Download as PDF, PPTX








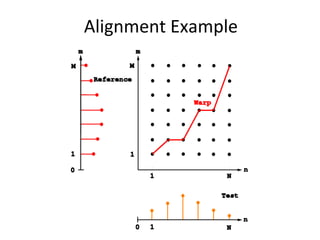

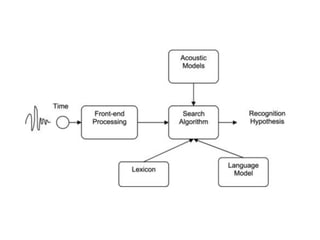

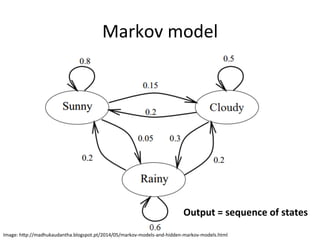
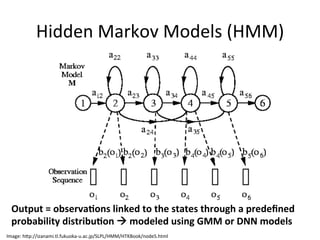
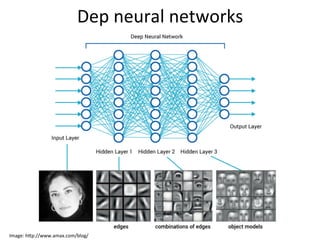
![DNN+evolu4on+
• We+started+to+use+mul4layer+perceptrons+
(MLP’s)+about+25+years+ago+[1]+
– Neural+networks+with+1+or+few+hidden+layers+
• Around+2010+G.+Hinton+and+S.+Bengio+
(separately)+proposed+methods+to+effec4vely+
train+many+hidden+layers+
– Machines+have+become+much+more+powerful+
– Lots+of+audio+data+with+transcrip4ons+areavailable++
[1]+“Merging+Mul4layer+perceptrons+and+Hidden+Markov+Models:+some+experiments+in+con4nuous+
speech+recogni4on”,+Herve+Bourlard+and+Nelson+Morgan,+Technical+report+ICSI,+1989+](https://image.slidesharecdn.com/kaldivoice-160209114905/85/Kaldi-voice-Your-personal-speech-recognition-server-using-open-source-code-23-320.jpg)



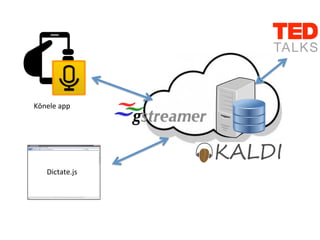



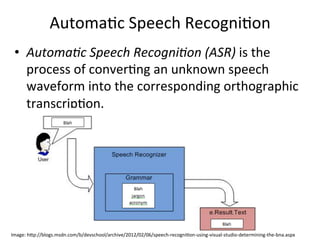
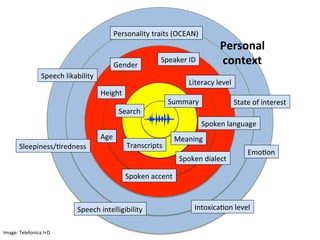
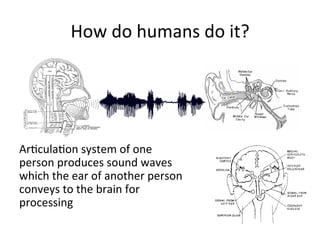
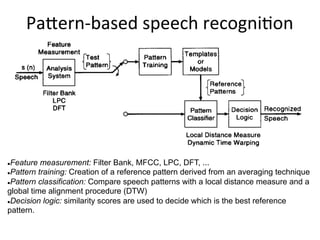
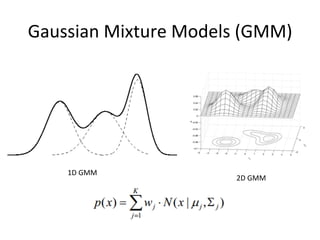
This document provides an overview of automatic speech recognition (ASR) technologies. It discusses the challenges of ASR processing including speaker and language variability as well as noise. It describes pattern-based and statistical approaches to ASR, including hidden Markov models, Gaussian mixture models, and deep neural networks. The document lists some open source and commercial ASR engines and provides steps to build an online ASR system using open source tools like Kaldi, Kaldi gstreamer server, and Dictate.js. It concludes with a live demo of a personal ASR system built with these tools.





































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)


![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)