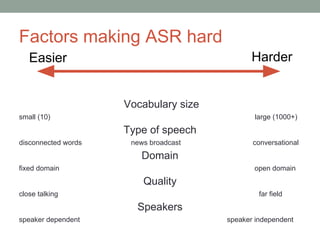




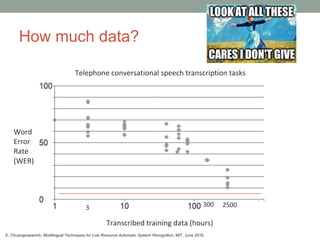





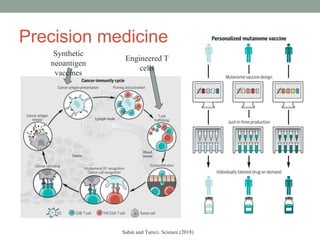
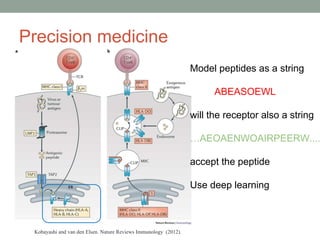

This document provides an overview of building an automatic speech recognition (ASR) engine. It discusses speech as a natural modality with high throughput that needs to account for errors in ASR output. It describes the components of a dialogue system including the ASR, natural language understanding, text-to-speech, and a dialogue manager. The document then discusses the components inside the recognizer including the acoustic model, language model, feature extraction using MFCC, and decoding using techniques like beam search. It also discusses topics like building the lexicon, acoustic modeling, and using deep learning approaches in ASR.



















![[NDC 2018] 신입 개발자가 알아야 할 윈도우 메모리릭 디버깅](https://cdn.slidesharecdn.com/ss_thumbnails/v7-180427162920-thumbnail.jpg?width=640&height=640&fit=bounds)



![[IGC 2017] 아마존 구승모 - 게임 엔진으로 서버 제작 및 운영까지](https://cdn.slidesharecdn.com/ss_thumbnails/igc2017-170904090322-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














